python3实现机器学习--KNN算法详解
首先我们通过一个简单的数据集来了解一下KNN算法。
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as npdata_x=
[[3.342342, 2.3231231], [3.12122, 1.782342], [1.343423, 3.362342], [3.5823423, 4.67342], [2.2834234, 2.866345], [7.42123123, 4.696345], [5.742434, 3.63234], [9.173423, 2.5152342], [7.7952342, 3.5212412], [7.9352342, 0.79523421]]
data_y=[0,0,0,0,0,1,1,1,1,1]
data_x数据集是绘制图像需要的几个基本点,data_y是这些点所在的不同类别,分别是0,1。
接下来我们通过matplotlib来展示这些点的分布情况。
#这是实际操作的点X_train=np.array(data_x)Y_train=np.array(data_y)plt.scatter(X_train[Y_train==0,0],X_train[Y_train==0,1],color="g")plt.scatter(X_train[Y_train==1,0],X_train[Y_train==1,1],color="r")plt.show()
结果显示如下图: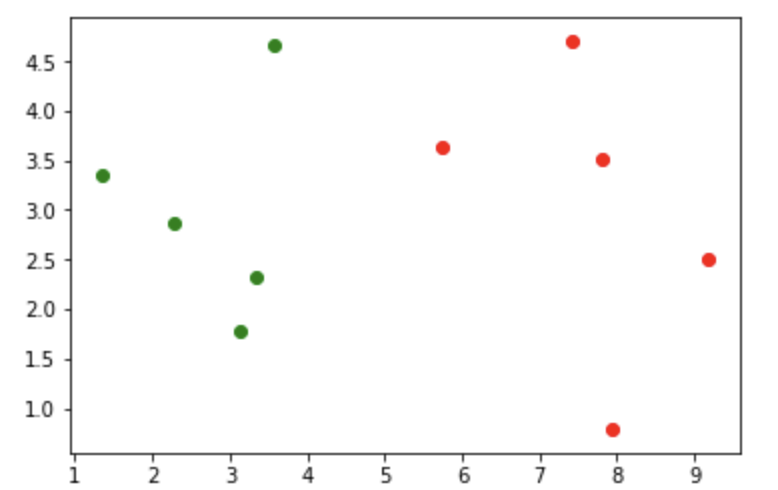
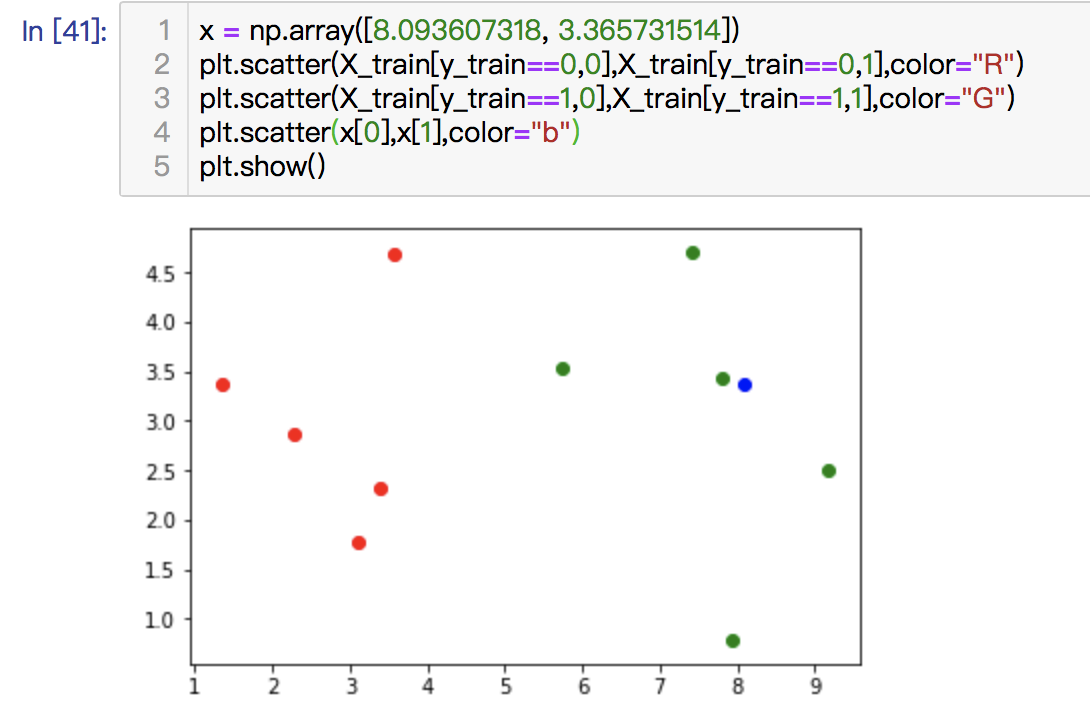
我们可以清楚的看到,红色和绿色的两个不同类别分布情况,接下来我们又得到了另一个点,但是我们不知道他是属于哪一个类别,这时我们就需要将它也在图上表示出来,代码如下:
