大数据预测CSDN2018博客之星评选结果
大数据预测CSDN2018博客之星评选结果
闲话不多说,我们直接用数据说话。(因为绝大多数同学都只是关心一下结果,后面再给大家演示数据是怎么得到的)
按照CSDN的要求:
- 自荐方式如下:在评论中放上您的CSDN博客地址、并进行简要说明。
- 候选人自荐截止时间为2018年12月11日中午12点。
则目前为止自荐参与人数807。(是不是很意外,这么火的CSDN报名参加人数居然这么少)
那么这807人当中的,原创/粉丝/喜欢/评论/等级/访问/积分/排名 等相关数据呢。
| 指标 | 最大值 | 最小值 | 平均值 | 总计 | 最佳用户列表 |
|---|---|---|---|---|---|
| 原创 | 1544 | 2 | 135 | 109474 | [‘u012965373’] |
| 粉丝 | 5933 | 0 | 171 | 138388 | [‘testcs_dn’] |
| 喜欢 | 3806 | 0 | 93 | 75747 | [‘testcs_dn’] |
| 评论 | 4261 | 0 | 97 | 78938 | [‘huyuyang6688’] |
| 等级 | 9 | 1 | 4 | 3441 | [‘aerchi’, ‘testcs_dn’] |
| 访问 | 13687181 | 43 | 300708 | 242671946 | [‘testcs_dn’] |
| 积分 | 83564 | 1 | 3826 | 3087607 | [‘testcs_dn’] |
| 排名 | 2311072 | 27 | 84523 | 68210139 | [‘testcs_dn’] |
由上面的表格我们可以得出的结论。
- 最能写的桂冠由
u012965373夺走,并且拿下原创文章1544傲人成绩。 - 评论数最多的桂冠由
huyuyang6688夺走,并且评论总次数达到4261。 - 其他各项指标,包括最佳排名(
27),最佳收藏(3806),最高访问(13687181),最高积分(83564),最高等级(9),最多粉丝(5933)均由testcs_dn砍下,这个成绩可是相当恐怖的。
OK,接下来,我们再看一组比较有意思的数据。
首先,报名博客之星评选的807作者中,博客等级分布如下:
| 等级 | 人数 |
|---|---|
| 9 | 2 |
| 8 | 9 |
| 7 | 59 |
| 6 | 97 |
| 5 | 197 |
| 4 | 168 |
| 3 | 156 |
| 2 | 112 |
| 1 | 7 |
即报名参加的作者中:
- 最高等级达到了
9级,由testcs_dn,aerchi2位拿下。 - 最低等级为
1级,有7位作者参与报名。 - 博客等级达到
8级的也有9位作者参与。 - 大多数的报名参与者等级在
3,4,53个等级
再看看勋章获取情况:
| 勋章 | 人数 |
|---|---|
| 持之以恒 | 674 |
| 微软mvp | 1 |
| 博客之星 | 2 |
| 博客专家 | 103 |
| 专栏达人 | 330 |
| 1024超级勋章 | 3 |
| 1024活动勋章 | 233 |
即报名参加的作者中:
2位作者已经拿过博客之星勋章,并且发起了再次冲击。3位作者拿到了1024超级勋章勋章,这意味着有超过3位报名作者的原创文章超过了1024篇,堪称超级写手。103位已经拿到博客专家的作者也参与了本次竞争,竞争是何等的残酷啊。
OK,既然是2018博客之星的评选,上面的成绩再优异,毕竟也是历史成绩,历史成绩再高,我们也应该关注一下作者2018成绩。为此,我拉取了各位作者文章的归档。
| 2018年度写的文章 | 篇 |
|---|---|
| 最大 | 821 |
| 最小 | 0 |
| 平均 | 71 |
| 总计 | 57697 |
在这其中2018年度文章写的最多的达到了821 由mp624183768达到,平均每月文章数高达 68.当然这里包含非原创文章。
上面只是一些很干的数据,实际意义不是很大,真正有价值的数据在于作者的文章质量,评选作者我觉得最优先需要考虑的是作者的文章质量。关于作者的文章质量,我这里并没有具体深入,毕竟我不是官方,做这个意义不大,有兴趣的作者可以考虑以下几个方面:将值得评审的作者的2018年度全部文章进行查重原创性分析;将值得评审的作者的2018年度全部文章的所有评论存入ElasticSearch进行关键词分析,看看好评率占比;将值得评审的作者的2018年度全部文章的所有评论的回复进行分析看看作者的回复率。
