CSDN2018博客之星评选结果预测第二弹
CSDN2018博客之星评选结果预测第二弹
CSDN2018博客之星活动开始之初,出于个人娱乐,我做了一次《大数据预测CSDN2018博客之星评选结果》,受到了较多好评,当然也十分荣幸的受到CSDN官方重视,并将文章放置在Banner推广位。
至今,CSDN2018博客之星的评选结果即将出炉。我很荣幸收到了CSDN官方的邀请,他们希望我能够在结果出炉之前再次作出一次大胆预测。所以,我将再次开启大胆预测。
闲话不多说,我们开始:
首先,如果你关注过这个活动,那么你应该知道,CSDN2018博客之星评选活动参选人员入选博主名单可以在以下网址看到 https://bss.csdn.net/m/topic/blog_star2018
即: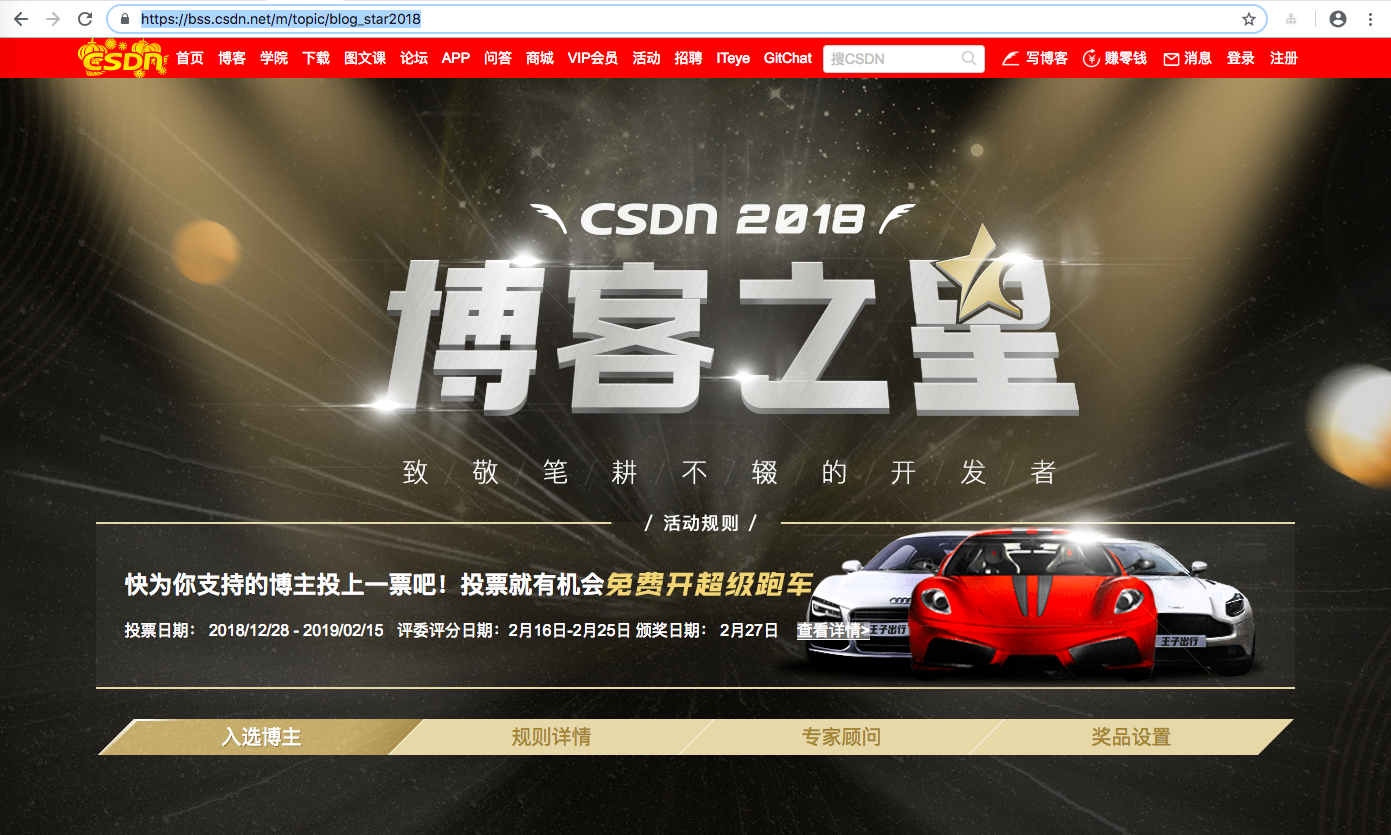
时间尚未截止,有心怡的博主入选还没有投票的,赶紧去投上一票吧。
那么,截止到本文出炉为止,200位入选博主的原创/粉丝/喜欢/评论/等级/访问/积分/排名/获得选票 各指标信息如何呢?
