【tensorflow】tensorflow相关基础概念
参考极客时间 彭靖田老师:TensorFlow快速入门与实战
课程链接
0 数据流图
TensorFlow 是一个编程系统, 使用图来表示计算任务。图中每个节点称作operation。
通过一个可执行队列,借助拓扑排序的方式,把所有入度为0的节点放入执行队列中,每执行一个节点,就会更新它的入度和所连接的节点,然后执行下一层次入度为0的执行队列,可以进行并行运算。
0.1 有向边:数据流向
- 张量(Tensor):使用高维数组表示数据。
- 稀疏张量(SparseTensor):有意义的数值存下来索引和值。然后存下来矩阵形状,不用把所有的值都存下来。
0.2 节点:
- 计算节点(Operation):计算操作,逻辑操作等
- 存储节点(Variable):变量,训练对象等,存储迭代更新的数据
- 数据节点(Placeholder):描述额外输入的数据
1 基本结构
1.1 张量(Tensor)
就是标量,向量,数组,多维数组的通用表示说法。
张量的描述有两个重要属性:
- 数据类型(内部数据类型要一样)
数组形状
Tensor(“Const:0”, shape=(1,), dtype=float32)
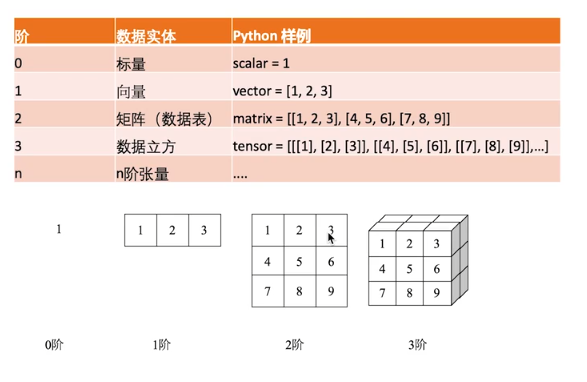
常见的张量操作:
- tf.constant() 常量,不可变
- tf.Variable() 变量,运行中一直在内存中
tf.placeholder() 先占位,高维数据壳
animal = tf.Variable(“dog”, tf.string)
num = tf.Variable(451, tf.int32)
类型:tf.float,tf.string,tf.int,tf.complex,tf.bool
声明张量的时候要给定数据和类型。也可以指定在tensorflow里的名字name=’’,不是变量名
张量的阶和维度
注意看 shape=()里面的部分,里面有几个数就是几阶,然后看数的内容判断数据维度和每维的结构。
0阶和1阶
# 0 阶 数学标量 shape为空pai = tf.Variable(3.14159265359, tf.float64)<tf.Variable 'Variable_1:0' shape=() dtype=float32_ref># 1阶 数学向量,shape里一个数,数5表示5个元素first_primes = tf.Variable([2, 3, 5, 7, 11],tf.int32)<tf.Variable 'Variable_2:0' shape=(5,) dtype=int32_ref>
2 阶和 3 阶
# 2 阶数组,shape里两个数,表示第1维2个元素,下一维每维1个数m = tf.Variable([[6],[12]], tf.int32)<tf.Variable 'Variable_3:0' shape=(2, 1) dtype=int32_ref># 3 阶,shape里3个数,3维,数表示每个维度对应的元素个数aaa = tf.Variable([[[1,2],[3,4]],[[1,2],[3,4]]],tf.int32,name='aaa')<tf.Variable 'aaa_6:0' shape=(2, 2, 2) dtype=int32_ref>
1.2 变量(Variable)
普通的张量(Tensor)在计算结束后内存就会被释放,变量会被保存在内存之中,每一步训练的时候进行迭代更新。
创建