当然,如果我们只想做一个简单的排名,上面已有的数据也够了。我自己设计了一个算法,利用我已有的数据,为每一位参与的作者计算了一下平均得分,这个就不公布出来,公布出来了有操作评选结果的嫌疑。我这里给大家提供一个我的排名思路:利用我现在已由的数据 包括但不限于 原创/粉丝/喜欢/评论/等级/访问/积分/排名/2018年度文章数,先将这些指标对所有参与作者进行排名。然后每一个指标按照最高得分为100为所有作者依据当前指标计算指标得分,最后再设定每个指标的权重比例,为所有参与作者计算一个综合加权分。
如果有参与本次评选的作者想知道自己在以上几项指标的排名,欢迎到下方留言,我将逐一进行答复。
如果只是单纯想横向对比一下自己的指标和排名靠前的大佬的指标,我这里给大家列出目前排名前三的博主。
- https://blog.csdn.net/stpeace 访问量高达
15576823 - https://blog.csdn.net/phphot 原创文章高达
6347 - https://blog.csdn.net/yuanmeng001 粉丝数高达
9201
下面再给大家展示一个我把所有报名的作者在评选报名博客的全部评论中对自己所研究方向做的简要说明做成的词云图,也算是让大家了解一下程序员目前的热门:
实现方案
免责申明
本篇文章纯粹出于兴趣,关于参与本次评选活动作者的信息,全部来源于CSDN博客网址。进行信息抓取之前,我特意查看了CSDN的robots.txt君子协议
CSDN 并没有禁止抓取其他人的博客首页。如有侵权,烦请与我联系删除此文章。
本篇文章志在指导大家利用自己的技术做一些有意义的或者有趣的事情,本人郑重承落,本次所抓取的全部数据不做永久存储,自文章完成之后将全部删除。
参与作者收集
我们先分析一下 https://blog.csdn.net/blogdevteam/article/details/84874036
查看CSDN 2018博客之星活动报名开始了!活动的参与规则要求:
自荐方式如下:在评论中放上您的CSDN博客地址、并进行简要说明。
即我们只要抓取全部评论中那些在评论中写下自己CSDN博客地址的评论。
检查一下评论信息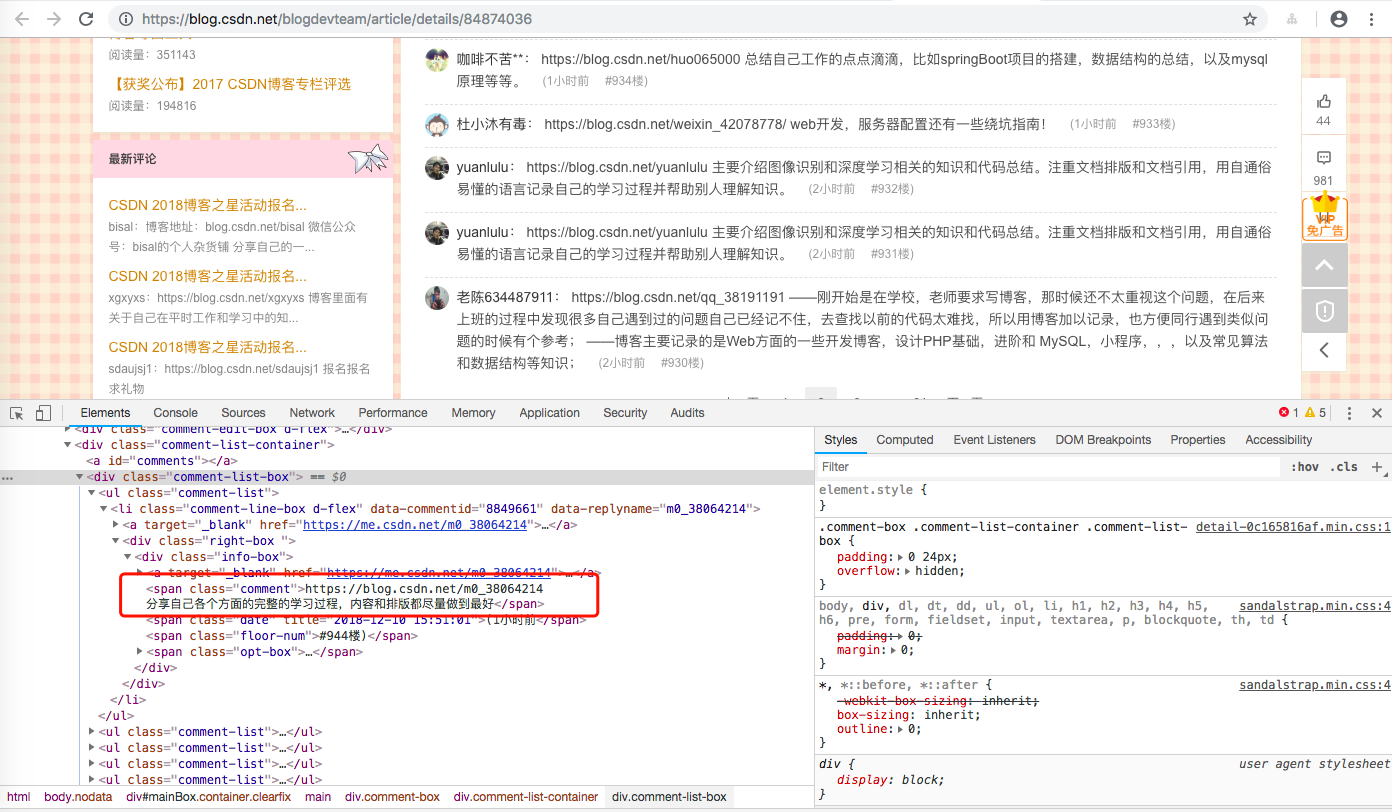
继续评论翻页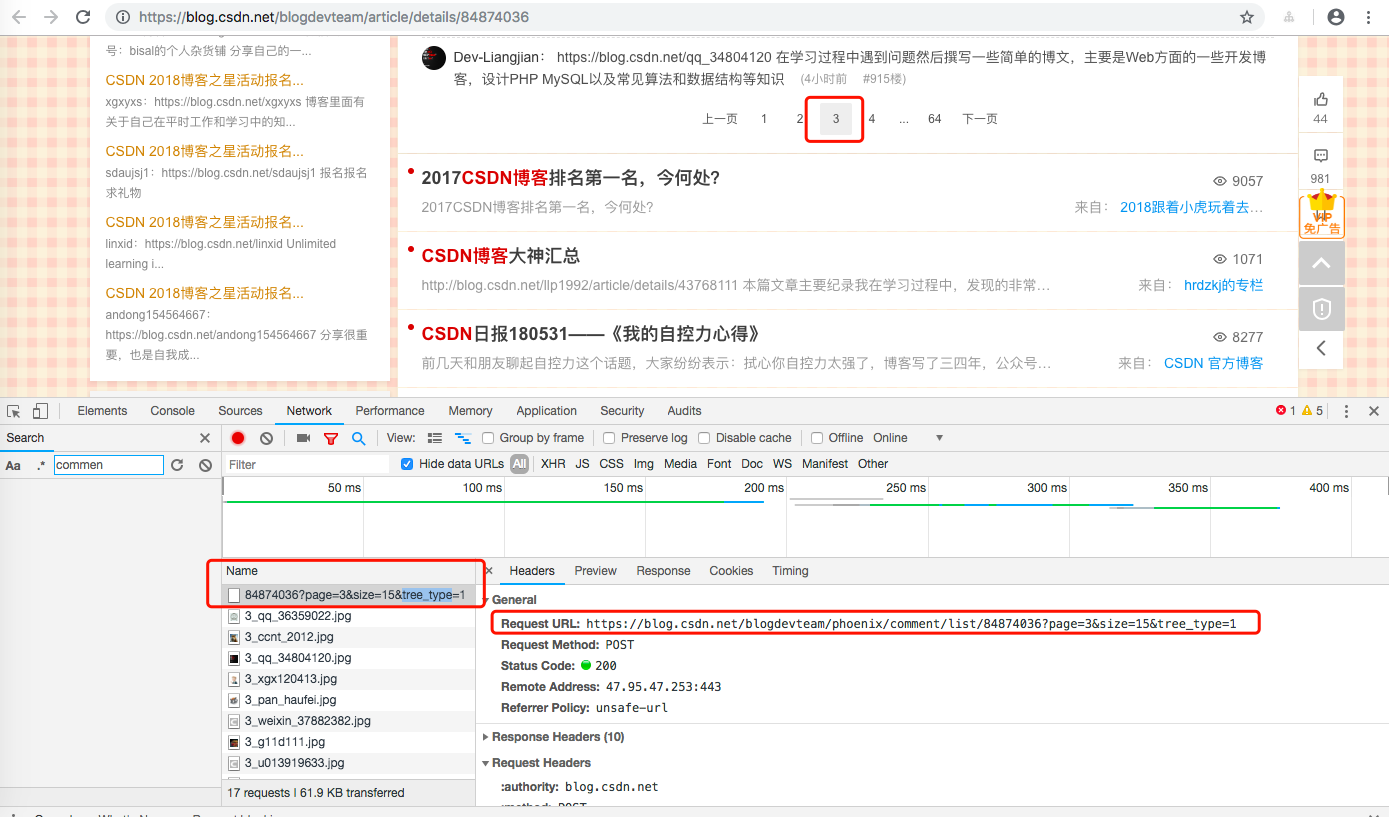
显然,我们访问 https://blog.csdn.net/blogdevteam/phoenix/comment/list/84874036 就可以直接拿到评论数据,所以我们第一步就是从 https://blog.csdn.net/blogdevteam/phoenix/comment/list/84874036 收集参与作者信息。
开始抓取
#进入虚拟环境cd /data/code/python/venv/venv_Scrapy/tutorial#新建csdn抓取../bin/python3 ../bin/scrapy genspider -t basic csdn_2018_blogstar blog.csdn.net
csdn_2018_blogstar.py
这里需要注意的是评论有多页,所以我们需要逐页分别获取,代码很简单,考虑到文章篇幅,我就不做过度解释了,注释写的很清楚了。如果对Scrapy不太清楚的,可以去我的专栏看看,入门很简单。
# -*- coding: utf-8 -*-import scrapyimport jsonfrom tutorial.items import CSDN2018BlogStarItemclass Csdn2018BlogstarSpider(scrapy.Spider):name = 'csdn_2018_blogstar'allowed_domains = ['blog.csdn.net']start_urls = ['https://blog.csdn.net/blogdevteam/phoenix/comment/list/84874036?page={}&size=15&tree_type=1']user_set = set()def start_requests(self):for url in self.start_urls:yield scrapy.Request(url.format(1), callback=self.parse)def parse(self, response):resp_dict = json.loads(response.text)if 'success' == resp_dict['content']:for comment in resp_dict['data']['list']:username = comment['info']['UserName'].lower()#截止时间为2018年12月11日 并且 附上自己的博客才算报名if comment['info']['Content'].find('csdn.net/'+username) > -1 and