Python3.x爬取网易云音乐歌单
Python3.x爬取网易云音乐歌单
该篇紧紧是作为入门练手使用,爬取功能不包含收费音乐,也不包含无损音乐,完整代码在文章末。
分析
1. 获取请求头 header
用抓包工具fiddler/charles抓包,抓出歌单的请求头header信息。在代码中已经写好,可省去该步骤。
2. 分析歌单链接信息
打开一个歌单,地址是这样的https://music.163.com/#/playlist?id=2944697443
我们把这个链接换成http,然后去掉/#http://music.163.com/playlist?id=2944697443
该链接同样指向该歌单地址,我们使用这个地址。
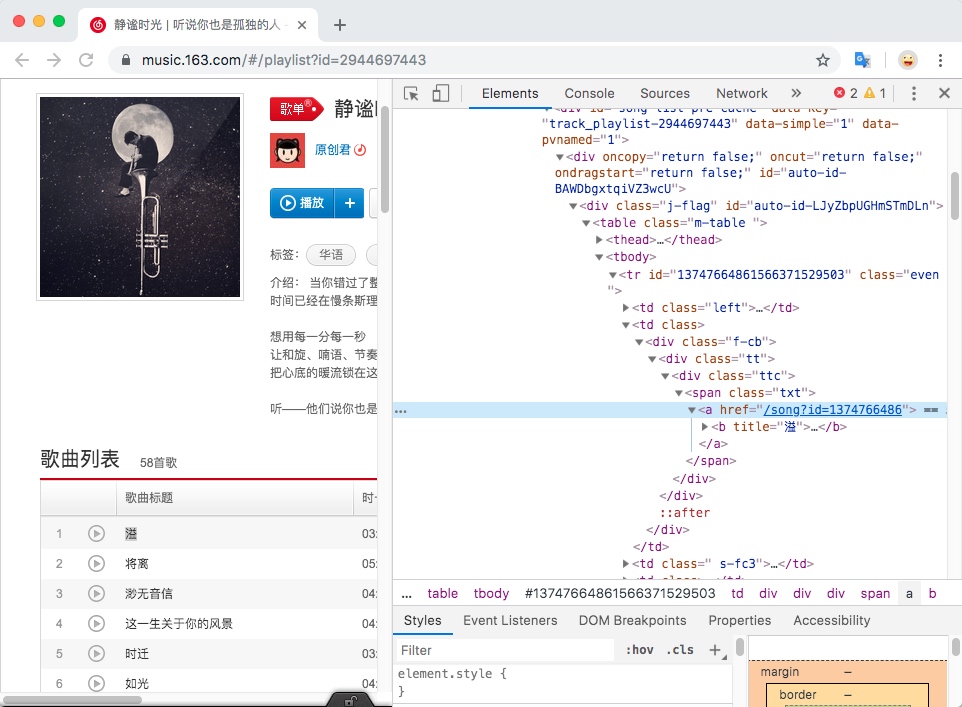
3. 获取每首音乐的ID
用浏览器打开歌单的链接,将鼠标移至某个音乐上点检查,就能看到歌曲的id信息。如图。
4. 音乐的外链地址
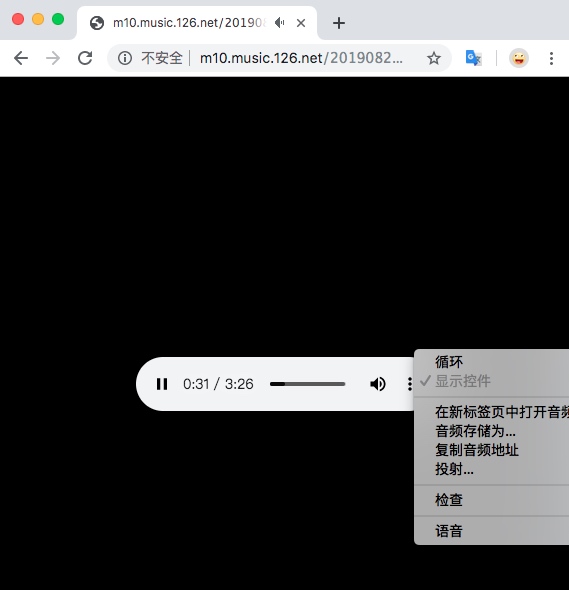
网易云音乐的mp3文件的外链地址
http://music.163.com/song/media/outer/url?id=1374766486.mp3
根据该地址分析,我们更换不同id即可
该地址在浏览器中效果,如下图
该步骤,值得注意的是,根据外链mp3地址访问后,会有一个重定向,所以代码中也需要加上。
5. 保存mp3文件即可
完整代码
#! python3#encoding=utf8import requestsfrom bs4 import BeautifulSoupimport urllib.requestheaders = {'Referer':'http://music.163.com/','Host':'music.163.com','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',}play_url = 'http://music.163.com/playlist?id=2308326138's = requests.session()response=s.get(play_url,headers = headers).content#print(response) 整个html源文件s = BeautifulSoup(response,'lxml')#print(s)main = s.find('ul',{'class':'f-hide'})#print(main)lists=[]for music in main.find_all('a'):#print('{} : {}'.format(music.text, music['href']))list=[]musicUrl='http://music.163.com/song/media/outer/url'+music['href'][5:]+'.mp3'musicName=music.text# 单首歌曲的名字和地址放在list列表中list.append(musicName)list.append(musicUrl)# 全部歌曲信息放在lists列表中lists.append(list)print(lists)# 重定向代码def get_redirect_url(url):# 重定向前的链接# url = "重定向前的url"# 请求头,这里我设置了浏览器代理headers = {'Referer':'http://music.163.com/','Host':'music.163.com','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',}# 请求网页response = requests.get(url, headers=headers)# print(response.status_code) # 打印响应的状态码# print(response.url) # 打印重定向后的网址# 返回重定向后的网址return response.url#下载列表中的全部歌曲,并以歌曲名命名下载后的文件,文件位置为当前文件夹for i in lists:url=i[1]name=i[0]try:print('正在下载',name)# 直接下载会失败,把类似链接放入浏览器中发现自动重定向了一个地址。来模拟下重定向# 事先要自己手动创建一个 ‘wangyi’ 的文件夹哦# urllib.request.urlretrieve(url,'./%s.mp3'% name)urllib.request.urlretrieve(get_redirect_url(url),'./wangyi/%s.mp3'% name)print('下载成功')except:print('下载失败')




























还没有评论,来说两句吧...