HBase学习 - 入门(1)
HBase Version 1.2.11 hbase官方英文文档
HBase Version 0.95 hbase中文文档
参考学习网址一:HBase教程
目录:
- HBase概述:HBase是Hadoop的生态系统,HBase是一个分布式,版本化,面向列的数据库,构建在 Apache Hadoop和 Apache ZooKeeper之上。
- HBase与HDFS
HBase运行模式
- 第一种:独立式HBase
运行环境:安装Java、安装HBase(使用自带的Zookeeper,不使用HDFS,而是使用本地文件系统) - 第二种:独立于HDFS的HBase
运行环境一:安装Java、安装Hadoop、安装HBase(使用自带的Zookeeper)
运行环境二:安装Java、安装Hadoop、安装HBase(不使用自带的Zookeeper,就安装Zookeeper) - 第三种:伪分布式HBase:
运行环境一:安装Java、安装HBase(使用自带的Zookeeper)
运行环境三:安装Java、安装HBase(不使用自带的Zookeeper,安装Zookeeper)
运行环境二:安装Java、安装Hadoop、安装HBase(使用自带的Zookeeper)
运行环境三:安装Java、安装Hadoop、安装HBase(不使用自带的Zookeeper,安装Zookeeper) - 第四种:完全分布式:
运行环境:安装Java、安装Hadoop、安装Zookeeper、安装HBase(不使用自带的Zookeeper,安装Zookeeper)
- 第一种:独立式HBase
- 安装:hbase安装
- HBase配置
HBase Shell
- 启动HBase Shell
- 测试:shell命令
HBase数据模型
简单来说,应用程序是以表的方式在HBase存储数据的。表是由行和列构成的,所有的列是从属于某一个列族的。行和列的交叉点称之为cell,cell是版本化的。cell的内容是不可分割的字节数组。