comment['info']['PostTime'] < '2018-12-11 00:00:00':#喜欢重复刷评论的小哥哥,刷了多次也只算一次啊if username not in __class__.user_set:__class__.user_set.add(username)#接下来到这里拉用户信息yield scrapy.Request('https://blog.csdn.net/'+username, callback=lambda response, info=comment['info']: self.parse_blog_user_info(response,info))for page in range(2,resp_dict['data']['page_count']+1):yield scrapy.Request(self.start_urls[0].format(page), callback=self.parse_other_page)def parse_other_page(self,response):resp_dict = json.loads(response.text)if 'success' == resp_dict['content']:for comment in resp_dict['data']['list']:username = comment['info']['UserName'].lower()# 截止时间为2018年12月11日 并且 附上自己的博客才算报名if comment['info']['Content'].find('csdn.net/'+username) > -1 and comment['info']['PostTime'] < '2018-12-12 00:00:00' :# 喜欢重复刷评论的小哥哥,刷了多次也只算一次啊if username not in __class__.user_set:__class__.user_set.add(username)#接下来到这里拉用户信息yield scrapy.Request('https://blog.csdn.net/'+username, callback=lambda response, info=comment['info']: self.parse_blog_user_info(response,info))
收集每位作者的指标信息
前面我们已经成功的收集了全部参与的作者,加下来只需要再收集每位作者指标信息,那么我们就完成了指标信息收集。
我们指导,直接访问每个作者个人首页就可以指导作者的一些相关指标信息,例如 https://blog.csdn.net/weixin_43430036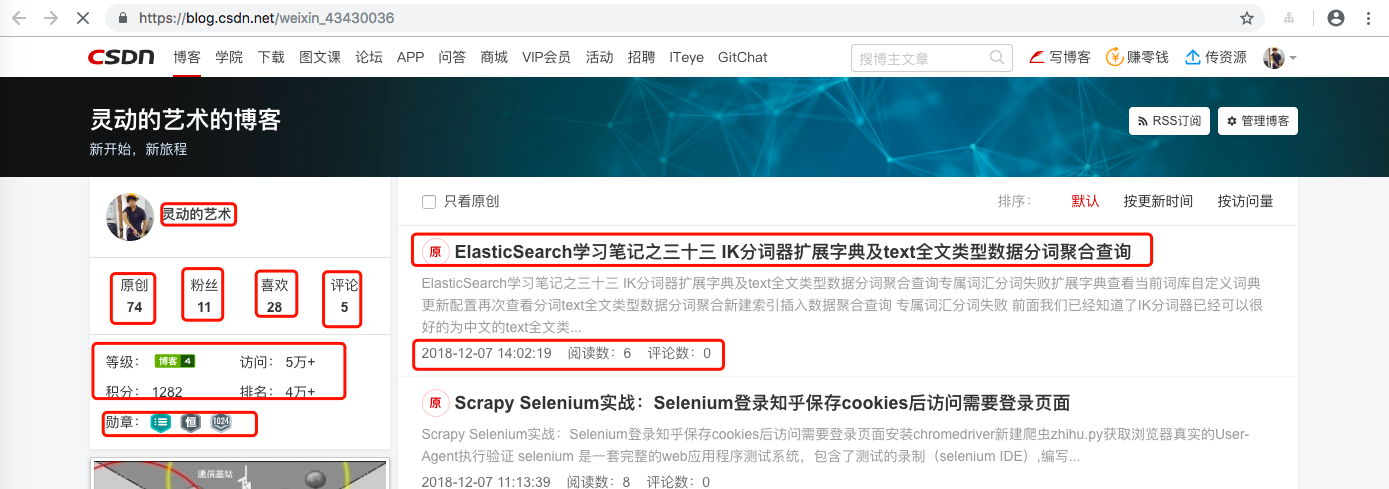
虽然我们也可以拿到作者的所有文章及评论,点赞等信息,但是我这里只是给大家一个案例,所以我这里不抓取作者的所有文章及评论,点赞等信息(可能侵权,大家多多理解)。
所以我这边暂定抓取的指标分别为 原创/粉丝/喜欢/评论/等级/访问/积分/排名/归档 等等模块信息。
检查指标
接下来,我们就可以利用浏览器的检查工具依次检查我们关心的指标,例如:
抓取指标信息
csdn_2018_blogstar.py
def parse_blog_user_info(self,response,info):info['Content'] = info['Content'].replace('\n','')item = CSDN2018BlogStarItem()item['link'] = response.request.urlitem['blogstar_comment'] = infoitem['blog_title'] = response.xpath('//div[@class="title-box"]/h1[@class="title-blog"]/a/text()').extract_first()item['description'] = response.xpath('//div[@class="title-box"]/p[@class="description"]/text()').extract_first()item['avatar_pic'] = response.xpath('//div[@class="profile-intro d-flex"]/div[@class="avatar-box d-flex justify-content-center flex-column"]/a/img/@src').extract_first()for data in response.xpath('//div[@class="data-info d-flex