x=np.array([8.342342,3.353423])plt.scatter(X_train[Y_train==0,0],X_train[Y_train==0,1],color="g")plt.scatter(X_train[Y_train==1,0],X_train[Y_train==1,1],color="r")plt.scatter(x[0],x[1],color="b")plt.show()
我们将新增的这个点用蓝色表示,结果如下: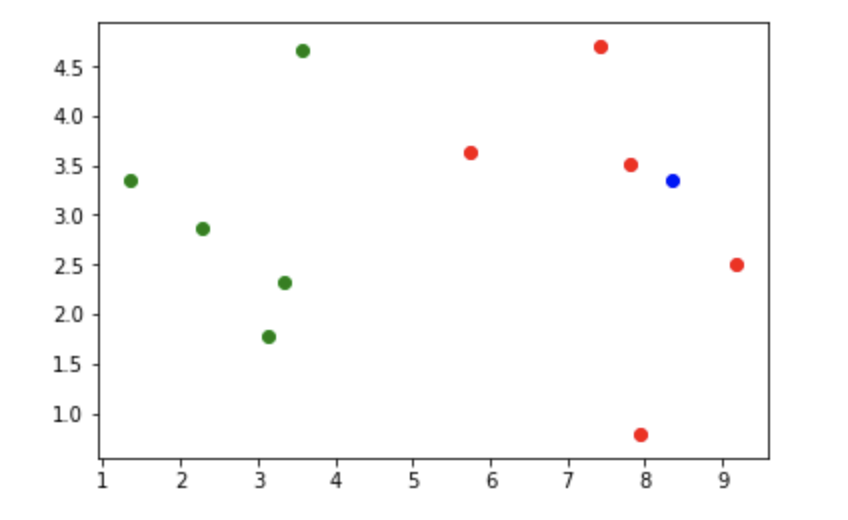
我们可以清楚的再图上看到他的位置,和红色部分靠近。
* 因为KNN算法是根据相近的几个点的位置来判断该点是什么类别,所以我们可以知道,这个点是属于红色的类别。
* 思路:
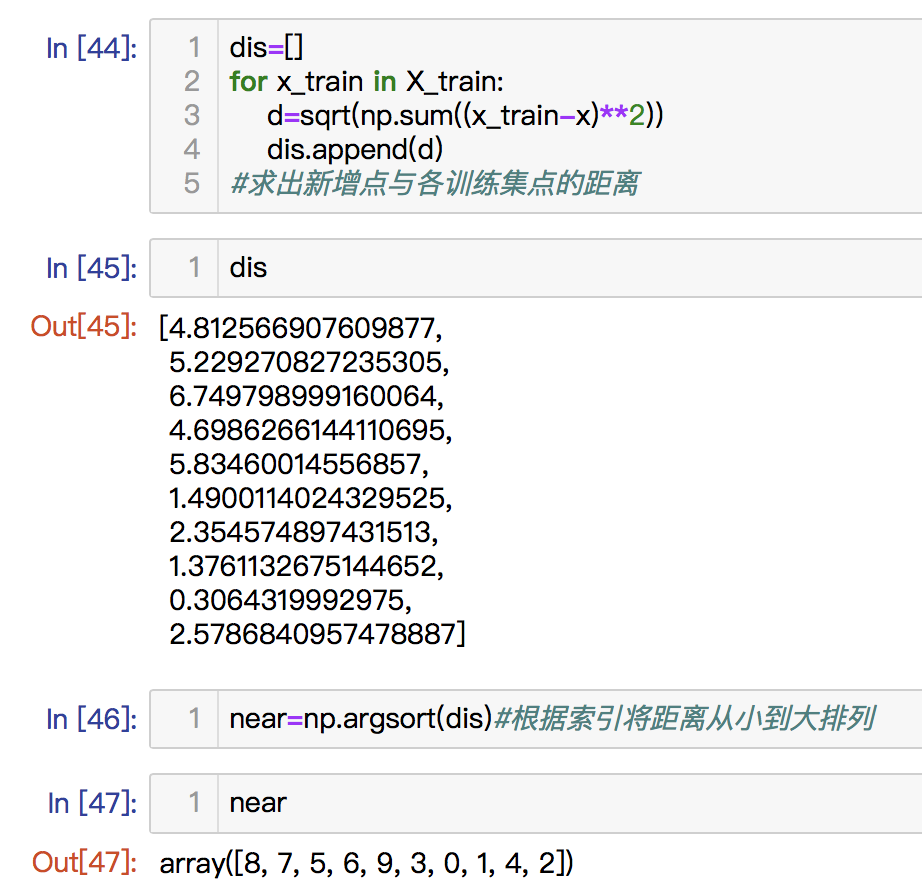
1.计算出新的那个点和原来那些点的距离
from math import sqrtdis=[]for x_train in X_train:d=sqrt(np.sum((x_train-x)**2))dis.append(d)结果:dis:[5.105048274398589,5.452376587089798,6.998924682915369,4.939634523323471,6.078465232236668,1.6284607912670155,2.6148262468762624,1.1803626955332156,0.5722673265809259,2.5903796335870357]
或直接使用:
dis=[sqrt(np.sum((x_train-x)**2)) for x_train in X_train]
结果都是一样的,我们得到了新的点和原来点的距离
2.接下来我们要得到与新的点距离最近的几个点,我们要对生成的dis里面的数据进行排序,得到这些点的位置,我们可以得到最近的点的索引位置,使用numpy内置的argsort方法。
将排序结果存在short里面:
short=np.argsort(dis)结果:array([8, 7, 5, 9, 6, 3, 0, 1, 4, 2])
可以知道,最近的点是索引为8的点,其次是7.
