kNN算法
from numpy import *import operatordef createDataSet():group=array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])labels=['A','A','B','B']return group,labels#k邻近算法 kNN算法 测试集、数据源(不含结果)、结果标签、邻近数量取值kdef classify0(inX, dataSet, labels, k):#numpy函数shape[0]返回dataSet的行数dataSetSize = dataSet.shape[0]#在列向量方向上重复inX共1次(横向),行向量方向上重复inX共dataSetSize次(纵向)diffMat = tile(inX, (dataSetSize, 1)) - dataSet#二维特征相减后平方sqDiffMat = diffMat**2#sum()所有元素相加,sum(0)列相加,sum(1)行相加sqDistances = sqDiffMat.sum(axis=1)#开方,计算出距离distances = sqDistances**0.5#返回distances中元素从小到大排序后的索引值sortedDistIndices = distances.argsort()#定一个记录类别次数的字典classCount = {}for i in range(k):#取出前k个元素的类别voteIlabel = labels[sortedDistIndices[i]]#dict.get(key,default=None),字典的get()方法,返回指定键的值,如果值不在字典中返回默认值。#计算类别次数classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1#python3中用items()替换python2中的iteritems()#key=operator.itemgetter(1)根据字典的值进行排序#key=operator.itemgetter(0)根据字典的键进行排序#reverse降序排序字典sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)#返回次数最多的类别,即所要分类的类别return sortedClassCount[0][0]group,labels=createDataSet()print(classify0([0,0],group,labels,3))
海伦的约会数据。文本如下
40920 8.326976 0.953952 largeDoses14488 7.153469 1.673904 smallDoses26052 1.441871 0.805124 didntLike75136 13.147394 0.428964 didntLike38344 1.669788 0.134296 didntLike72993 10.141740 1.032955 didntLike35948 6.830792 1.213192 largeDoses42666 13.276369 0.543880 largeDoses67497 8.631577 0.749278 didntLike35483 12.273169 1.508053 largeDoses50242 3.723498 0.831917 didntLike63275 8.385879 1.669485 didntLike5569 4.875435 0.728658 smallDoses51052 4.680098 0.625224 didntLike77372 15.299570 0.331351 didntLike43673 1.889461 0.191283 didntLike61364 7.516754 1.269164 didntLike69673 14.239195 0.261333 didntLike15669 0.000000 1.250185 smallDoses
文本转换
def file2matrix(filename):#打开文件fr = open(filename)#读取文件所有内容arrayOLines = fr.readlines()#得到文件行数numberOfLines = len(arrayOLines)#返回的NumPy矩阵,解析完成的数据:numberOfLines行,3列returnMat = zeros((numberOfLines,3))#返回的分类标签向量classLabelVector = []#行的索引值index = 0for line in arrayOLines:#s.strip(rm),当rm空时,默认删除空白符(包括'\n','\r','\t',' ')line = line.strip()#使用s.split(str="",num=string,cout(str))将字符串根据'\t'分隔符进行切片。listFromLine = line.split('\t')#将数据前三列提取出来,存放到returnMat的NumPy矩阵中,也就是特征矩阵#前面的Index代表第几行,因为这是一个二维的矩阵,后面:前后代表行开始和结束returnMat[index,:] = listFromLine[0:3]#根据文本中标记的喜欢的程度进行分类,1代表不喜欢,2代表魅力一般,3代表极具魅力if listFromLine[-1] == 'didntLike':classLabelVector.append(1)elif listFromLine[-1] == 'smallDoses':classLabelVector.append(2)elif listFromLine[-1] == 'largeDoses':classLabelVector.append(3)index += 1return returnMat, classLabelVector
数据归一化
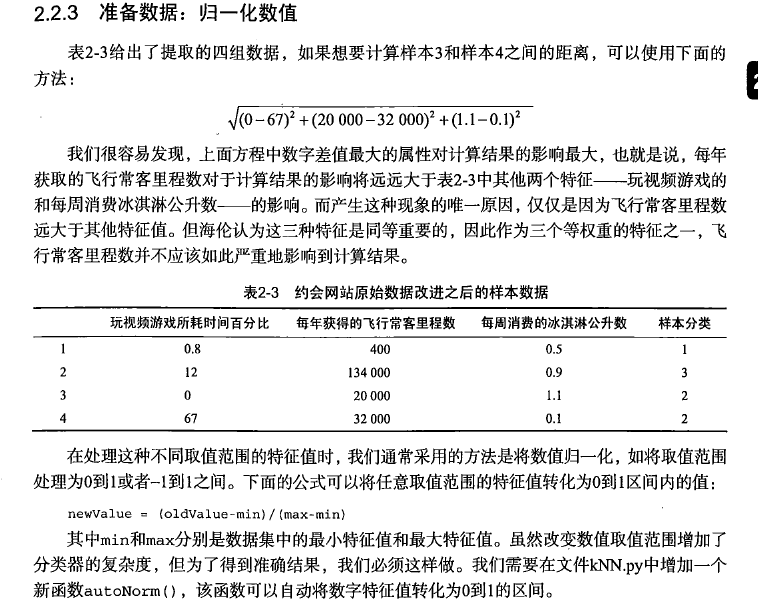
def autoNorm(dataSet):#获得数据的最小值minVals = dataSet.min(0)maxVals = dataSet.max(0)#最大值和最小值的范围ranges = maxVals - minVals#shape(dataSet)返回dataSet的矩阵行列数normDataSet = zeros(shape(dataSet))#返回dataSet的行数m = dataSet.shape[0]#原始值减去最小值normDataSet = dataSet - tile(minVals, (m, 1))#除以最大和最小值的差,得到归一化数据normDataSet = normDataSet / tile(ranges, (m, 1))#返回归一化数据结果,数据范围,最小值return normDataSet, ranges, minVals
