Cross-Modality Person Re-Identification with Generative Adversarial Training--阅读
论文链接,点击此处
提出背景
- 真实场景少
- 夜晚监控当中的红外场景
论文内容
针对真实场景和红外场景,作者提出了
- cmGAN网络,是端到端的,以 DCNN为基本框架
- 混合loss,是将 identification loss 和cross-modality triplet loss结合了,目的是将内部识别模糊的类最小化,跨模态相似的类间距最大化

[ -1 ] DCNN作为产生器,产生RGB 和IR images的 modality-invariant rep-resentation,这个产生器高级监督和优化两个loss(identification loss 和cross-modality triplet loss)
- identification loss 将内部类分离开
- cross-modality triplet loss 将RGB 和IR间距最小化(如上图featureEmbedding第一个)
- 混合loss, 是将两者结合的,具体公式如下:
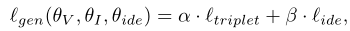
[ -2 ] Discriminator作为模态分类器,其中 modality classifier是三层前馈网络,交叉熵作为对抗loss。ID Prediction是 2层全连接。
[ -3 ] Generator输出是 probability distribution of person identifications,也就是 Discriminator的输入,它产生Classification loss
[ -4 ] Generator and Discriminator再互相博弈,博弈方法是minimax game,来学习RGB 和IR的discriminative common representation
这里的公式(7)(8)为 图最终三个loss的交叉结果—Adversarial Learning。其中公式参数 Ldis是Classification loss,v 是RGB模态,I 是IR 模态
数据集
SYSU :6个camera 1个exp标签
其中 cam3 cam6 是红外场景IR,cam1 cam2 cam4 cam5 是真实场景RGB
491 个person
28,7628张RGB
1,5792张IR
拆分成
训练集3,2451张
测试集27,0969张
分别对应论文
cam1 —room1(indoor)
cam2–room2(indoor)
cam3–room2(indoor)–红外的
cam4–Gate
cam5— Garden
cam6–passage
实验结果
| all search | mAP |
|---|---|
| sigle-shot | 27.80 |
| Multi-shot | 22.27 |
| indoor search | mAP |
|---|---|
| sigle-shot | 42.19 |
| Multi-shot | 32.76 |


























")

:编写个人页面和配置路由")





还没有评论,来说两句吧...