| 指标 | 最大值 | 最小值 | 平均值 | 总计 | 最佳用户列表 |
|---|---|---|---|---|---|
| 原创 | 2327 | 29 | 292 | 58582 | [‘迂者-贺利坚’] |
| 粉丝 | 22564 | 47 | 2093 | 418649 | [‘迂者-贺利坚’] |
| 喜欢 | 6466 | 8 | 694 | 138967 | [‘foruok’] |
| 评论 | 7360 | 3 | 622 | 124528 | [‘迂者-贺利坚’] |
| 等级 | 10 | 3 | 6 | 1285 | [‘dog250’, ‘迂者-贺利坚’] |
| 访问 | 11084501 | 50663 | 1590813 | 318162704 | [‘china_jeffery’] |
| 积分 | 107000 | 507 | 14762 | 2952414 | [‘迂者-贺利坚’] |
| 排名 | 125326 | 12 | 6532 | 1306538 | [‘迂者-贺利坚’] |
| 投票 | 2823 | 20 | 141 | 28335 | [‘徐刘根’] |
由上面的表格我们可以得出的结论。
- 目前获得票数最高的是
徐刘根博主,并且获得选票高达2823票,人气相当火爆。 - 目前文章最高总访问次数由
china_jeffery博主拿下,并且访问次数高达11084501。 - 目前文章总点赞次数由
foruok博主拿下,并且已经获得了6466点赞。 - 截止目前为止,其他各项指标,包括最佳排名(
12),最佳收藏(2327),最多原创(13687181),最高积分(107000),最高等级(10),最多粉丝(22564),最多评论(7360)均由迂者-贺利坚博主砍下,这个成绩可是相当恐怖的。
这里我们再重点关注一下,截止目前为止对于200位入选博主的投票情况。
| 指标 | 最大值 | 最小值 | 平均值 | 总计 |
|---|---|---|---|---|
| 投票 | 2823 | 20 | 141 | 28335 |
即:
- 目前总计只有
28335位用户参与了投票,还没有参与过投票的博主记得给自己心怡的博主投上一票啊。(对于具有500万注册程序员用户的CSDN来说,这个参与投票人数确实有点少啊) - 目前入选200位博主平均获得选票有
141票。(多项指标成绩最佳的迂者-贺利坚博主的选票目前还没到平均线,各位粉丝们要给力啊)
然后,我们再关注一下,目前排名前十的得票博主
| 排名 | 得票 | 博主 |
|---|---|---|
| 1 | 2823 | 徐刘根 |
| 2 | 1549 | LovelyBear2019 |
| 3 | 1336 | 肖朋伟 |
| 4 | 1136 | ECMAScripter |
| 5 | 1111 | 刘望舒 |
| 6 | 999 | 方志朋 |
| 7 | 836 | Soyoger |
| 8 | 648 | analogous_love |
| 9 | 576 | Eastmount |
| 10 | 554 | 虚无境 |
第二名与第一名的差距还是相当的大啊。大家要火热开启投票节奏啊!