分类器针对约会网站的测试代码
def datingClassTest():#打开的文件名filename = "datingTestSet.txt"#将返回的特征矩阵和分类向量分别存储到datingDataMat和datingLabels中datingDataMat, datingLabels = file2matrix(filename)#取所有数据的百分之十hoRatio = 0.10#数据归一化,返回归一化后的矩阵,数据范围,数据最小值normMat, ranges, minVals = autoNorm(datingDataMat)#获得normMat的行数m = normMat.shape[0]#百分之十的测试数据的个数numTestVecs = int(m * hoRatio)#分类错误计数errorCount = 0.0for i in range(numTestVecs):#前numTestVecs个数据作为测试集,后m-numTestVecs个数据作为训练集classifierResult = classify0(normMat[i,:], normMat[numTestVecs:m,:],datingLabels[numTestVecs:m], 4)print("分类结果:%d\t真实类别:%d" % (classifierResult, datingLabels[i]))if classifierResult != datingLabels[i]:errorCount += 1.0print("错误率:%f%%" %(errorCount/float(numTestVecs)*100))def classifyPerson():#输出结果resultList = ['讨厌','有些喜欢','非常喜欢']#三维特征用户输入precentTats = float(input("玩视频游戏所耗时间百分比:"))ffMiles = float(input("每年获得的飞行常客里程数:"))iceCream = float(input("每周消费的冰激淋公升数:"))#打开的文件名filename = "datingTestSet.txt"#打开并处理数据datingDataMat, datingLabels = file2matrix(filename)#训练集归一化normMat, ranges, minVals = autoNorm(datingDataMat)#生成NumPy数组,测试集inArr = array([ffMiles, precentTats, iceCream])#测试集归一化norminArr = (inArr - minVals) / ranges#返回分类结果classifierResult = classify0(norminArr, normMat, datingLabels, 3)#打印结果print("你可能%s这个人" % (resultList[classifierResult-1]))
手写识别系统
def img2vector(filename):# 创建1x1024零向量returnVect = np.zeros((1, 1024))# 打开文件fr = open(filename)# 按行读取for i in range(32):# 读一行数据lineStr = fr.readline()# 每一行的前32个元素依次添加到returnVect中for j in range(32):returnVect[0, 32 * i + j] = int(lineStr[j])# 返回转换后的1x1024向量return returnVectdef handwritingClassTest():# 测试集的LabelshwLabels = []# 返回trainingDigits目录下的文件名# trainingFileList = listdir('trainingDigits')trainingFileList = listdir('trainingDigits')# 返回文件夹下文件的个数m = len(trainingFileList)# 初始化训练的Mat矩阵,测试集trainingMat = np.zeros((m, 1024))# 从文件名中解析出训练集的类别for i in range(m):# 获得文件的名字fileNameStr = trainingFileList[i]# 获得分类的数字classNumber = int(fileNameStr.split('_')[0])# 将获得的类别添加到hwLabels中hwLabels.append(classNumber)# 将每一个文件的1x1024数据存储到trainingMat矩阵中trainingMat[i, :] = img2vector('trainingDigits/%s' % (fileNameStr))# 构建kNN分类器neigh = kNN(n_neighbors=20, algorithm='auto')# 拟合模型, trainingMat为训练矩阵,hwLabels为对应的标签neigh.fit(trainingMat, hwLabels)# 返回testDigits目录下的文件列表testFileList = listdir('testDigits')# 错误检测计数errorCount = 0.0# 测试数据的数量mTest = len(testFileList)# 从文件中解析出测试集的类别并进行分类测试for i in range(mTest):# 获得文件的名字fileNameStr = testFileList[i]# 获得分类的数字classNumber = int(fileNameStr.split('_')[0])# 获得测试集的1x1024向量,用于训练vectorUnderTest = img2vector('testDigits/%s' % (fileNameStr))# 获得预测结果# classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)classifierResult = neigh.predict(vectorUnderTest)print("分类返回结果为%d\t真实结果为%d" % (classifierResult, classNumber))if (classifierResult != classNumber):errorCount += 1.0print("总共错了%d个数据\n错误率为%f%%" % (errorCount, errorCount / mTest * 100))


























")


——LinearLayout、FrameLayout和AbsoulteLayout")
")



还没有评论,来说两句吧...