item-tiling"]/dl[@class="text-center"]'):data_key = data.xpath('./dt/a/text() | ./dt/text()').extract_first()data_value = data.xpath('./@title').extract_first()if data_key.find('原创') > -1:item['original'] = int(data_value)elif data_key.find('粉丝') > -1:item['fans'] = int(data_value)elif data_key.find('喜欢') > -1:item['star'] = int(data_value)elif data_key.find('评论') > -1:item['comment'] = int(data_value)for grade in response.xpath('//div[@class="grade-box clearfix"]/dl'):grade_key = grade.xpath('./dt/text()').extract_first()grade_value = grade.xpath('./dd/@title | ./dd/a/@title | ./@title').extract_first()if grade_key.find('等级') > -1:item['level'] = int(grade_value.replace('级,点击查看等级说明',''))elif grade_key.find('访问') > -1:item['visit'] = int(grade_value)elif grade_key.find('积分') > -1:item['score'] = int(grade_value)elif grade_key.find('排名') > -1:item['rank'] = int(grade_value)#勋章item['medal'] = response.xpath('//div[@class="badge-box d-flex"]/div[@class="icon-badge"]/@title').extract()blog_expert = ''.join(response.xpath('//div[@class="user-info d-flex justify-content-center flex-column"]/p[@class="flag expert"]/text()').extract()).replace('\n','').replace(' ','')if blog_expert and '' is not blog_expert :item['medal'].append(blog_expert)#归档archives = []for li in response.xpath('//div[@id="asideArchive"]/div[@class="aside-content"]/ul[@class="archive-list"]/li'):archives.append({ 'year_month':li.xpath('./a/text()').extract_first().replace(' ','').replace('\n',''),'article_num':li.xpath('./a/span/text()').extract_first().replace(' ','').replace('篇','')})item['archives'] = archivesyield item
同样,代码很简单,考虑到文章篇幅,我就不做过度解释了,注释写的很清楚了。
items.py
class CSDN2018BlogStarItem(scrapy.Item):link = scrapy.Field() # 博客地址blog_title = scrapy.Field() # 标题description = scrapy.Field() # 描述avatar_pic = scrapy.Field() # 头像original = scrapy.Field() # 原创fans = scrapy.Field() # 粉丝star = scrapy.Field() # 喜欢comment = scrapy.Field() # 评论level = scrapy.Field() # 等级visit = scrapy.Field() # 访问score = scrapy.Field() # 积分rank = scrapy.Field() # 排名medal = scrapy.Field() # 勋章archives = scrapy.Field() # 归档blogstar_comment = scrapy.Field() # 作者博客之星活动的评论