接下来,我们再看一下,入选的200位博主,目前博客等级排名
| 等级 | 人数 |
|---|---|
| 10 | 2 |
| 9 | 3 |
| 8 | 18 |
| 7 | 83 |
| 6 | 50 |
| 5 | 39 |
| 4 | 3 |
| 3 | 2 |
由此看来,报名入选博主在CSDN的等级分布还是比较均匀的,纵使你目前的博客等级不是很高,只有文章质量可以也还是有机会的。
接下来,我们再看一下,入选的200位博主目前已经获得的荣誉勋章情况如下
| 勋章 | 人数 |
|---|---|
| 持之以恒 | 170 |
| 微软mvp | 1 |
| 博客之星 | 6 |
| 博客专家 | 191 |
| 专栏达人 | 177 |
| 1024超级勋章 | 3 |
| 1024活动勋章 | 43 |
即:
6位作者已经拿过博客之星勋章,并且发起了再次冲击。3位作者拿到了1024超级勋章勋章,这意味着有超过3位报名作者的原创文章超过了1024篇,堪称超级写手。191位已经拿到博客专家,当然也有9位目前尚未拿到博客专家称号,说明没有博客专家称号也还是有机会的。
当然,我们在投票之余,也可以多多关注一下大佬博主们的文章,看看这些博主专家们的研究方向,看看技术热点,作为我们2019年的学习方向。我这里还是老规矩为大家贡献一张目前已入选博主的所有专栏相关课题研究方向热力图供大家参考。

技术实现分析
知其然亦知其所以然,如果大家也有兴趣做类似的技术分析或者想要进一步深入技术发掘分析,我们再一起看看我们是怎么分析的。
数据挖掘
首先,我们知道 入选博主名单可以在 https://bss.csdn.net/m/topic/blog_star2018 网址看到,那么自然我们分析信息需要从这里出发。
想必你也猜到了,我们需要首先爬取所有的入选博主。如果对于爬虫不太了解可以从我的Scrapy专栏或者前一篇文章《大数据预测CSDN2018博客之星评选结果》了解详细,我这里就不深入了。例如,我们可以从这里拿到入选博主的基础信息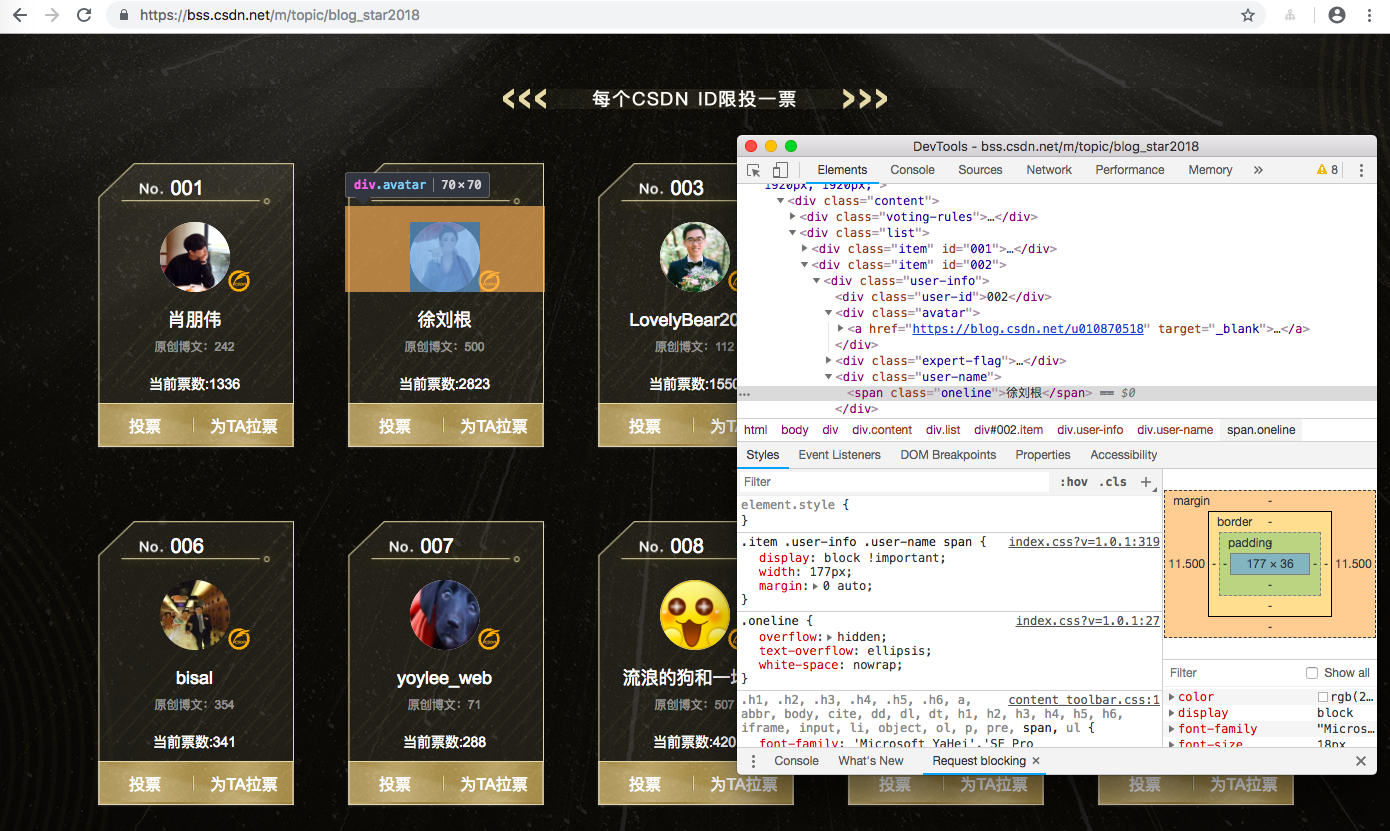
# -*- coding: utf-8 -*-import scrapyimport jsonfrom tutorial.items import BlogStar2018Itemclass BlogStar2018Spider(scrapy.Spider):name = 'blog_star2018'allowed_domains = ['blog.csdn.net']start_urls = ['https://bss.csdn.net/m/topic/blog_star2018']def parse(self, response):for user_info in response.xpath('//div[@class="user-info"]'):info = { }user_id = user_info.xpath('./div[@class="user-id"]/text()').extract_first()user_addr = user_info.xpath('./div[@class="avatar"]/a/@href').extract_first()user_name = user_info.xpath('./div[@class="user-name"]/span/text()').extract_first()user_number = user_info.xpath('./div[@class="user-number"]/span/em/text()').extract_first()print(user_id,user_addr,user_name,user_number)info['user_id'] = user_idinfo['user_addr'] = user_addrinfo['user_name'] = user_nameinfo['user_number'] = user_numberyield scrapy.Request(user_addr,callback=lambda response, info=info: self.parse_blog_user_info(response,info))
当然,只知道那些博主入选了本次评选是远远不够的,我们还需要知道包括但不限于 原创/粉丝/喜欢/评论/等级/访问/积分/排名/专栏/技术方向 等等信息。例如,我们可以利用分析工具抓取所有的入选博主的专栏信息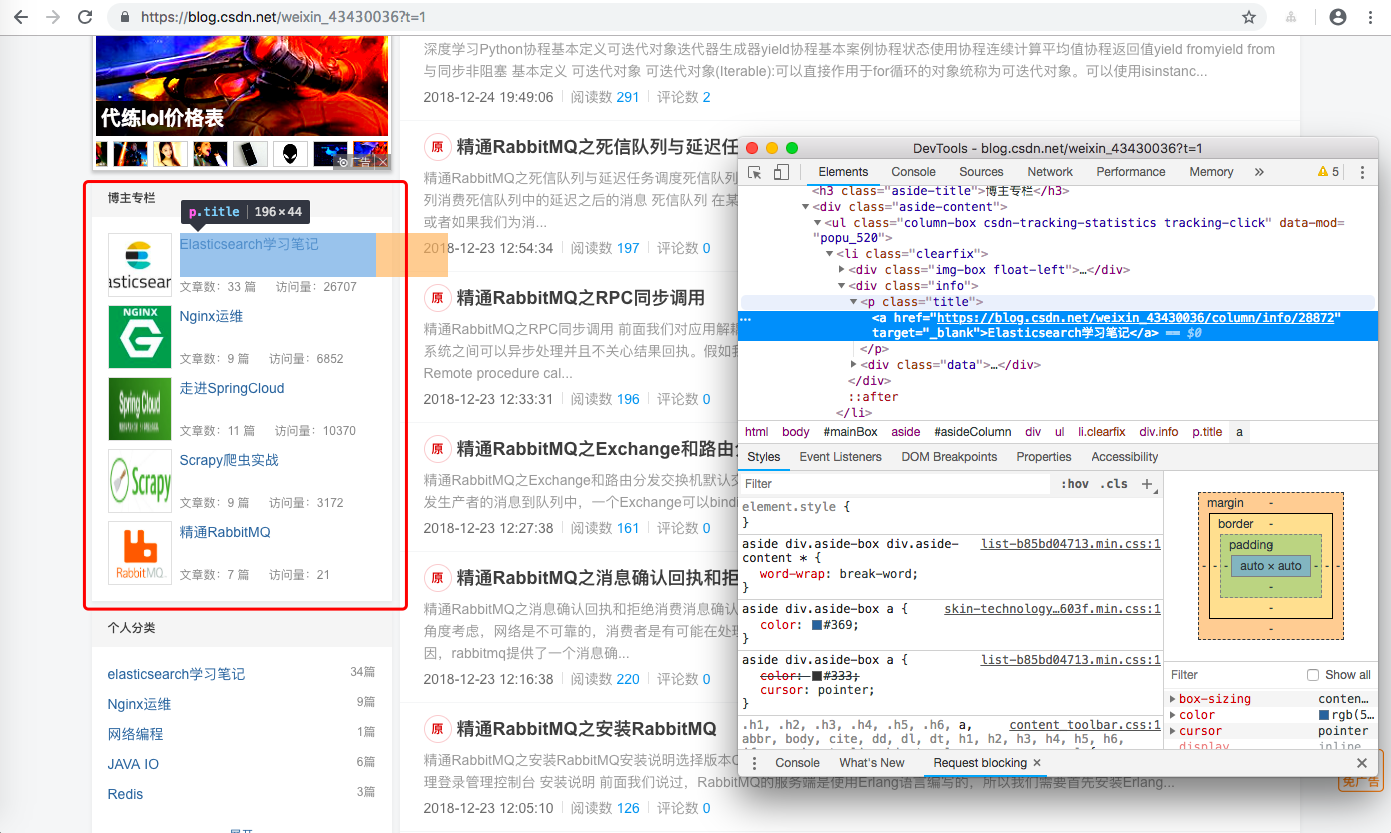
