机器学习 模型评估
- 交叉验证
- Baseline 模型
-
- ROC 曲线
- Confusion Matrix
交叉验证
from sklearn.preprocessing import StandardScalerfrom sklearn.pipeline import make_pipelinefrom sklearn.linear_model import LogisticRegressionfrom sklearn.model_selection import KFold, cross_val_scorefrom sklearn.datasets import load_digits# 加载数据 (手写数字图像)digits = load_digits()features = digits.datatarget = digits.target# 创建一个流水线, 流水线由# 将输入特征变换为0均值,1方差的缩放器# 逻辑回归模型# 组成pipeline = make_pipeline(StandardScaler(), LogisticRegression())# 交叉验证, Fold=10cv_res = cross_val_score(pipeline, features, target, cv=KFold(10, shuffle=True, random_state=1), scoring='accuracy', n_jobs=-1)print(cv_res.mean())
Baseline 模型
数值型baseline
from sklearn.datasets import load_bostonfrom sklearn.linear_model import LinearRegressionfrom sklearn.preprocessing import train_test_splitfrom sklearn.dummy import DummyRegressorfrom sklearn.model_selection import train_test_split# 加载数据boston = load_boston()features, target = boston.data, boston.targetx_train, x_test, y_train, y_test = train_test_split(features, target, test_size = 0.2)# 预处理, 缩放数据std_scaler = StandardScaler()std_scaler.fit(x_train)x_train = std_scaler.transform(x_train)x_test = std_scaler.transform(x_test)# baselien modelbaseline = DummyRegressor(strategy='mean')baseline.fit(x_train, y_train)baseline.score(x_test, y_test)# 得分 -0.05# my modelclf = LinearRegression()clf.fit(x_train, y_train)clf.score(x_test, y_test)# 得分 0.74
分类型baseline
from sklearn.datasets import load_irisfrom sklearn.preprocessing import StandardScalerfrom sklearn.model_selection import train_test_splitfrom sklearn.dummy import DummyClassifierfrom sklearn.linear_model import LogisticRegression# 加载数据iris = load_iris()features, target = iris.data, iris.targetx_train, x_test, y_train, y_test = train_test_split(features, target, test_size = 0.2)# 预处理std_scaler = StandardScaler()std_scaler.fit(x_train)x_train = std_scaler.transform(x_train)x_test = std_scaler.transform(x_test)# baselinebaseline = DummyClassifier(strategy='stratified', random_state=1)baseline.fit(x_train, y_train)print(baseline.score(x_test, y_test))# 得分 0.4# my modelclf = LogisticRegression(solver='lbfgs', multi_class='auto')clf.fit(x_train, y_train)clf.score(x_test, y_test)# 得分 0.97
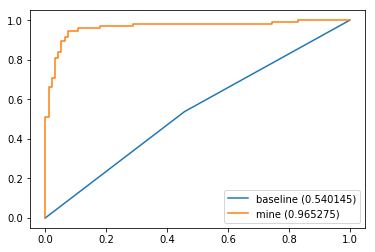
ROC 曲线
from sklearn.datasets import make_classificationfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import roc_curve, roc_auc_scorefrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerfrom sklearn.dummy import DummyClassifierimport matplotlib.pyplot as plt%matplotlib inlinefeatures, target = make_classification(n_samples = 1000, n_features = 10, n_informative = 2, n_classes = 2)x_train, x_test, y_train, y_test = train_test_split(features, target, test_size = 0.2)std_scaler = StandardScaler()std_scaler.fit(x_train)x_train = std_scaler.transform(x_train)x_test = std_scaler.transform(x_test)baseline = DummyClassifier(strategy='stratified')baseline.fit(x_train, y_train)y_pred = baseline.predict_proba(x_test)[:,1]fp, tp, threshold = roc_curve(y_test, y_pred)plt.plot(fp, tp, label='baseline (%f)' % roc_auc_score(y_test, y_pred))clf = LogisticRegression(solver='lbfgs')clf.fit(x_train, y_train)y_pred = clf.predict_proba(x_test)[:,1]fp, tp, threshold = roc_curve(y_test, y_pred)plt.plot(fp, tp, label='mine (%f)' % roc_auc_score(y_test, y_pred))plt.legend()
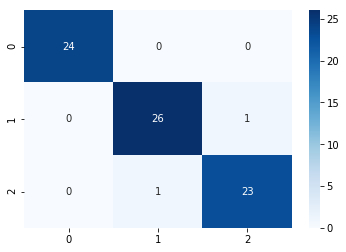
Confusion Matrix
from sklearn.datasets import load_irisfrom sklearn.preprocessing import StandardScalerfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import confusion_matrixfrom sklearn.linear_model import LogisticRegressionimport seaborn as sns# 加载数据iris = load_iris()features, target = iris.data, iris.targetx_train, x_test, y_train, y_test = train_test_split(features, target, test_size = 0.5)# 预处理std_scaler = StandardScaler()std_scaler.fit(x_train)x_train = std_scaler.transform(x_train)x_test = std_scaler.transform(x_test)# my modelclf = LogisticRegression(solver='lbfgs', multi_class='auto')clf.fit(x_train, y_train)y_pred = clf.predict(x_test)sns.heatmap(confusion_matrix(y_test, y_pred), annot=True, cmap='Blues')



























![洛谷 P1169 [ZJOI2007]棋盘制作](https://image.dandelioncloud.cn/images/20230808/72ba490c52904facb1bad28940d1f12a.png "洛谷 P1169 [ZJOI2007]棋盘制作")





还没有评论,来说两句吧...