基于Lire库搜索相似图片
什么是Lire
LIRE(Lucene Image REtrieval)提供一种的简单方式来创建基于图像特性的Lucene索引。利用该索引就能够构建一个基于内容的图像检索(content- based image retrieval,CBIR)系统,来搜索相似的图像。LIRE使用的特性都取自MPEG-7标准: ScalableColor、ColorLayout、EdgeHistogram。此外该类库还提供一个搜索该索引的方法。
下面直接介绍代码实现
代码结构
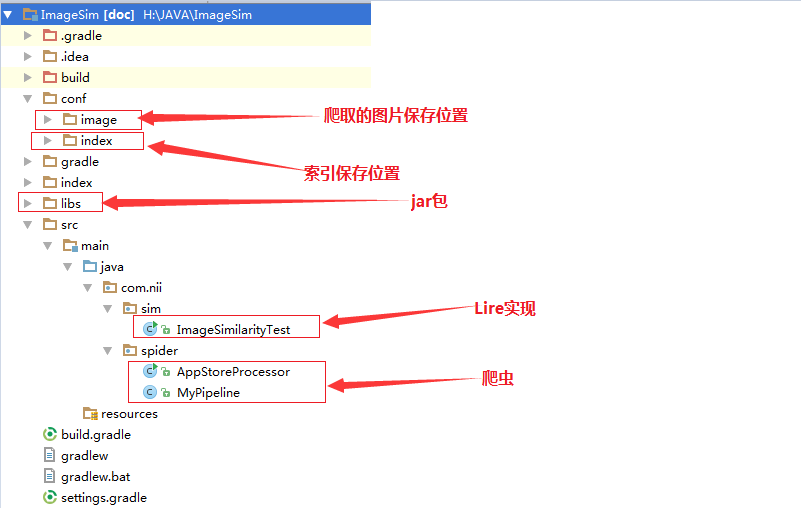
Gradle依赖为
dependencies {compile fileTree(dir: 'libs', include: ['*.jar'])testCompile group: 'junit', name: 'junit', version: '4.11'compile group: 'us.codecraft', name: 'webmagic-core', version: '0.7.3'// https://mvnrepository.com/artifact/us.codecraft/webmagic-extensioncompile group: 'us.codecraft', name: 'webmagic-extension', version: '0.7.3'compile group: 'commons-io', name: 'commons-io', version: '2.6'compile group: 'org.apache.lucene', name: 'lucene-core', version: '6.4.0'compile group: 'org.apache.lucene', name: 'lucene-analyzers-common', version: '6.4.0'compile group: 'org.apache.lucene', name: 'lucene-queryparser', version: '6.4.0'// https://mvnrepository.com/artifact/org.apache.httpcomponents/httpclientcompile group: 'org.apache.httpcomponents', name: 'httpclient', version: '4.5.6'}
爬取图片样本
使用WebMagic爬虫爬取华为应用市场应用的图标当做样本,WebMagic使用请看《WebMagic爬取应用市场应用信息》
import us.codecraft.webmagic.Page;import us.codecraft.webmagic.Site;import us.codecraft.webmagic.Spider;import us.codecraft.webmagic.processor.PageProcessor;import us.codecraft.webmagic.selector.Selectable;/*** @author wzj* @create 2018-07-17 22:06**/public class AppStoreProcessor implements PageProcessor{// 部分一:抓取网站的相关配置,包括编码、抓取间隔、重试次数等private Site site = Site.me().setRetryTimes(5).setSleepTime(1000);public void process(Page page){//获取名称String name = page.getHtml().xpath("//p/span[@class='title']/text()").toString();page.putField("appName",name );String downloadIconUrl = page.getHtml().xpath("//img[@class='app-ico']/@src").toString();page.putField("downloadIconUrl",downloadIconUrl );if (name == null || downloadIconUrl == null){//skip this pagepage.setSkip(true);}//获取页面其他链接Selectable links = page.getHtml().links();page.addTargetRequests(links.regex("(http://app.hicloud.com/app/C\\d+)").all());}public Site getSite(){return site;}public static void main(String[] args){Spider.create(new AppStoreProcessor()).addUrl("http://app.hicloud.com").addPipeline(new MyPipeline()).thread(20).run();}}
上面代码提取出来每个页面的图标下载URL,自定义了Pipeline来保存应用图标,使用Apache的HttpClient包来下载图片
import org.apache.http.HttpEntity;import org.apache.http.client.methods.CloseableHttpResponse;import org.apache.http.client.methods.HttpGet;import org.apache.http.impl.client.CloseableHttpClient;import org.apache.http.impl.client.HttpClients;import us.codecraft.webmagic.ResultItems;import us.codecraft.webmagic.Task;import us.codecraft.webmagic.pipeline.Pipeline;import java.io.*;import java.nio.file.Paths;/*** @author wzj* @create 2018-07-17 22:16**/public class MyPipeline implements Pipeline{/*** 保存文件的路径,保存到资源目录下*/private static final String saveDir = MyPipeline.class.getResource("/conf/image").getPath();/** 统计数目*/private int count = 1;/*** Process extracted results.** @param resultItems resultItems* @param task task*/public void process(ResultItems resultItems, Task task){String appName = resultItems.get("appName");String downloadIconUrl = resultItems.get("downloadIconUrl");try{saveIcon(downloadIconUrl,appName);}catch (IOException e){e.printStackTrace();}System.out.println(String.valueOf(count++) + " " + appName);}public void saveIcon(String downloadUrl,String appName) throws IOException{CloseableHttpClient client = HttpClients.createDefault();HttpGet get = new HttpGet(downloadUrl);CloseableHttpResponse response = client.execute(get);HttpEntity entity = response.getEntity();InputStream input = entity.getContent();BufferedInputStream bufferedInput = new BufferedInputStream(input);File file = Paths.get(saveDir,appName + ".png").toFile();FileOutputStream output = new FileOutputStream(file);byte[] imgByte = new byte[1024 * 2];int len = 0;while ((len = bufferedInput.read(imgByte, 0, imgByte.length)) != -1){output.write(imgByte, 0, len);}input.close();output.close();}}