def parse_blog_user_info(self,response,info):item = BlogStar2018Item()item['link'] = response.request.urlitem['blogstar_vote'] = infoitem['blog_title'] = response.xpath('//div[@class="title-box"]/h1[@class="title-blog"]/a/text()').extract_first()item['description'] = response.xpath('//p[@class="description"]/text()').extract_first()item['avatar_pic'] = response.xpath('//div[@class="profile-intro d-flex"]/div[@class="avatar-box d-flex justify-content-center flex-column"]/a/img/@src').extract_first()for data in response.xpath('//div[@class="data-info d-flex item-tiling"]/dl[@class="text-center"]'):data_key = data.xpath('./dt/a/text() | ./dt/text()').extract_first()data_value = data.xpath('./@title').extract_first()if data_key.find('原创') > -1:item['original'] = int(data_value)elif data_key.find('粉丝') > -1:item['fans'] = int(data_value)elif data_key.find('喜欢') > -1:item['star'] = int(data_value)elif data_key.find('评论') > -1:item['comment'] = int(data_value)for grade in response.xpath('//div[@class="grade-box clearfix"]/dl'):grade_key = grade.xpath('./dt/text()').extract_first()grade_value = grade.xpath('./dd/@title | ./dd/a/@title | ./@title').extract_first()if grade_key.find('等级') > -1:item['level'] = int(grade_value.replace('级,点击查看等级说明',''))elif grade_key.find('访问') > -1:item['visit'] = int(grade_value)elif grade_key.find('积分') > -1:item['score'] = int(grade_value)elif grade_key.find('排名') > -1:item['rank'] = int(grade_value)#勋章item['medal'] = response.xpath('//div[@class="badge-box d-flex"]/div[@class="icon-badge"]/@title').extract()blog_expert = ''.join(response.xpath('//div[@class="user-info d-flex justify-content-center flex-column"]/p[@class="flag expert"]/text()').extract()).replace('\n','').replace(' ','')if blog_expert and '' is not blog_expert :item['medal'].append(blog_expert)#博主专栏colunms = []for li in response.xpath('//div[@id="asideColumn"]/div[@class="aside-content"]/ul/li'):colunms.append({ 'colunm_name':li.xpath('./div[@class="info"]/p/a/text()').extract_first(),'colunm_count': li.xpath('./div[@class="info"]/div[@class="data"]/span/text()').extract_first().replace(' ', '').replace('篇',''),'colunm_read': li.xpath('./div[@class="info"]/div[@class="data"]/span/text()').extract()[-1].replace(' ', '')})item['colunms'] = colunmsyield item