数据存储与分析
上面我们已经拿到了全部的作者,以及作者的指标。如果光有数据不对数据进行分析,我们拿到了数据也是毫无意义的。数据的存储方式各种各样,我们可以直接一个作者一个json文件,或者建立关系型数据库表,将作者及作者的指标信息存储到关系型数据库中,笔者这里建议使用ElasticSearch文档型数据库,如果不知道怎么使用的,可以到我的专栏查看,如果实在没兴趣学习,也无所谓,毕竟现在的数据量实在太小,完全对不起大数据这个词,也完全可以使用Mysql,一张表就可以搞定了,如果Mysql都不想用,可以一个作者一个json文件,就是分析起来比较麻烦一点,毕竟最原始的做法就可以遍历文件查找,ElasticSearch的优势就是比较好分析,我这边给大家一个案例。
ElasticSearch索引存储
如果这里展开ElasticSearch,我们的篇幅就太大了,这里直接给出我自己建立的索引
PUT csdn2018blogstar{"mappings":{"csdn2018blogstar":{"properties":{"link": {"type": "keyword","index": false},"blog_title":{"type": "text","analyzer": "ik_smart","fielddata": true},"description":{"type": "text","analyzer": "ik_smart","fielddata": true},"avatar_pic": {"type": "keyword","index": false},"original":{"type": "long"},"fans":{"type": "long"},"star":{"type": "long"},"comment":{"type": "long"},"level":{"type": "long"},"visit":{"type": "long"},"score":{"type": "long"},"rank":{"type": "long"},"medal":{"type": "text","analyzer": "ik_smart","fielddata": true},"archives":{"type": "nested","properties": {"year_month":{"type": "keyword"},"article_num":{"type": "long"}}},"blogstar_comment":{"type": "object","properties": {"CommentId":{"type": "keyword"},"ArticleId":{"type": "keyword"},"BlogId":{"type": "keyword"},"ParentId":{"type": "keyword"},"PostTime":{"type": "date","format": "yyyy-MM-dd HH:mm:ss"},"Content":{"type": "text","analyzer": "ik_smart","fielddata": true},"UserName":{"type": "keyword"},"Status":{"type": "keyword"},"IP":{"type": "keyword"},"IsBoleComment":{"type": "keyword"},"PKId":{"type": "keyword"},"Digg":{"type": "keyword"},"Bury":{"type": "keyword"},"SubjectType":{"type": "keyword"},"WeixinArticleId":{"type": "keyword"},"Avatar":{"type": "keyword"},"NickName":{"type": "text","analyzer": "ik_smart","fielddata": true,"fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"date_format":{"type": "text","analyzer": "ik_smart","fielddata": true}}}}}}}
这里需要注意,我们的文本使用的大多都是中文,所以我们需要使用中文的分词起IK_SMART。对于索引细节上不清楚的可以提问,就不详细展开了。
数据存储
pipelines.py