w = tf.Variable(value,type,name)W = tf.Variable(tf.random_normal(shape=(1, 4), mean=100, stddev=0.5), name="W")b = tf.Variable(tf.zeros([4]), name="b")[<tf.Variable 'W_4:0' shape=(1, 4) dtype=float32_ref>,<tf.Variable 'b_4:0' shape=(4,) dtype=float32_ref>]
重新赋值
w.assign(1.0)w.assign_add(2.4)
变量的使用图: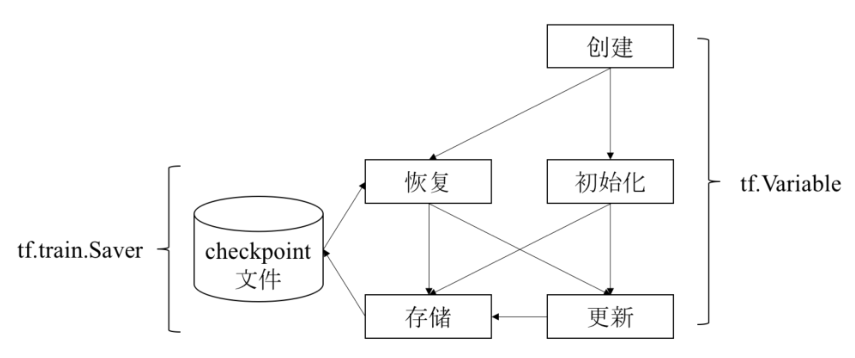
变量保存与使用(Saver):
创建
saver = tf.train.Saver({'W': W, 'b': b})saver = tf.train.Saver([v1, v2])saver = tf.train.Saver({v.op.name: v for v in [v1, v2]})
保存变量
saver.save(sess, 'MODEL_SAVE_PATH', global_step=global_step)
复用变量
saver.restore(sess, ckpt.model_checkpoint_path)
变量创建后启动sess会话后必须经过初始化(init_op):
init_op = tf.initialize_all_variables()
恢复数据流图的图结构:tf.train.import_meta_graph,还有索引index等恢复方法。
1.3 操作(operation)
数据流图中的节点对应一个具体的操作,是模型训练运行的实际载体。包含存储、计算和数据节点。
- 存储:放模型参数,存储有状态的变量
- 数据:占位描述输入数据属性,之后喂数据
- 计算:运算控制操作,负责逻辑表达流程控制
在数据流图里,操作的输入和输出都是张量,所以在图内需要使用TF的指定函数来查看某一个变量的值。数据流图输入的训练和测试数据需要用占位操作符提前声明。
name = tf.placeholder(dtype, shape, name)x = tf.placeholder(tf.int32, shape=(), name="x")
在内部用字典的形式填充数据(Feed)后需要run执行才能更新值:
with tf.Session() as sess:print(sess.run(add, feed_dict={x: 10, y: 5}))
常用的操作: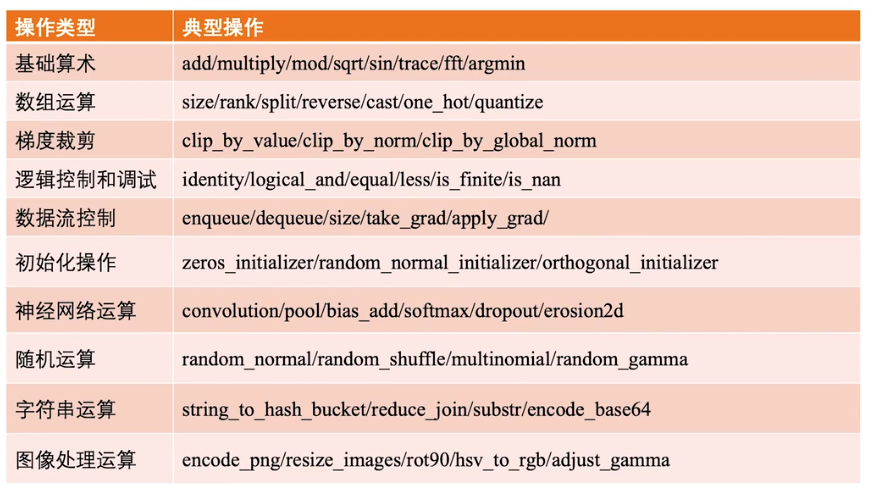
1.4 会话(Operation)
就是一个运行环境,分配资源去真正执行运算操作,之前只是声明了规则和值,并没有真的把值赋给变量。
创建会话:
sess = tf.Session()with tf.Session() as sess:
初始化全局变量
init = tf.initialize_all_variables()sess.run(init)#或 sess.run(tf.global_variables_initializer())
更新运算
for step in stepsepoch:sess.run(train_op计算式、节点、变量)
关闭会话
sess.close()
先更新值,更新了之后要sess.run()才能取出来值。
sess.run(tf.assign_add(b, [1, 1, 1, 1]))sess.run(b)array([1., 1., 1., 1.], dtype=float32)