当然,我们也可以继续抓取更多信息,这里就留给大家扩展了。
数据存储与分析
我们都知道,空有了数据来源,不能对数据做出存储与分析,等于什么都没做,所以,我们需要对我们的数据作出存储与分析。
数据存储
我们这里还是使用Elasticsearch 做数据存储,如果对Elasticsearch有兴趣,希望学习的话,可以到我的专栏查看,我这里就不展开了,我这里给大家分享一下,我这边建立的数据存储索引。
PUT blogstar2018{"mappings":{"blogstar2018":{"properties":{"link": {"type": "keyword","index": false},"blog_title":{"type": "text","analyzer": "ik_smart","fielddata": true},"description":{"type": "text","analyzer": "ik_smart","fielddata": true},"avatar_pic": {"type": "keyword","index": false},"original":{"type": "long"},"fans":{"type": "long"},"star":{"type": "long"},"comment":{"type": "long"},"level":{"type": "long"},"visit":{"type": "long"},"score":{"type": "long"},"rank":{"type": "long"},"medal":{"type": "text","analyzer": "ik_smart","fielddata": true},"colunms":{"type": "nested","properties": {"colunm_name":{"type": "text","analyzer": "ik_smart","fielddata": true},"colunm_count":{"type": "long"},"colunm_read":{"type": "long"}}},"blogstar_vote":{"type": "object","properties": {"user_id":{"type": "keyword"},"user_addr":{"type": "keyword"},"user_name":{"type": "keyword"},"user_number":{"type": "long"}}}}}}}
数据字段不是很多,我这里就不再做详细分析了,这里需要注意,我们的文本使用的大多都是中文,所以我们需要使用中文的分词起IK_SMART。
数据分析
当我们成功抓取到数据并存储以后呢,我们需要对我们的数据加以分析才能够发挥出它的作用。
#! /usr/bin/env python3# -*- coding:utf-8 -*-import elasticsearchclass BlogStar2018(object):index = 'blogstar2018'es = elasticsearch.Elasticsearch(['sc.es.com:80'])@classmethoddef index_doc(cls,body):cls.es.index(index=cls.index, doc_type=cls.index, body=body)@classmethoddef match_all(cls):body = {"query": {"match_all": { }},"size": 1000}try:res = cls.es.search(index=cls.index, doc_type=cls.index, body=body)except Exception as e:print('查询失败 ', str(e))res = Nonereturn res@classmethoddef count_doc(cls):try:res = cls.es.count(index=cls.index, doc_type=cls.index,)except Exception as e:print('查询失败 ', str(e))return 0return res['count']@classmethoddef