表的行键也是一段字节数组,所以任何东西都可以保存进去,不论是字符串或者数字。HBase的表是按key排序的,排序方式之针对字节的。所有的表都必须要有主键-key.概念视图
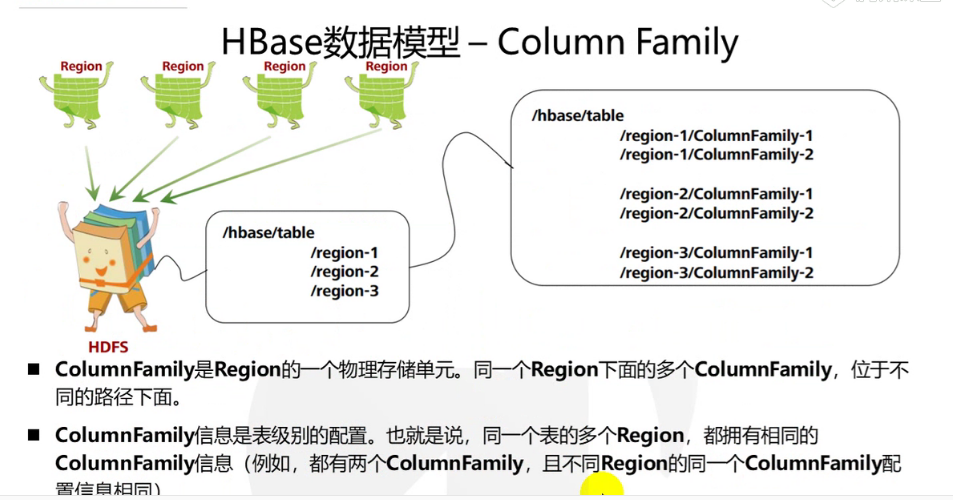
HBase以表的形式存储数据,表由行和列组成。列划分为若干个列族,如下图所示:
- RowKey:Hbase使用Rowkey来唯一的区分某一行的数据。如图中”rk001”
- 列族:Hbase通过列族划分数据的存储,列族下面可以包含任意多的列,实现灵活的数据存取。Hbase的列族不是越多越好,官方推荐的是列族最好小于或者等于3。我们使用的场景一般是1个列族。如图中的“CF1”列族,下面包含两个列:”Name”和”Alias”。
- 列名:一个列名是由它的列族前缀和修饰符(qualifier)连接而成。例如列CF1:Name是列族 CF1加冒号(
:)加 修饰符 Name组成的。 - 时间戳:TimeStamp对Hbase来说至关重要,因为它是实现Hbase多版本的关键。在Hbase中使用不同的timestame来标识相同rowkey行对应的不通版本的数据。
- Cell:HBase 中通过 rowkey 和 columns 确定的为一个存储单元称为 cell。每个 cell 都保存着同一份 数据的多个版本。版本通过时间戳来索引。
- 物理视图
- 表
- 行
- 列族
- Cells
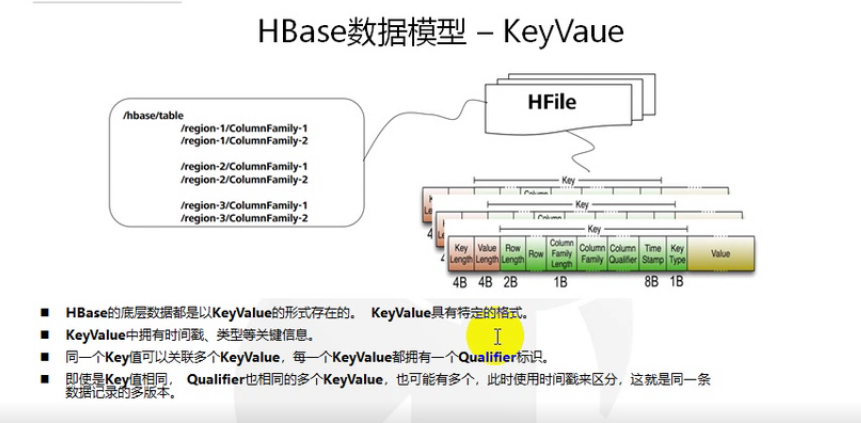
A {row, column, version} 元组就是一个HBase中的一个cell。Cell的内容是不可分割的字节数组。 - 版本
一个 {row, column, version} 元组是HBase中的一个单元(cell).但是有可能会有很多的单元的行和列是相同的,可以使用版本来区分不同的单元. 底层存储数据模型
- 一个小实例:
- 一个小实例:
HBase架构
