Python爬取百度备案信息
Python爬取百度备案信息
首先使用pip install requests和pip install bs4安装两个必备的库(注意:你的lxml可能没有安装,如果运行错误的话尝试使用pip install lxml安装lxml,这个库是解析HTML的)
这里我使用的编译器是Spyder,当然你也可以直接在Python自带的IDE中运行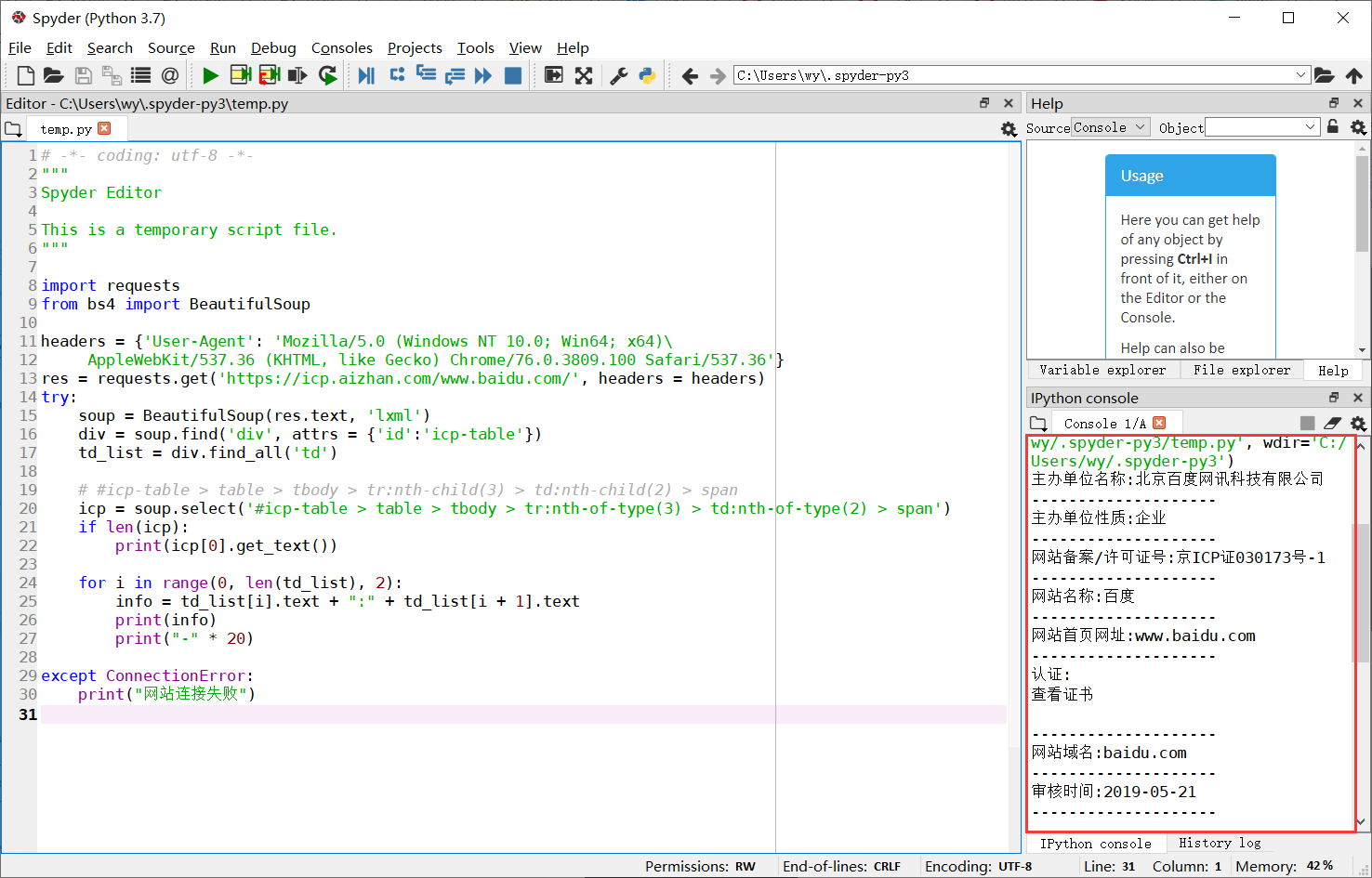
爬虫的核心是
1.伪造请求头
2.获取目标网站的地址
3.找到需要爬取内容的DOM位置
4.进行构造遍历爬取(当然这个爬取备案信息的很简单,不需要各种提取操作)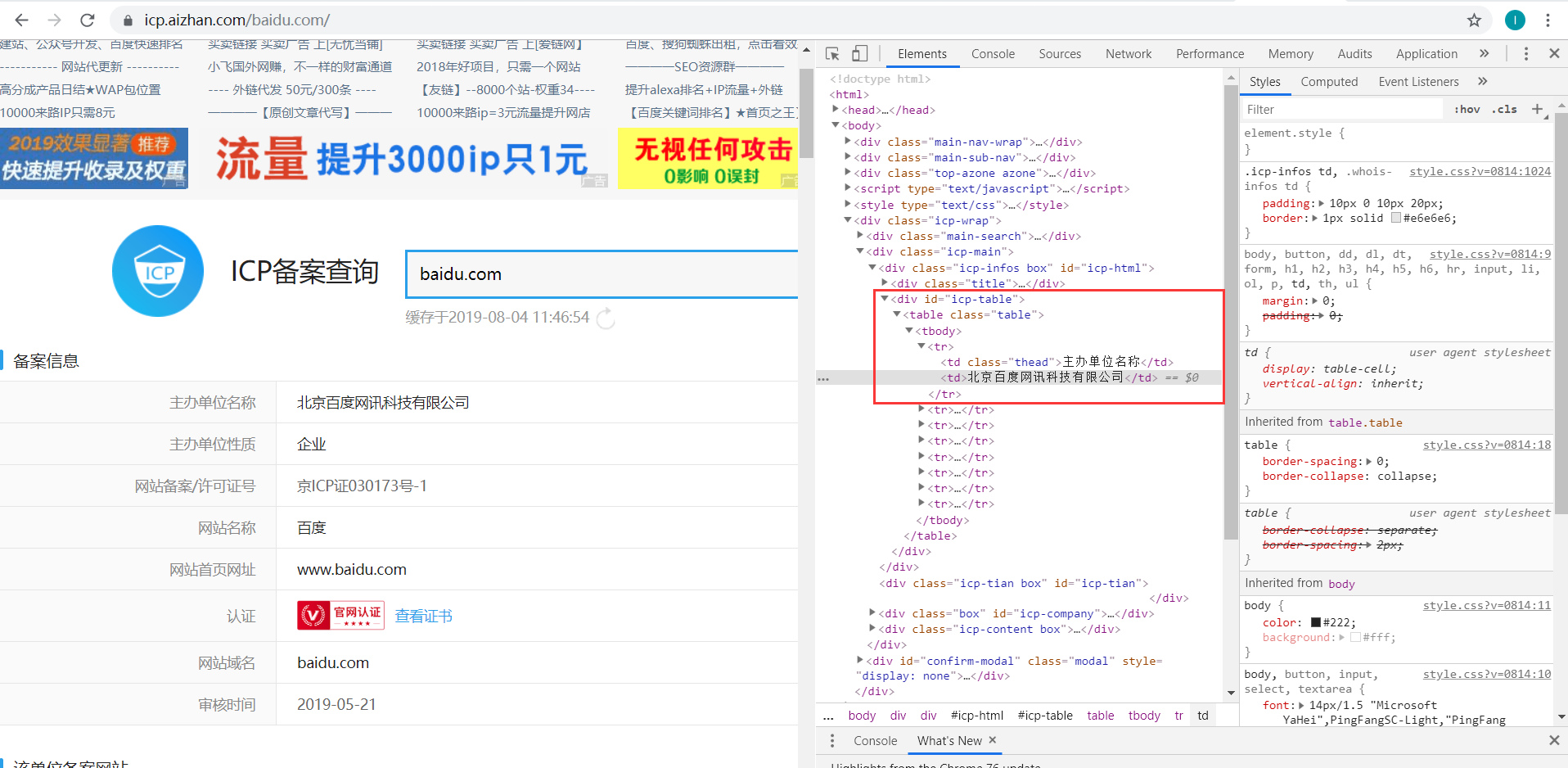
// 完整代码及解释import requestsfrom bs4 import BeautifulSoup//伪造请求头,防止服务器端触发反爬机制headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)\ AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'}//爬取目标网站的地址res = requests.get('https://icp.aizhan.com/www.baidu.com/', headers = headers)try://BeautifulSoup可以读取HTML文件进行解析soup = BeautifulSoup(res.text, 'lxml')//找到需要爬取内容的DOM位置div = soup.find('div', attrs = { 'id':'icp-table'})td_list = div.find_all('td')//使用:nth-child(n) 选择器匹配父元素中的第 n 个子元素//https://icp.aizhan.com/www.baidu.com///icp-table > table > tbody > tr:nth-child(3) > td:nth-child(2) > spanicp = soup.select('#icp-table > table > tbody > tr:nth-of-type(3) > td:nth-of-type(2) > span')if len(icp):print(icp[0].get_text())//遍历 构造打印出来的内容for i in range(0, len(td_list), 2):info = td_list[i].text + ":" + td_list[i + 1].textprint(info)print("-" * 20)except ConnectionError:print("网站连接失败")


































还没有评论,来说两句吧...