如果之前数据是使用占位符placeholder定义的变量,在会话里run的时候要真正喂入feed_dict数据。
feed_dict = {images_placeholder: images_feed,labels_placeholder: labels_feed,} #占位的字典,用来作为每轮batch喂入的数据with tf.Session() as sess:print(sess.run(mul, feed_dict={x: 2, y: 3}))
也可以使用估算张量Tensor.eval()和Operation.run()的形式执行,他们最终都是调用的底层:Sess.run()
tf.global_variables_initializer().run() # Operation.runfetch = y.eval(feed_dict={x: 3.0}) # Tensor.evalprint(fetch) # fetch = w * x + b
可以指定某个执行模块是用GPU\CPU哪个执行的:
#存储用CPUwith tf.device("/cpu:0"):v=tf.Variable(...)# 大规模运算用GPUwith tf.device("/gpu:0"):z=tf.matmul(x,y)
1.5 优化器(Optimizer)
模型的优化目标:降低损失函数loss。
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits,onehot_labels,name='xentropy')#比较前向推理计算输出和one-hot化标签的距离loss = tf.reduce_mean(cross_entropy, name='xentropy_mean')
一般使用迭代求解,设定一个初始解,然后基于特定函数模型计算可行解,直到找到最优解或者达到预设收敛条件。
不同优化算法的迭代策略不同:常见牛顿法、梯度下降法、Adam等。
optimizer = tf.train.GradientDescentOptimizer(FLAGS.learning_rate)global_step = tf.Variable(0, name='global_step', trainable=False)# 保存全局训练步数train_op = optimizer.minimize(loss, global_step=global_step)
优化器的使用步骤:计算梯度》处理梯度()》应用梯度。
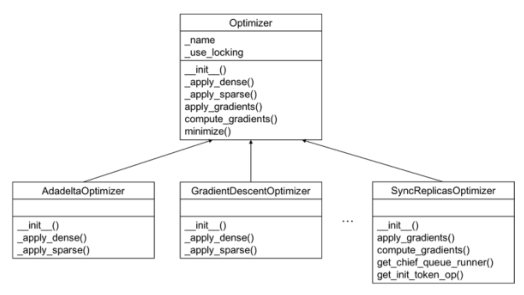
常用优化器: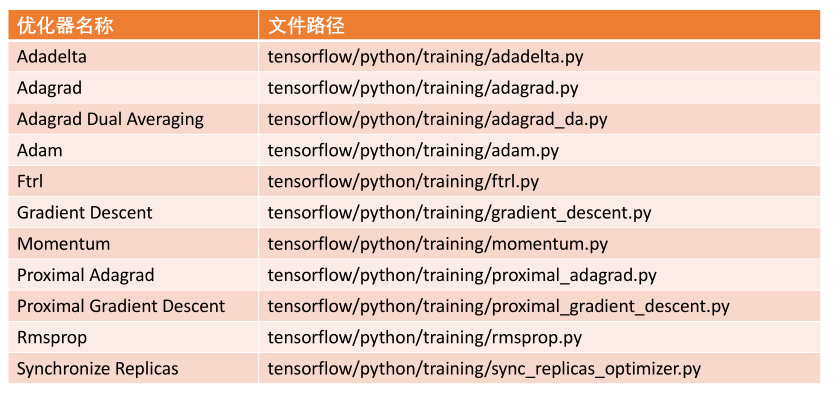
1.6 评估函数
传入的logits和标签参数要与loss函数的一致。
eval_correct = mnist.evaluation(logits, labels_placeholder)
在K个最有可能的预测中可以发现真的标签,那么这个操作就会将模型输出标记为正确。
eval_correct = tf.nn.in_top_k(logits, labels, 1)
准确率:
true_count += sess.run(eval_correct, feed_dict=feed_dict)precision = float(true_count) / float(num_examples)
2 TensorBoard 可视化工具
数据处理过程中可视化工具,帮助理解算法提升工作效率。
- 查看数据集分布
- 数据流图是否正确实现
- 模型参数和超参数变化趋势
- 查看评估指标