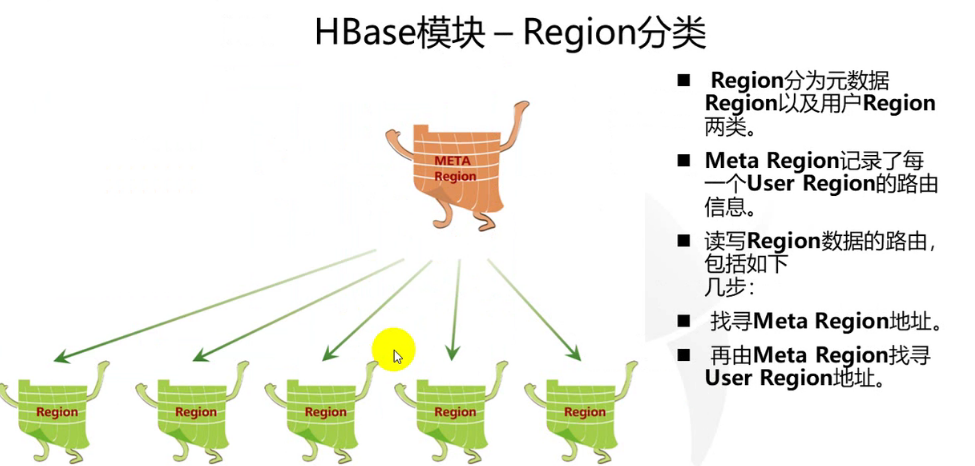
hbase meta表
- hbase有两个关键表ROOT表与meta表。其实在hbase0.98之后,hbase就废弃了ROOT表,仅保留meta表(还有namespace表,该表只与hbase命名空间有关,这里不做介绍),并且该表不允许split。
- meta split
在0.98后,meta被禁止进行split操作。要知道meta表的一条记录包含了一个region的位置、起始key,创建时间等信息。那万一region数量过大怎么办?查看了公司集群一共1091个region,meta表的大小如图所示:
假定集群有十万个region,meta表也就400多M。在生产环境下,hbase.hregion.max.filesize配置为10G,如果按照这个大小来看,meta可支持的region的数据是一个很可观的数量。 - meta位置
meta表location info以非临时znode的方式注册到zk上,如下图,可知meta region位置为centos063机器。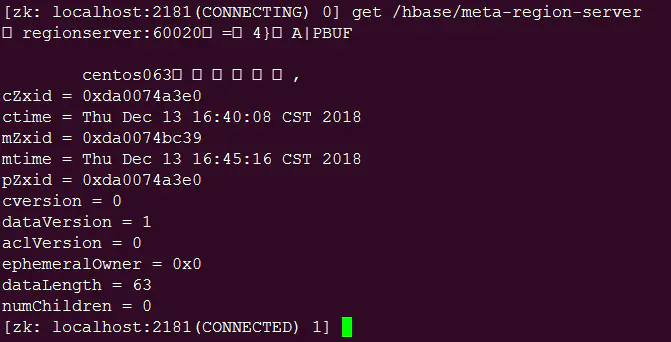
- meta表的结构
meta表的rowkey组成为:表名,region startKey,创建时间.hash值。如果当前region为table的第一个region时(第一个region无start key)时,region startKey=null。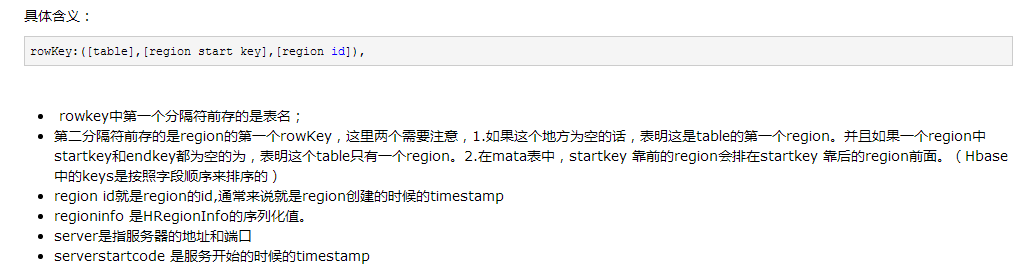
- mete info
meta表只有一个列簇info,并且包含四列:
1、regioninfo :当前region的startKey与endKey,name等消息
2、seqnumDuringOpen:
3、server:region所在服务器及端口
4、serverstartcode:服务开始的时候的timestamp - 查找数据
