几种常见的内部排序
排序是计算机程序设计中的一种重要操作,它的功能是将一个数据元素的任意序列,重新排列成一个按关键字有序的序列。
排序分为内部排序和外部排序。
随着计算机的内存不断扩大和查找算法的不断优化,外部排序用到地方不多了。
设待排序的关键字序列为{12,2,16,30,28,10,16*,20,6,18}
1:直接插入排序:它的基本操作是将一个记录插入到已经排好序的有序表中,从而得到一个新的,记录数增加1的有序表.
排序过程如图所示:

平均时间复杂度O(n^2) 最坏时间复杂度O(n^2) 空间复杂度O(1)
代码如下:
#include<iostream>#include<cstdio>#include<cstring>using namespace std;void Insertsort(int a[],int n){int i,j;for ( i=2;i<=n;i++) {if (a[i]<a[i-1]) {a[0]=a[i];//哨兵a[i]=a[i-1];for ( j=i-2;a[j]>a[0];j--)a[j+1]=a[j];}a[j+1]=a[0];}}int main(){int a[50],n;while (scanf("%d",&n)!=EOF) {for (int i=1;i<=n;i++) {scanf("%d",&a[i]);}Insertsort(a,n);for (int i=1;i<=n;i++) {printf("%d ",a[i]);}}return 0;}
2:折半插入排序:它的基本操作是将一个记录插入到已经排好序的有序表中(插入方法为二分插入),从而得到一个新的,记录数增加1的有序表.
排序过程图与直接插入排序过程图一样。
虽然折半插入排序减少了关键字的比较次数,但是移动次数没有改变,时间复杂度没有改变。
平均时间复杂度O(n^2) 最坏时间复杂度O(n^2) 空间复杂度O(1)
代码如下:
#include<iostream>#include<cstdio>#include<cstring>using namespace std;void BInsertsort(int a[],int n){int i,j;for ( i=2;i<=n;i++) {a[0]=a[i];int low=1,high=i-1;while (high>=low) {//二分查找int mid=(high+low)>>1;if (a[0]<a[mid]) high=mid-1;else low=mid+1;}for (j=i-1;j>=high+1;j--) a[j+1]=a[j];a[high+1]=a[0];}}int main(){int a[50],n;while (scanf("%d",&n)!=EOF) {for (int i=1;i<=n;i++) {scanf("%d",&a[i]);}BInsertsort(a,n);for (int i=1;i<=n;i++) {printf("%d ",a[i]);}}return 0;}
3:Shell排序(希尔排序又称缩小增量排序):先将整个待排序记录序列分割成为若干子序列分别进行插入排序,待整个序列中的记录“基本有序”时,再对全体记录进行一次插入排序。
我们选择增量为5 3 1
对于序列{12,2,16,30,28,10,16*,20,6,18},
增量为5时,我们排序的子序列为下标为1 6与2 7与3 8与4 9与5 10
即{12,10} {2,16*}{16,20}{30,6}{28,18}分别对这5个子序列进行排序为{10,12} {2,16*}{16,20}{6,30}{18,28}
则原序列变成{10,2,16,6,18,12,16*,20,30,28}
再选增量为3时:我们排序的子序列为1 4 7 10与2 5 8与3 6 9
依次把他们排序好后,原序列变成{6,2,12,10,18,16,16*,20,30,30,28}
我们发现大部分元素的位置关系已经都很对了,
最后我们选择增量为1(注意最后一定要选增量为1,即进行直接插入排序)
原序列变成{2,6,10,12,16,16*,18,20,18,30}有序了!
那么希尔排序优化在哪里了?
我们都知道直接插入排序很多时间都浪费在查找和移动元素上面(前面的折半插入排序优化了查找但是没有优化移动元素,依然为O(n^2)),不难发现经过前面俩趟希尔排序,我们的序列已经很有序了,换句话说就是离它应该待的位置很接近了,所以进行直接插入排序时,节省了很多时间!!!
还有一点:增量是随机选取的吗?很明显不是的,但是没有一个最优的增量选取,一般都是选取互质数,依次递减,最后选取增量为1.