注意:可能华为应用市场有反爬虫机制,每次只能爬取1000个左右的图标。
Lire测试代码
注意:类中的IMAGE_PATH指定图片路径,INDEX_PATH指定索引保存位置,代码拷贝之后,需要修改路径。
indexImages方法是建立索引,searchSimilarityImage方法是查询最相似的图片,并把相似度打印出来。
GenericFastImageSearcher方法的第一个参数是指定搜索Top相似的图片,我设置的为5,就找出最相似的5个图片。
ImageSearcher searcher = new GenericFastImageSearcher(5, CEDD.class);
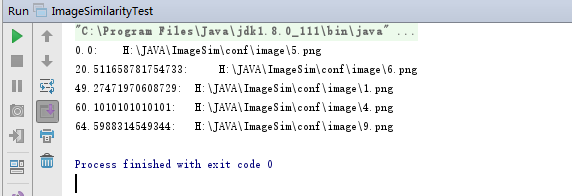
图片越相似,给出的相似值越小,如果为1.0说明是原图片,下面是完整代码
import net.semanticmetadata.lire.builders.DocumentBuilder;import net.semanticmetadata.lire.builders.GlobalDocumentBuilder;import net.semanticmetadata.lire.imageanalysis.features.global.CEDD;import net.semanticmetadata.lire.searchers.GenericFastImageSearcher;import net.semanticmetadata.lire.searchers.ImageSearchHits;import net.semanticmetadata.lire.searchers.ImageSearcher;import net.semanticmetadata.lire.utils.FileUtils;import org.apache.lucene.analysis.core.WhitespaceAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.index.DirectoryReader;import org.apache.lucene.index.IndexReader;import org.apache.lucene.index.IndexWriter;import org.apache.lucene.index.IndexWriterConfig;import org.apache.lucene.store.FSDirectory;import javax.imageio.ImageIO;import java.awt.image.BufferedImage;import java.io.FileInputStream;import java.io.IOException;import java.nio.file.Paths;import java.util.Iterator;import java.util.List;/*** @author wzj* @create 2018-07-22 11:16**/public class ImageSimilarityTest{/*** 图片保存的路径*/private static final String IMAGE_PATH = "H:\\JAVA\\ImageSim\\conf\\image";/*** 索引保存目录*/private static final String INDEX_PATH = "H:\\JAVA\\ImageSim\\conf\\index";public static void main(String[] args) throws IOException{//indexImages();searchSimilarityImage();}private static void indexImages() throws IOException{List<String> images = FileUtils.getAllImages(Paths.get(IMAGE_PATH).toFile(), true);GlobalDocumentBuilder globalDocumentBuilder = new GlobalDocumentBuilder(false, false);globalDocumentBuilder.addExtractor(CEDD.class);IndexWriterConfig conf = new IndexWriterConfig(new WhitespaceAnalyzer());IndexWriter indexWriter = new IndexWriter(FSDirectory.open(Paths.get(INDEX_PATH)), conf);for (Iterator<String> it = images.iterator(); it.hasNext(); ){String imageFilePath = it.next();System.out.println("Indexing " + imageFilePath);BufferedImage img = ImageIO.read(new FileInputStream(imageFilePath));Document document = globalDocumentBuilder.createDocument(img, imageFilePath);indexWriter.addDocument(document);}indexWriter.close();System.out.println("Create index image successful.");}private static void searchSimilarityImage() throws IOException{IndexReader ir = DirectoryReader.open(FSDirectory.open(Paths.get(INDEX_PATH)));ImageSearcher searcher = new GenericFastImageSearcher(5, CEDD.class);String inputImagePath = "H:\\JAVA\\ImageSim\\conf\\image\\5.png";BufferedImage img = ImageIO.read(Paths.get(inputImagePath).toFile());ImageSearchHits hits = searcher.search(img, ir);for (int i = 0; i < hits.length(); i++){String fileName = ir.document(hits.documentID(i)).getValues(DocumentBuilder.FIELD_NAME_IDENTIFIER)[0];System.out.println(hits.score(i) + ": \t" + fileName);}}}
测试结果如下:
源码下载
https://download.csdn.net/download/u010889616/10557157

























![[亲测]java.sql.SQLException: Parameter number X is not an OUT parameter](https://image.dandelioncloud.cn/dist/img/NoSlightly.png "[亲测]java.sql.SQLException: Parameter number X is not an OUT parameter")


还没有评论,来说两句吧...