根据meta表查找key对应的region - 插入数据
当有一个key需要做put操作的时候,会先扫描meta表,找到对应region,然后进行插入操作。
例如:有一个table具有三个region,每个region的startkey分别是 空,bar,foo,如下图:1 table,,1351700811858 2 table,bar,1351700819876 3 table,foo,1351700829874
如果我们需要插入key ‘baz’ ,我们能找meta表中对应的rowkey为(table,bar,1351700819876)。
这个查找完之后会缓存在客户端,下次查询的时候会根据缓存来直接去访问region。
- HMaster
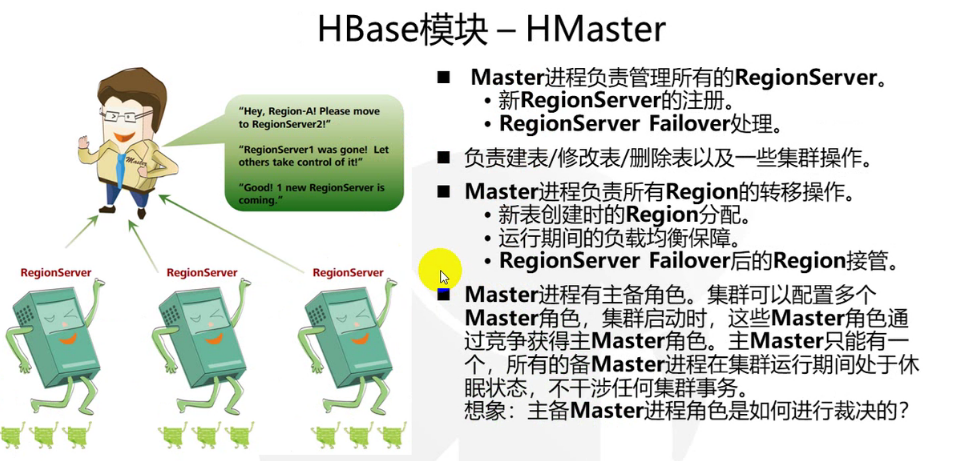
HRegionServer故障转移的规则:不是从空闲的HRegionServer中选取(不用zookeeper进行选举),而是根据集群HRegionServer,从顺时针方向下一个中选取,也就不需要实时监控RegionServer,如下图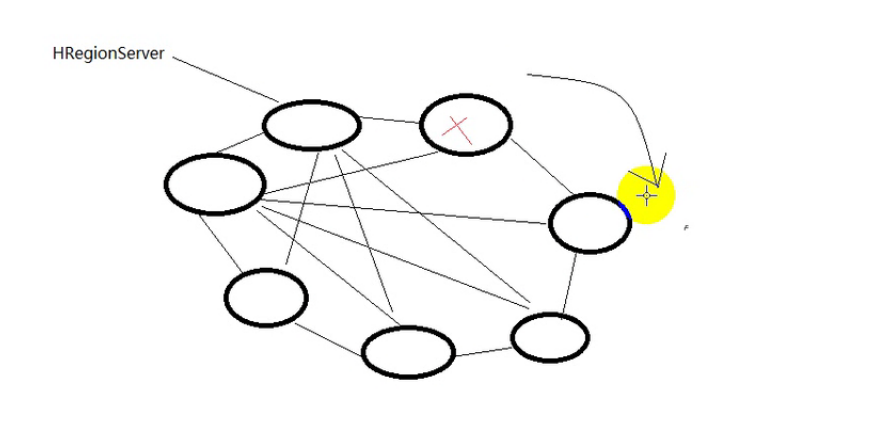
问题:
主备Master选举: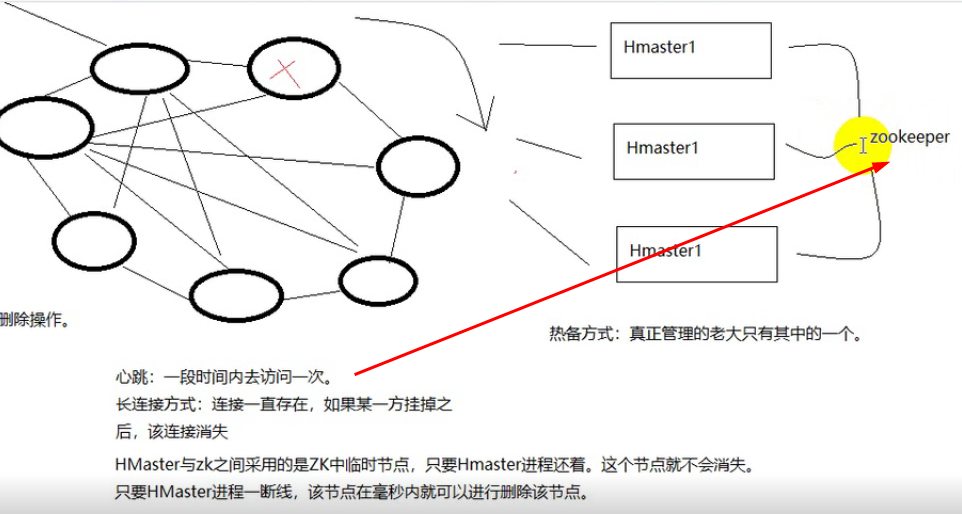
zookeeper在hbase中的集成:
HRegionServer(区域服务器)
- 一个表可以按照行键(rowkey)分割为多个region,且region可以分布在不同的HRegionServer中。
- 每个表最初只有一个region,当记录数增加到超过某个阈值时,开始分裂为两个region。
- 物理上所有数据存放在HDFS,由RegionServer提供region的管理。
- 一个HRegionServer可以管理多个region实例和多个HLog。
- HRegionServer所代表是一台服务器,一般和NameNode在同一台。
问题:为什么要在同一台?
