毕设总结2:使用python scrapy 爬取 网易云音乐
网易云音乐爬取教程
- 爬取网易云热歌榜
- 分析网页结构
爬取网易云热歌榜
分析网页结构
先还是通过 [scrapy genspider music https://music.163.com/discover/toplist?id=3778678] 创建scrapy爬虫默认模板。参考毕设总结1
然后把目标url(api)放在这里:网易云热歌榜传送门
首先分析以下歌曲名:
这里我用css选择器去匹配这个b标签,
response.css('.txt a b::attr(title)').extract()

但是这里出现了问题,显然他的数据是通过js动态加载的,所以需要找出api。
后来通过上网发现,其实歌曲数据都放在textarea中
str_data = response.css("textarea::text").extract()[0]
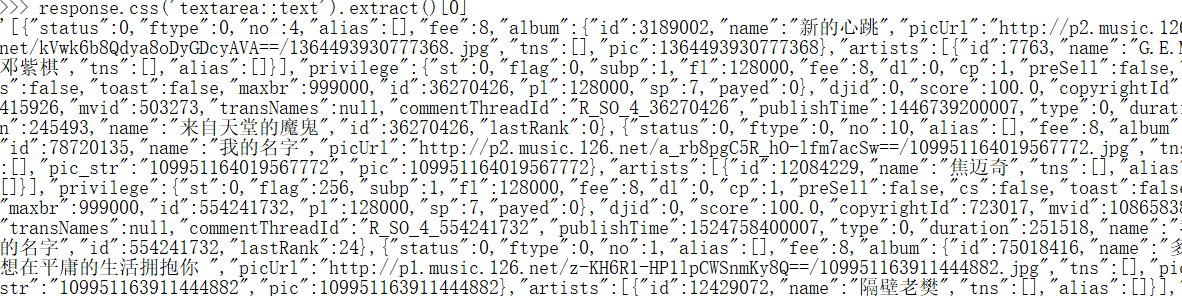
获取到歌曲信息后,需要把str转换成json,然后遍历获取想要的数据。
部分的代码:
import scrapyfrom datetime import datetimeimport jsonimport timefrom ArticleSpider.items import MusicItemclass MusicSpider(scrapy.Spider):name = 'music'allowed_domains = ['music.163.com/discover/toplist?id=3778678']start_urls = ['https://music.163.com/discover/toplist?id=3778678']headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}def parse(self, response):music_item = MusicItem()update_time = response.css(".user span::text").extract()[0] # 榜单发布时间update_time = update_time.replace("最近更新:", "")str_data = response.css("textarea::text").extract()[0]json_data = json.loads(str_data)for i in range(len(json_data)):if json_data[i].get('publishTime') != 0:t1 = time.localtime(json_data[i].get('publishTime')/1000)publish_time = time.strftime("%Y-%m-%d %H:%M:%S", t1) # 发行时间else:publish_time = "2019-01-01"song_time = json_data[i].get('duration')/1000 # 歌曲时长song_time_min = str(song_time/60)song_time_min = song_time_min.split(".")[0]song_time_sec = str(song_time - int(song_time/60)*60)song_time_sec = song_time_sec.split(".")[0]if len(song_time_sec)<2:song_time_sec = '0'+str(song_time_sec)# song_time_sec = song_time_sec[0:2]if len(song_time_min)<2:song_time_min = '0'+str(song_time_min)song_time = song_time_min+":"+song_time_sec# print(song_time)# 歌手artist = json_data[i].get('artists')[0].get('name')# 歌手idartist_id =json_data[i].get('artists')[0].get('id')# 歌名music_name = json_data[i].get('name')# 音乐idmusic_id = json_data[i].get('id')# 音乐下载地址music_down_url = "http://music.163.com/song/media/outer/url?id="+str(music_id)+".mp3"# 歌曲urlmusic_url = "https://music.163.com/song?id="+str(music_id)# 专辑album = json_data[i].get('album').get('name')# 专辑图urlpic_url = json_data[i].get('album').get('picUrl')# 专辑idalbum_id = json_data[i].get('album').get('id')# 排名no = json_data[i].get('no')# 上次排名if json_data[i].get('lastRank'):last_rank = json_data[i].get('lastRank')else:last_rank = "未上榜"crawl_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")music_item["publish_time"] = publish_time # 歌曲发布时间music_item["song_time"] = song_time # 歌曲时长music_item["artist"] = artist # 歌手music_item["artist_id"] = artist_id # 歌手idmusic_item["music_name"] = music_name # 歌名music_item["music_id"] = music_id # 歌曲id idmusic_item["album"] = album # 专辑music_item["pic_url"] = pic_url # 专辑封面图music_item["album_id"] = album_id # 专辑idmusic_item["no"] = no # 本周排名music_item["last_rank"] = last_rank # 上周排名music_item["crawl_time"] = crawl_time # 爬取时间music_item["music_down_url"] = music_down_url # 歌曲下载地址 外链music_item["music_url"] = music_url # 歌曲urlmusic_item["update_time"] = update_time # 榜单发布时间yield music_itempass


































还没有评论,来说两句吧...