希尔排序的时间复杂度是经过大量实验表明为O(n^(3/2)),好像没有数学证明。
代码如下:(增量选取5 3 1)
#include<iostream>#include<cstdio>#include<cstring>using namespace std;void Shellinsert(int a[],int k,int n){int i,j;for ( i=k+1;i<=n;i++) {if (a[i]<a[i-k]) {a[0]=a[i];for (j=i-k;j>0&&a[0]<a[j];j-=k) a[j+k]=a[j];a[j+k]=a[0];}}}void Shellsort(int a[],int dlbt[],int t,int n){for (int i=1;i<=t;i++) {Shellinsert(a,dlbt[i],n);}}int main(){int a[50],n,dlbt[10];while (scanf("%d",&n)!=EOF) {for (int i=1;i<=n;i++) {scanf("%d",&a[i]);}dlbt[3]=5,dlbt[2]=3,dlbt[1]=1;Shellsort(a,dlbt,3,n);for (int i=1;i<=n;i++) {printf("%d ",a[i]);}}return 0;}
4:快速排序:通过一趟排序将待排记录分割成独立的俩部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这俩部分记录继续继续进行排序,已到达整个序列有序
为了方便初始关键字(也可以称为轴)一般选取序列第一个元素。
俩个指针一个最左边,一个最右边。最左边的往右移,遇到比对称轴大的就停下来与另外一个指针指向的地方交换,最右边的往左移,遇到比对称轴小的就停下来另外一个指针指向的地方交换。
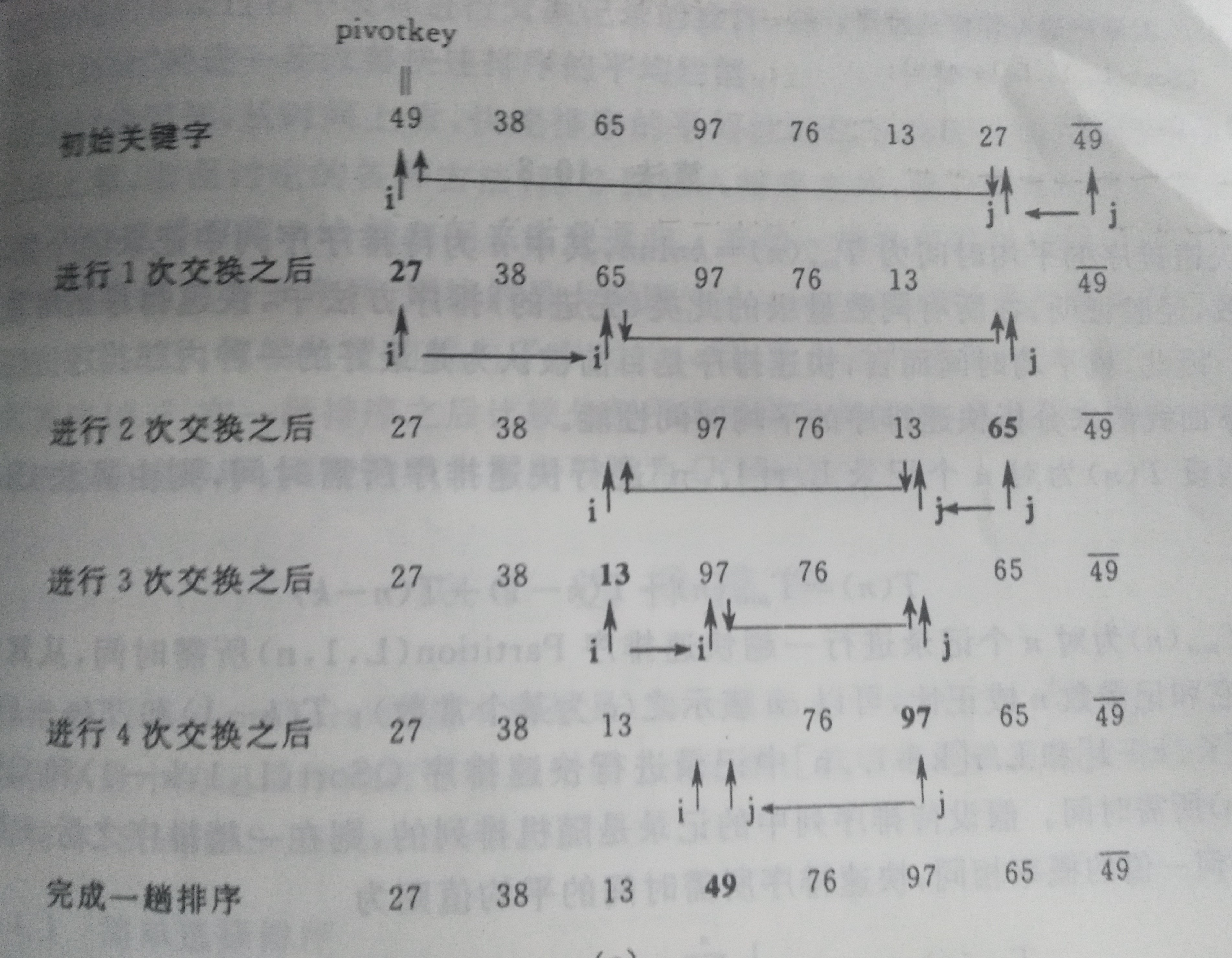
不难发现每一趟快速排序就是把关键字(对称轴)放在对应位置,然后对称轴左边比对称轴小,右边比对称轴大。
排序过程如图所示
平均时间复杂度O(nlogn) 最坏时间复杂度O(n^2) 空间复杂度O(logn)
代码如下:
#include<iostream>#include<cstdio>#include<cstring>using namespace std;int Partition(int a[],int low,int high){a[0]=a[low];int mid=a[low];while (low<high) {while (low<high&&a[high]>=mid) high--;a[low]=a[high];while (low<high&&a[low]<=mid) low++;a[high]=a[low];}a[low]=a[0];return low;}void Qsort(int a[],int low,int high){if (high>low) {int mid=Partition(a,low,high);Qsort(a,low,mid-1);Qsort(a,mid+1,high);}}int main(){int a[50],n;while (scanf("%d",&n)!=EOF) {for (int i=1;i<=n;i++) {scanf("%d",&a[i]);}Qsort(a,1,n);for (int i=1;i<=n;i++) {printf("%d ",a[i]);}}return 0;}