class CSDN2018BlogStarPipeline(object):count = 0def process_item(self, item, spider):CSDN2018BlogStar.index_doc(json.dumps(dict(item), ensure_ascii=False))__class__.count += 1print(__class__.count)return item
settings.py
# 尽量设置的长一点,避免对CSDN造成压力DOWNLOAD_DELAY = 3ITEM_PIPELINES = {'tutorial.pipelines.CSDN2018BlogStarPipeline': 1,}
开始抓取
# 进入虚拟目录cd /data/code/python/venv/venv_Scrapy/tutorial/# 开始抓取../bin/python3 ../bin/scrapy crawl csdn_2018_blogstar
抓取效果图如下:
数据分析
数据抓取需要一会,耐心等待数据抓取完成。数据抓取完成之后就是分析了。
CSDN2018BlogStar.py
新建ElasticSearch数据库模型操作ElasticSearch
#! /usr/bin/env python3# -*- coding:utf-8 -*-from backend.libs.Util import Utilclass CSDN2018BlogStar(object):index = 'csdn2018blogstar'es = Util.get_es()@classmethoddef index_doc(cls,body):cls.es.index(index=cls.index, doc_type=cls.index, body=body)@classmethoddef count_doc(cls):try:res = cls.es.count(index=cls.index, doc_type=cls.index,)except Exception as e:print('查询失败 ', str(e))return 0return res['count']@classmethoddef stats_aggs(cls,field):body = {"size": 0,"aggs": {"stats_"+field: {"stats": {"field": field}}}}try:res = cls.es.search(index=cls.index, doc_type=cls.index, body=body)except Exception as e:print('查询失败 ', str(e))res = Nonereturn res@classmethoddef term_aggs(cls,field,size=10):body = {"size": 0,"aggs": {"term_"+field: {"terms": {"field": field,"size": size,"order": {"_key": "desc"}}}}}try:res = cls.es.search(index=cls.index, doc_type=cls.index, body=body)except Exception as e:print('查询失败 ', str(e))res = Nonereturn res@classmethoddef term_query(cls,field,value):body = {"query": {"bool": {"filter": {"term": {field: value}}}}}try:res = cls.es.search(index=cls.index, doc_type=cls.index, body=body)except Exception as e:print('查询失败 ', str(e))res = Nonereturn res@classmethoddef username_term_query(cls,field,value):body = {"query": {"bool": {"filter": {"term": {field: value}}}},"_source": ["blogstar_comment.UserName"]}try:res = cls.es.search(index=cls.index, doc_type=cls.index, body=body)except Exception as e:print('查询失败 ', str(e))res = Nonereturn res@classmethoddef stats_agg_year_2018(cls):body = {"aggs": {"term_username": {"terms": {"field": "blogstar_comment.UserName","size": 10000},"aggs": {"year_2018": {"nested": {"path": "archives"},"aggs": {"prefix_yesr": {"filter": {"prefix": {"archives.year_month": "2018年"}},"aggs": {"sum_article_num": {"sum": {"field": "archives.article_num"}}}}}}}},"stats_year_2018":{"stats_bucket": {"buckets_path": "term_username>year_2018>prefix_yesr>sum_article_num"}}},"size": 0}try:res = cls.es.search(index=cls.index, doc_type=cls.index, body=body)except Exception as e:print('查询失败 ', str(e))res = Nonereturn res
分析脚本
#! /usr/bin/env python3# -*- coding:utf-8 -*-import syssys.path.append('../..')from backend.models.es.CSDN2018BlogStar import CSDN2018BlogStarimport jsonimport refrom pyecharts import Bar,WordClouddef hot_key_word_cloud():white_hotkey_list = ['分布式','算法','嵌入式','前端','机器学习','公众号','微信公众号','数据库','计算机','人工智能','后端','框架','数据结构','程序','大数据','程序设计','计算机网络','网络','视觉','数据','图像','小程序','图像分析','操作系统','架构','安卓','微服务','爬虫','设计模式']wordcloud = WordCloud(width=1300, height=900)name = []value = []for i,bucket in enumerate(CSDN2018BlogStar.hot_key()['aggregations']['term_comment']['buckets']):if re.compile(u'[\u4e00-\u9fa5]').search(bucket['key']) :if bucket['key'] in white_hotkey_list:name.append(bucket['key'])value.append(bucket['doc_count'])elif re.findall('[a-zA-Z]+', bucket['key']) :if bucket['key'].find('http') == -1 and bucket['key'].find('csdn') == -1 and 'details'!=bucket['key'] and '1&orderby'!=bucket['key']:name.append(bucket['key'])value.append(bucket['doc_count'])wordcloud.add("", name, value, word_size_range=[30, 120])wordcloud.render('csdn_blogstar_hotkey.html')if __name__ == '__main__':print('报名总人数:',CSDN2018BlogStar.count_doc())field_dict = { 'original':'原创','fans':'粉丝','star':'喜欢','comment':'评论','level':'等级','visit':'访问','score':'积分','rank':'排名',}field_stats_dict = { }for field in field_dict.keys():res = CSDN2018BlogStar.stats_aggs(field)if