排序-堆排序
2019独角兽企业重金招聘Python工程师标准>>> 
在说明堆排序的过程前得先了解什么是堆:
先看下图(来源于java数据结构和算法(第二版)):

堆是个完全二叉树,并且父节点总是大于(小于)它的孩子,因此根节点永远是最大或者最小的元素。
堆排序的方法是将根节点与最后元素进行交换,并将数组容量减1,交换后最后一个元素不断下沉直至找到合适的位置。以上图为例,交换过程如下:
1、将100与5交换
2、将5下沉到合适的位置选出次大的元素,5和90进行比较将90提到根节点位置,然后5和60进行交换,最后5和55进行交换;
3、将数组容量设为12,最后一个元素的下标为11;
4、重复1和2两个步骤直至剩下1个元素为止。
此例就是按照从小到大进行排序,可将该堆称为最大堆,相应的如果元素需按照从大到小进行排序就需要建立最小堆。
由于给定的排序序列一般是无序的,因此首先需将序列转换成堆。试想一下上面第二个步骤能够执行的条件是整个完全二叉树为堆,并且每个子树都为堆,
并且下沉到正确的位置后又是一个新的堆,那么我们可以构想将整个序列当作一个完全二叉树,然后从最后一个子树开始不断调用第二个算法步骤建立新堆。
对于上图而言就是从5号节点所在的子树开始调用下沉算法一直到根节点所在的整个树为止,这样一个堆就建成了。
实际上堆排序算法也是选择排序算法中的一种,因为它每次都从中选择一个最大或者最小的元素依次排列到合适的位置。
时间复杂度分析:
1、数据下沉的时间复杂度与树的高度有关,在每层中都要比较2次,因此时间复杂度为2(h-1),有n个元素的完全二叉树的最大高度h为log(n)+1;
2、每层子树的最大个数为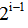 ,因此建堆的时间复杂度为
,因此建堆的时间复杂度为 ,子树的总个数为(n-3)/2
,子树的总个数为(n-3)/2
3、对于上例而言,高度h=4,比较总次数为1*(2*3)+2*(2*2)+ 3*2=20
4、建好堆后,排序的时间复杂度为
5、总的复杂度就是两者之和,有兴趣的将两个公式的和求出个最终结果,可以肯定的是该结果的复杂度是0(nlogn)级别的。
在具体实现时采用数组存储,大家可以直接看lucene中sorter类源码的heapsort方法。
转载于 //my.oschina.net/u/1268334/blog/3013987
//my.oschina.net/u/1268334/blog/3013987





























")




还没有评论,来说两句吧...