stats_aggs(cls,field):body = {"size": 0,"aggs": {"stats_"+field: {"stats": {"field": field}}}}try:res = cls.es.search(index=cls.index, doc_type=cls.index, body=body)except Exception as e:print('查询失败 ', str(e))res = Nonereturn res@classmethoddef term_aggs(cls,field,size=10):body = {"size": 0,"aggs": {"term_"+field: {"terms": {"field": field,"size": size,"order": {"_key": "desc"}}}}}try:res = cls.es.search(index=cls.index, doc_type=cls.index, body=body)except Exception as e:print('查询失败 ', str(e))res = Nonereturn res@classmethoddef term_query(cls,field,value):body = {"query": {"bool": {"filter": {"term": {field: value}}}}}try:res = cls.es.search(index=cls.index, doc_type=cls.index, body=body)except Exception as e:print('查询失败 ', str(e))res = Nonereturn res@classmethoddef username_term_query(cls,field,value):body = {"query": {"bool": {"filter": {"term": {field: value}}}},"_source": ["blogstar_vote.user_name"]}try:res = cls.es.search(index=cls.index, doc_type=cls.index, body=body)except Exception as e:print('查询失败 ', str(e))res = Nonereturn res@classmethoddef stat_colunm_name(cls):body = {"aggs": {"colunms": {"nested": {"path": "colunms"},"aggs": {"colunm_name": {"terms": {"field": "colunms.colunm_name","size": 1000}}}}}}try:res = cls.es.search(index=cls.index, doc_type=cls.index, body=body)except Exception as e:print('查询失败 ', str(e))res = Nonereturn res
blogstar2018_analyzer.py
#! /usr/bin/env python3# -*- coding:utf-8 -*-import syssys.path.append('../..')import jsonimport refrom backend.models.es.BlogStar2018 import BlogStar2018from pyecharts import Bar,WordCloudif __name__ == '__main__':# field_dict = {'original':'原创','fans':'粉丝','star':'喜欢','comment':'评论','level':'等级','visit':'访问','score':'积分','rank':'排名','blogstar_vote.user_number':'投票'}## print('报名总人数:',BlogStar2018.count_doc())# field_stats_dict = {}# for field in field_dict.keys():# res = BlogStar2018.stats_aggs(field)# if res:# field_stats_dict[field] = {# 'max': int(res['aggregations']['stats_'+field]['max']),# 'min': int(res['aggregations']['stats_'+field]['min']),# 