因为HBase的真是数据存储在hdfs上,如果在同一台的话,可以节省传输时间(也称为数据的本地化访问) - region与regionServer的关系
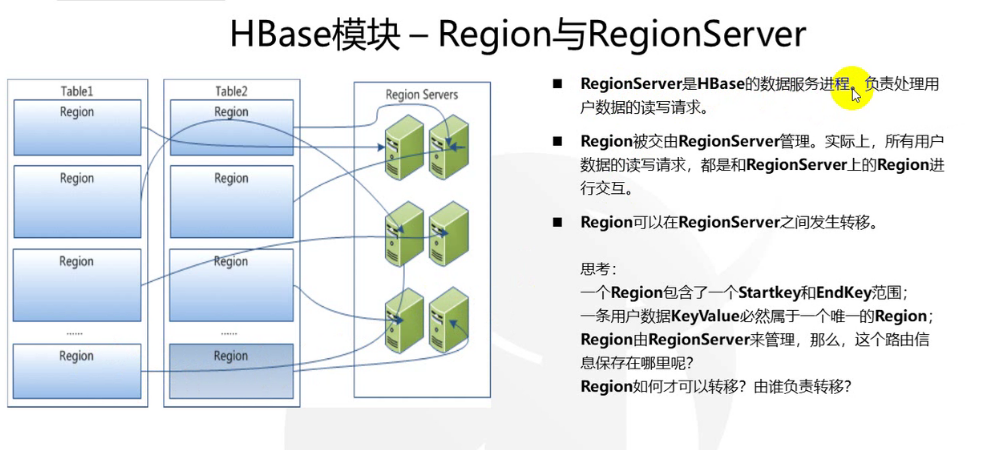
类似于图书馆借书的思想。
由hmaster负责,它只动口不动手,具体动手由zookeeper负责进行转移。
如何转移?
1.先看看表的信息存储方式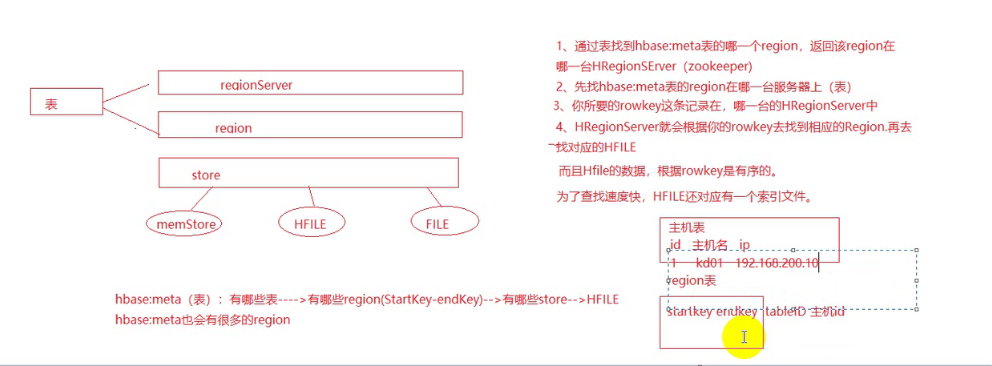
2.在看看如何转移
HRegion(地区)
- 一个HRegion至少有一个Store(即表只有一个列族的情况)。
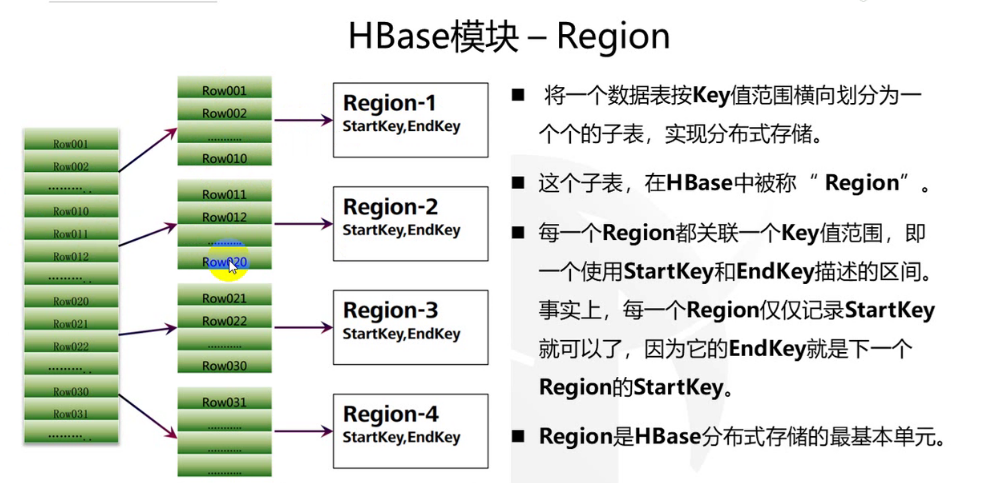
- 一个HRegion至少有一个Store(即表只有一个列族的情况)。
Store(商店)
- 在一个HRegion中,一个store代表一个列族的内容。
- Store的内容可以存储在不同的HRegionServer中。
问题:HBase可以有多个列族,但是只建议使用一个列族?