res:field_stats_dict[field] = {'max': int(res['aggregations']['stats_'+field]['max']),'min': int(res['aggregations']['stats_'+field]['min']),'avg': int(res['aggregations']['stats_'+field]['avg']),'sum': int(res['aggregations']['stats_'+field]['sum'])}print('指标','|','最大值','|','最小值','|','平均值','|','总计','|','最佳用户列表')print('|:------:|:---------:|:---------:|:---------:|:---------:|:-----------:|')for field in field_dict.keys():print(field_dict[field],'|',field_stats_dict[field]['max'],'|',field_stats_dict[field]['min'],'|', field_stats_dict[field]['avg'],'|',field_stats_dict[field]['sum'],'|',[hit['_source']['blogstar_comment']['UserName'] for hit in CSDN2018BlogStar.username_term_query(field, field_stats_dict[field]['min' if 'rank' == field else 'max'])['hits']['hits']])level_aggs_res = CSDN2018BlogStar.term_aggs('level')print('等级','|','人数')print('------|-----')if level_aggs_res :for bucket in level_aggs_res['aggregations']['term_level']['buckets']:print(bucket['key'],'|',bucket['doc_count'])print('勋章','|','人数')print('------|-----')medal_aggs_res = CSDN2018BlogStar.term_aggs('medal')if medal_aggs_res:for bucket in medal_aggs_res['aggregations']['term_medal']['buckets']:print(bucket['key'],'|',bucket['doc_count'])year_2018_stats_agg_res = CSDN2018BlogStar.stats_agg_year_2018()if year_2018_stats_agg_res:print('2018年度写的文章 | 篇')print('-----------------|------')print('最大|',int(year_2018_stats_agg_res['aggregations']['stats_year_2018']['max']))print('最小|',int(year_2018_stats_agg_res['aggregations']['stats_year_2018']['min']))print('平均|',int(year_2018_stats_agg_res['aggregations']['stats_year_2018']['avg']))print('总计|',int(year_2018_stats_agg_res['aggregations']['stats_year_2018']['sum']))print('2018年度文章写的最多的数量',int(year_2018_stats_agg_res['aggregations']['stats_year_2018']['max']),'用户',[bucket['key'] for bucket in year_2018_stats_agg_res['aggregations']['term_username']['buckets'] if bucket['year_2018']['prefix_yesr']['sum_article_num']['value'] == int(year_2018_stats_agg_res['aggregations']['stats_year_2018']['max'])],'平均每月文章数',int(year_2018_stats_agg_res['aggregations']['stats_year_2018']['max']/12))hot_key_word_cloud()
分析结果图如下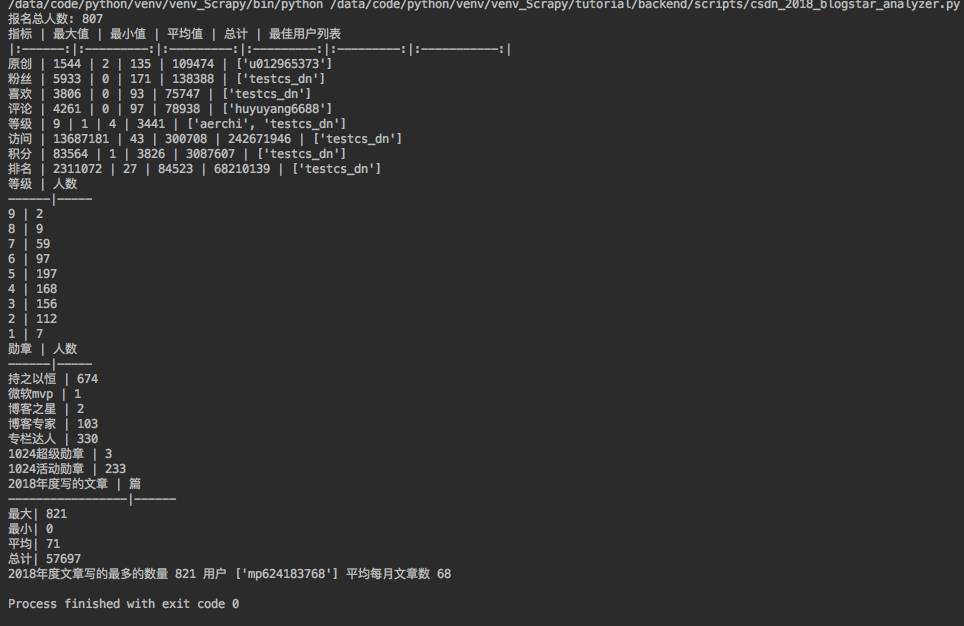
GItHub源代码
































还没有评论,来说两句吧...