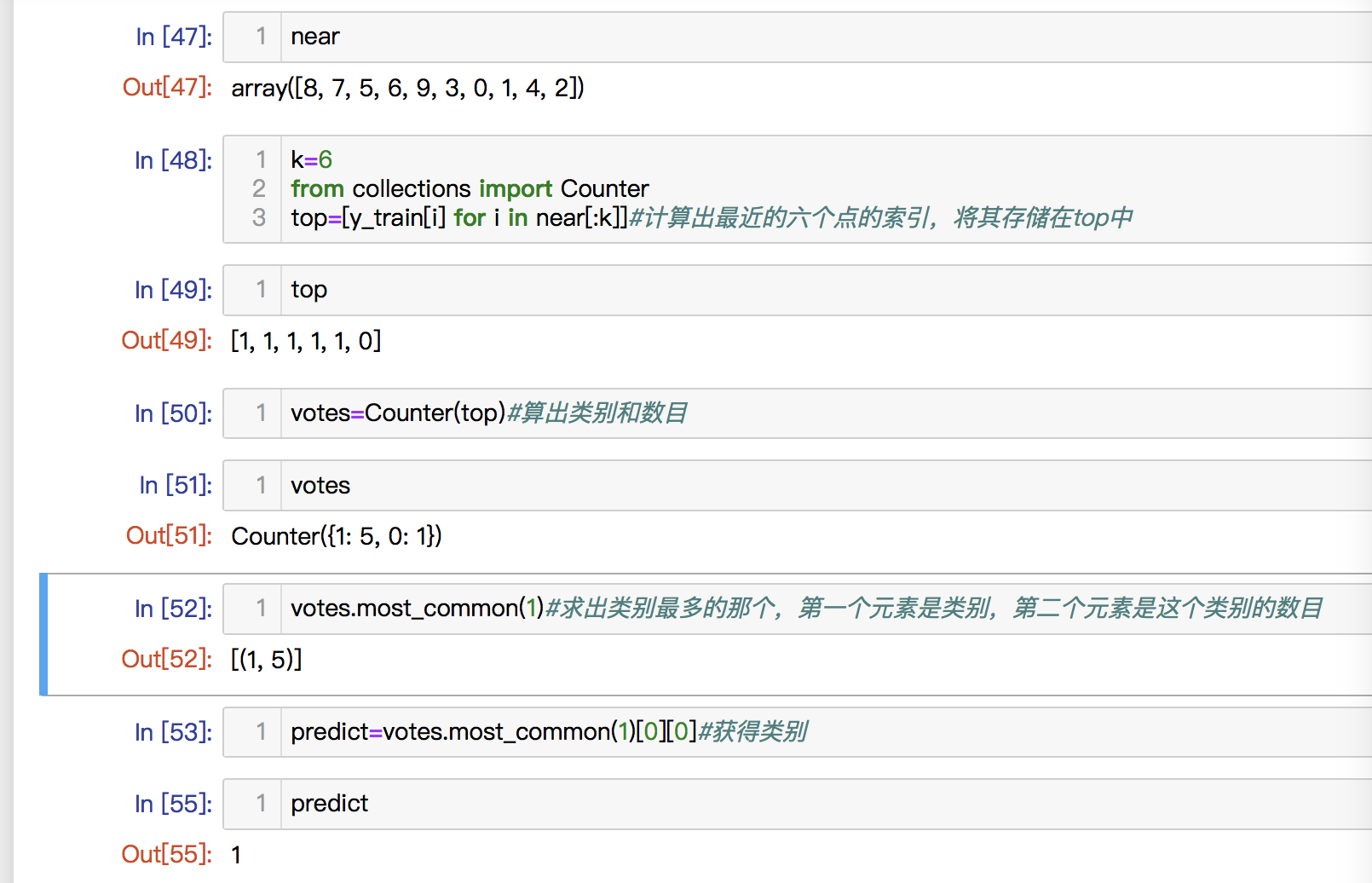
3.我们还要得到这些距离最近的几个点属于哪些类别。我们设置k为6,看前六个点属于哪些类别,将y_train中的数据在short中遍历,看哪些符合条件。
topK_y=[y_train[i] for i in short[:k]]
结果:[1, 1, 1, 1, 1, 0]
所以,最近的五个点为类别1,还有一个类别0.