原因就是,store对应一个列族,但是一个表的多个列族对应的多个store可以放在不同的HRegionServer中,所以如果用户跨列族访问,将有可能读取一行数据的时候需要访问多台HRegionServer。 - 一个Store包含MemStore和HFile。
- MemStore:内存存储
当用户put一条数据的时候,该数据会被先放到memstore中,当值达到一定的大小的时候,会flush成一个StoreFile文件。
如:我们向hbase中put多条数据的时候(在一张新表当中),你的hdfs上将没有任何的内容。 HFile:意思和storeFile代表的是同一个东西。
- 当storefile文件的数量增加到一定阈值后,系统会进行合并,在合并过程中会进行版本合并和删除工作,形成更大的storefile。
- 当storefile大小超过一定阈值后,会把当前的region分割为两个,并由HMaster分配到相应的region服务器,实现负载均衡。
- 客户端检索数据时,现在memstore找,找不到再找storefile。
HFile的产生:
- memStore的大小达到指定值的时候会生成一个HFile。
- 用户手动执行flush操作。
- 用户执行stop-hbase.sh。
- memstore挂掉,从Hlog恢复数据的时候,也会产生一个新的Hfile。
- 问题:目前这种架构有一个问题:如果用户写入到memstore之后,还没有flush的时候,断电了怎么办?
所以引入了一个新的概念:HLOG(WALS)预写式日志
当用户在写入数据的时候,需要同时写入到memstore和Hlog都成功的时候,用户才能够看到操作成功。一般情况下Hlog的写入速度高于Hfile。在整个架构中,如果HBase一切正常工作的话,Hlog将不会提供提供读取的作用。
Hlog存在意义:当memstore挂掉的时候,有数据丢失的话,将会从Hlog中拿取数据出来,写入成一个Hfile。 - HLog:灾难备份,预写式日志,记录所有更新操作,操作先记录进日志,数据才会写入
- Zookeeper在HBase担任的职能

建表的时候如何分配region? — 3种
- 一般情况下,我们在建表之后,会默认生成一个region,当数据达到一定之后,HRegionServer会将region在分成两个region。【动态分配】
- 但是有时候我们已经知道了HRegionServer的数量时,可以采用固定的region分区:
不管数据怎么增加,region的数量都不会进行改变。
create 'emloyee','01', {NUMREGIONS => 3 ,SPLITALGO => 'HexStringSplit'}每一个region会包含startkey和endkey第一个region的startkey为空最后一个region的endKey为空每一个region的endkey是不包含在当前region的3. 当确定rowkey的范围时,可以采用以下的方式create 'emloyee','e1',SPLITS => ['10','20','30','40']会创建出5个region
- 客户端client

- HBase的容错性

配置HMaster主备: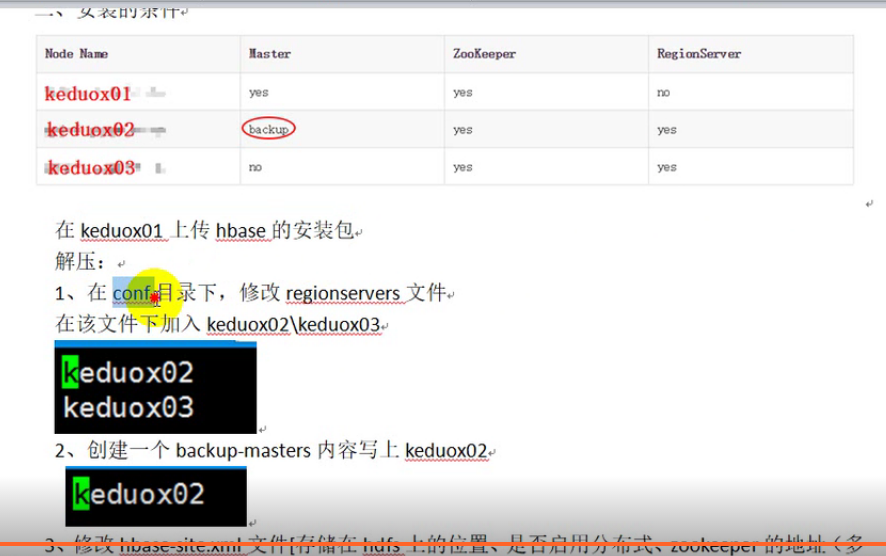
- Java操作hbase:Java操作hbase




























还没有评论,来说两句吧...