'avg': int(res['aggregations']['stats_'+field]['avg']),# 'sum': int(res['aggregations']['stats_'+field]['sum'])# }# print('指标','|','最大值','|','最小值','|','平均值','|','总计','|','最佳用户列表')# print('|:------:|:---------:|:---------:|:---------:|:---------:|:-----------:|')# for field in field_dict.keys():# print(field_dict[field],'|',field_stats_dict[field]['max'],'|',field_stats_dict[field]['min'],# '|', field_stats_dict[field]['avg'],'|',field_stats_dict[field]['sum'],# '|',[hit['_source']['blogstar_vote']['user_name'] for hit in BlogStar2018.username_term_query(field, field_stats_dict[field]['min' if 'rank' == field else 'max'])['hits']['hits']])## level_aggs_res = BlogStar2018.term_aggs('level')# print('等级','|','人数')# print('------|-----')# if level_aggs_res :# for bucket in level_aggs_res['aggregations']['term_level']['buckets']:# print(bucket['key'],'|',bucket['doc_count'])## print('勋章','|','人数')# print('------|-----')# medal_aggs_res = BlogStar2018.term_aggs('medal')# if medal_aggs_res:# for bucket in medal_aggs_res['aggregations']['term_medal']['buckets']:# print(bucket['key'],'|',bucket['doc_count'])white_hotkey_list = ['分布式','算法','嵌入式','前端','机器学习','公众号','微信公众号','数据库','计算机','人工智能','后端','框架','数据结构','程序','大数据','程序设计','计算机网络','网络','视觉','数据','图像','小程序','图像分析','操作系统','架构','安卓','微服务','爬虫','设计模式']wordcloud = WordCloud(width=1300, height=900)name = []value = []for i,bucket in enumerate(BlogStar2018.stat_colunm_name()['aggregations']['colunms']['colunm_name']['buckets']):if re.compile(u'[\u4e00-\u9fa5]').search(bucket['key']) :if bucket['key'] in white_hotkey_list:name.append(bucket['key'])value.append(bucket['doc_count'])elif re.findall('[a-zA-Z]+', bucket['key']) :if bucket['key'].find('http') == -1 and bucket['key'].find('csdn') == -1 and 'details'!=bucket['key'] and '1&orderby'!=bucket['key']:name.append(bucket['key'])value.append(bucket['doc_count'])wordcloud.add("", name, value, word_size_range=[30, 120])wordcloud.render('blogstar_csdn.html')
GitHub源代码
感谢您的阅读,新年新气象,祝您,新年快乐,阖家欢乐。




























还没有评论,来说两句吧...