5:堆排序:利用堆结构的一种树形选择排序,每次取堆顶,然后把剩下的n-1个元素维护成堆。反复操作得到一个有序序列。
首先堆的定义如下:
n个元素的序列{k1,k2,k3,,,kn}当且仅当满足以下关系时,称为堆。
ki<=k2*i 或 ki>=k2*i
ki<=k2*i+1 ki>=k2*i+1
简单的来说,如果把堆看成树形结构的话,那么它是一棵完全二叉树且每个节点比他的俩个儿子都大(称为大顶堆)或者都小(称为小顶堆)。
堆排序的过程就不难理解了,因为根节点肯定是最大或者最小,每次把根节点移出,然后把剩下的元素维护成堆,重复操作。有点像冒泡排序对吧!但是它比冒泡排序要快很多。冒泡排序是将一个元素与其他的未排序的所有元素都进行比较了,很浪费时间,而堆排序不一样,因为堆的特殊性,例如大顶堆,节点总比儿子节点大,把根节点与最后一个元素交换后,我们只需要在儿子节点当中找比它大的最大儿子节点,找到了就替换,一直到儿子节点比小。log(n)的深度。
堆排序需要解决俩个问题1:如何由无序序列构成堆2:取堆顶后,如果调整剩余元素成为堆(以大顶堆为例)
1:我们从序列lenth/2开始往前面调整,把每个节点i与它们的儿子节点i*2 i*2+1比较,如果儿子节点比它大就互换,然后重复操作。
平均时间复杂度O(nlogn) 最坏时间复杂度O(nlogn) 空间复杂度O(1)
代码如下:
#include<iostream>#include<cstdio>#include<cstring>using namespace std;void Heapadjust(int a[],int s,int n){int res=a[s];for (int i=s*2;i<=n;i*=2) {if (i<n&&a[i]<a[i+1]) i++;if (res>a[i]) break;a[s]=a[i];s=i;}a[s]=res;}void Heapsort(int a[],int n){for (int i=n/2;i>0;i--) {Heapadjust(a,i,n);}for (int i=n;i>1;i--) {swap(a[i],a[1]);Heapadjust(a,1,i-1);}}int main(){int a[50],n;while (scanf("%d",&n)!=EOF) {for (int i=1;i<=n;i++) {scanf("%d",&a[i]);}Heapsort(a,n);for (int i=1;i<=n;i++) {printf("%d ",a[i]);}}return 0;}
6:2-路归并排序:假设初始序列含有n个记录,则可以看成n个有序的子序列,每个序列的长度为1,然后俩俩归并,得到[n/2]个长度为2或1的有序序列,再俩俩归并,如此重复,直到得到一个长度为n的有序序列.