使用
使用时需要从会话(session)中加载,然后使用FileWriter实例写入事件文件,最后加载到Tensorboard获取实例文件中的序列化数据进行展示。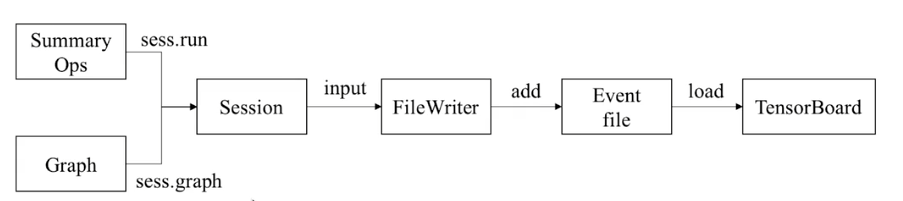
2.1 典型应用形式:
1)首先创建数据流图:
可以使用tf.name_scope()抽象层节点。
展示的时候可以将一些节点进行抽象,使输出TF图像看起来层次关系更明确,之后可以再将抽象层的细节展开显示。
#只需要定义的时候将参数变量声明放置在指定的抽象节点之下。With tf.name_scope('name'):定义变量。。。。。w = tf。。。。。。。。。
2)然后创建FileWriter实例
创建filewriter实例,加载到当前数据流图(graph):
tf.reset_default_graph()writer = tf.summary.FileWriter(savepath,sess.graph)
在数据流图会话(sess)中加载的实例写入到eventfile之中,写完需要关闭FileWriter的输出流:
writer.close()
3)启动tensorboard
将eventfile所在的目录传给tensorboard,能够获取相关的参数可视化展示。需要制定文件位置和打开的host。
tensorboard --logdir ./ --host localhost
默认本地位置,打开浏览器复制进去地址就可以。
可能出现的问题
windows10 打开tensorboard 遇到的问题,在浏览器打开提示没有图(不能用360,用Chrome)。No scalar data was found.
找到文件保存的位置:
writer = tf.summary.FileWriter(r'D:\project\UCIPre\summary\lr2', sess.graph)
进入cmd,cd到最后一级文件夹上一级,转到文件夹下后直接用logdir=最后name名。
cd D:\project\UCIPre\summary\summary>tensorboard --logdir=lr2
刚开始用的anaconda prompt 一直提示打不开,用cmd就可以了。
奇葩的是时好时坏。
2.2 官方文档推荐形式
1)创建事件文件
所有的即时数据都要在图表构建阶段合并至一个操作(op)中。
summary_op = tf.merge_all_summaries()
2) 实例化FileWriter
在创建好会话(session)之后,可以实例化一个tf.train.SummaryWriter,用于写入包含了图表本身和即时数据具体值的事件文件。
summary_writer = tf.train.SummaryWriter(FLAGS.train_dir,graph_def=sess.graph_def)
3)写入最新的数据
每次运行summary_op时,都会往事件文件中写入最新的即时数据,函数的输出会传入事件文件读写器(writer)的add_summary()函数。
summary_str = sess.run(summary_op, feed_dict=feed_dict)summary_writer.add_summary(summary_str, step)
参考:中文手册
动手实现一个简单的全连接神经网:
只看 Fullnet.py 部分即可。 girhub文件
简单的TF网络测试mnist:github链接


































还没有评论,来说两句吧...