或者我们计算结果:
from collections import CounterCounter(topK_y)#计算出现的频次结果:Counter({1: 5, 0: 1})votes=Counter(topK_y)#存放结果votes.most_common(1)结果:[(1, 5)]#最多的为1,有五个
因为我们要获取的是类别,所以通过[0][0]获取。
pre=votes.most_common(1)[0][0]结果:1
因此我们就得到了最近的点的类别是1,这个点就是类别1.
代码截图: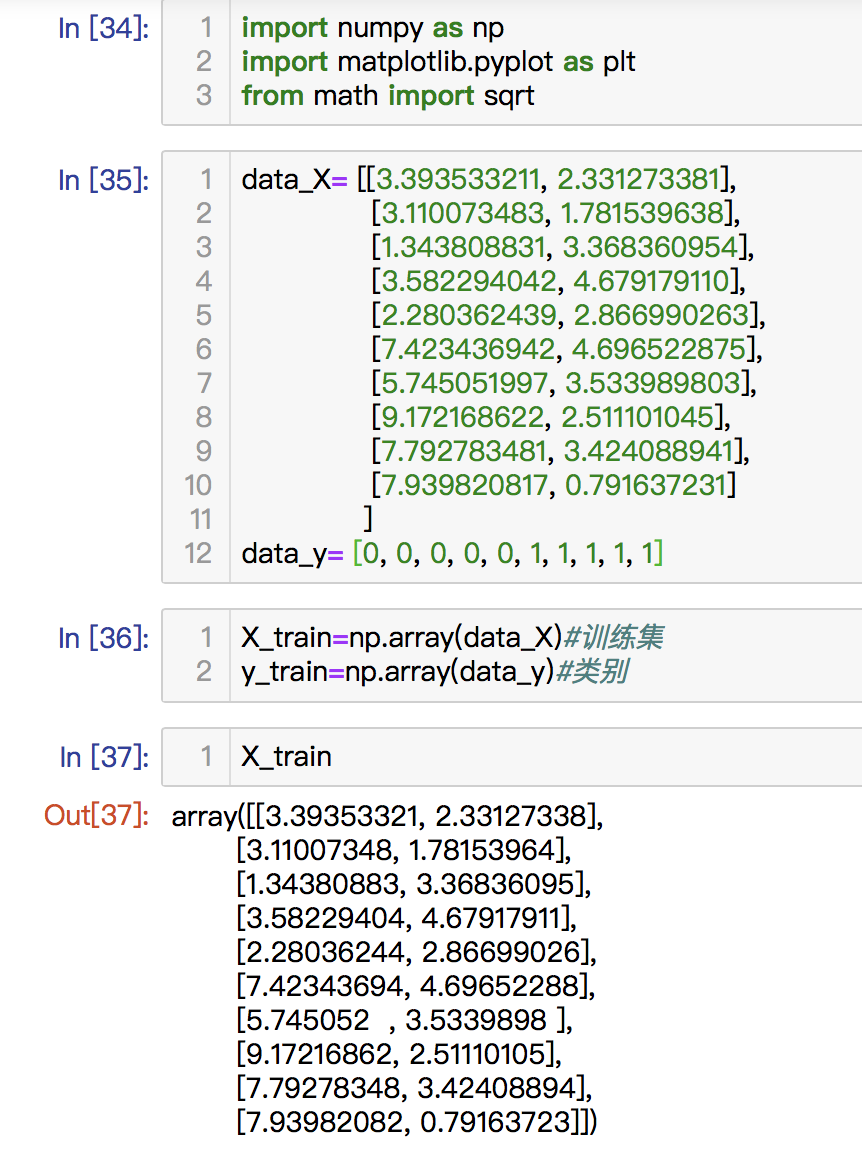




























还没有评论,来说两句吧...