归并排序过程如图所示:
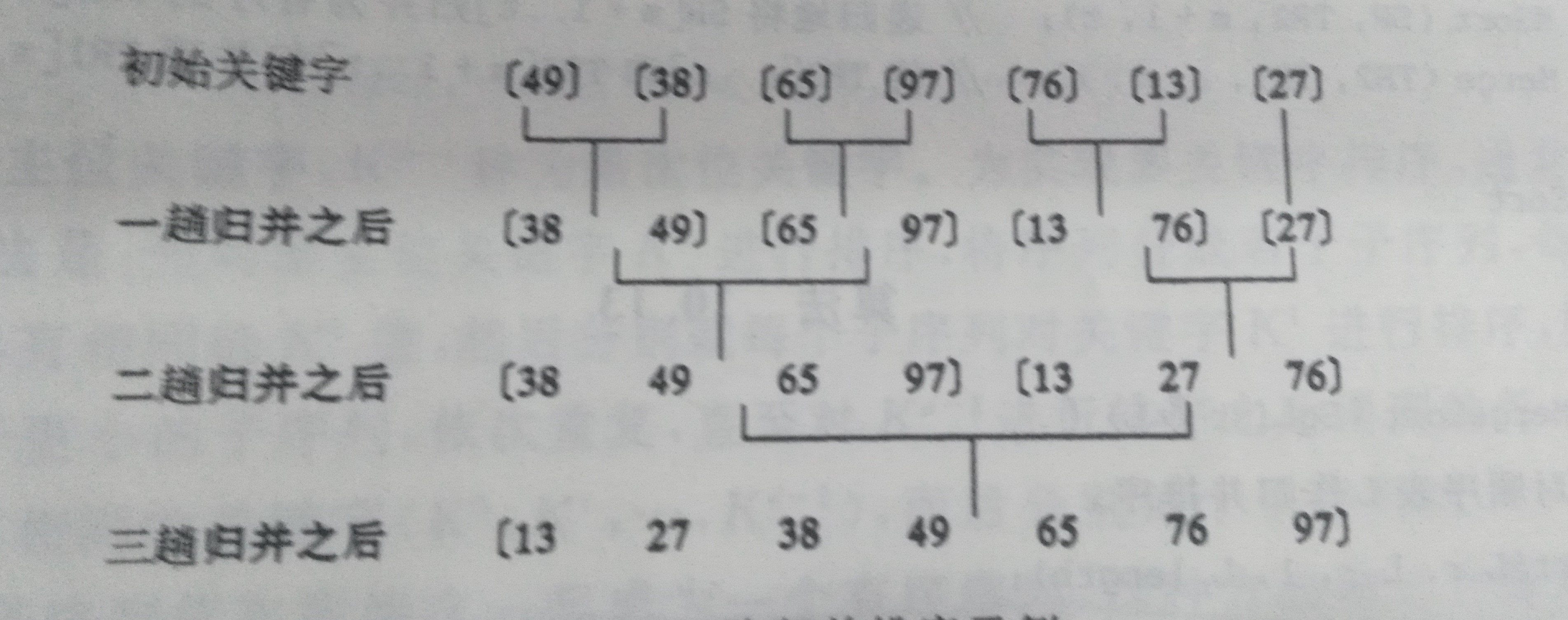
归并排序的思想是分治,大化小,小归并成大的。
平均时间复杂度O(nlogn),最坏时间复杂度O(nlogn),空间复杂度O(n)
代码如下:
#include<iostream>#include<cstdio>#include<cstring>using namespace std;void Merge(int a[],int b[],int i,int m,int n){int j,k;for (j=m+1,k=i;i<=m&&j<=n;k++) {if (a[i]<=a[j]) b[k]=a[i++];else b[k]=a[j++];}while (i<=m) b[k++]=a[i++];while (j<=n) b[k++]=a[j++];}void Mergesort(int a[],int b[],int s,int e){if (s==e) b[s]=a[s];else {int m=(s+e)/2;int *p=new int[100];Mergesort(a,p,s,m);Mergesort(a,p,m+1,e);Merge(p,b,s,m,e);delete []p;}}int main(){int a[50],n;while (scanf("%d",&n)!=EOF) {for (int i=1;i<=n;i++) {scanf("%d",&a[i]);}Mergesort(a,a,1,n);for (int i=1;i<=n;i++) {printf("%d ",a[i]);}}return 0;}

























盒子模型,边框,内外边距,盒子模型布局,ps基本操作,列表样式,圆角边框,盒子阴影")








还没有评论,来说两句吧...