20 分钟搞定注解
什么是注解?
Java 注解是在 JDK5 时引入的新特性,注解(也被称为元数据)为我们在代码中添加信息提供了一种形式化的方法,使我们可以在稍后某个时刻非常方便地使用这些数据。
注解的本质?
新建一个注解类如:
public @interface myAnotation {}
使用javac命令编译该java文件:
javac myAnotation.java
再使用javap命令反编译calss文件
javap myAnotation.class
结果如下图:

通过反编译这个class文件可以很清晰地看到其实注解默认继承了Anotation接口
一个注解最基本的组成部分
@Target(....)// 1@Retention(...) //2@Documented // 3public @interface Annotation_name { // Annotation_name4// 注解要实现的功能 5}
- @Target()
指定注解的作用域,括号中的值就代表可用在哪些地方,如下枚举类
public enum ElementType {/*** 类、接口(包括注释类型)或枚举声明*/TYPE,/*** 字段声明(包括枚举常量)*/FIELD,/*** 方法声明*/METHOD,...
篇幅问题只展示以上三个作用域
2. @Retention()
注解的生命周期,参数类型为
- RetentionPolicy.SOURCE
- RetentionPolicy.CLASS
RetentionPolicy.RUNTIME
public enum RetentionPolicy {
/*** Annotations are to be discarded by the compiler.编译时将会被丢弃*/SOURCE,/*** Annotations are to be recorded in the class file by the compiler* but need not be retained by the VM at run time. This is the default* behavior.注解将由编译器记录在类文件中,但不需要在运行时被VM保留。这是默认值行为*/CLASS,/*** Annotations are to be recorded in the class file by the compiler and* retained by the VM at run time, so they may be read reflectively.注解将由编译器记录在类文件中,并在运行时由VM保留,因此可以反射地读取它们** @see java.lang.reflect.AnnotatedElement*/RUNTIME
}
3. @Documented
在自定义注解的时候可以使用@Documented来进行标注,如果使用@Documented标注了,在生成javadoc的时候就会把@Documented注解给显示出来,只是用来做标识,没什么实际作用,了解就好。
注解的属性返回数据类型
通过上文我们知道注解其实就是一个默认继承Anotation接口的接口,在注解中成员变量和成员方法也称为注解的属性,注解的属性返回值只能为八大基本数据类型、数组、String、枚举及以上类型的数组 如下:
//本注解可以使用在类上@Target(ElementType.TYPE)@Retention(RetentionPolicy.RUNTIME)public @interface myAnotation {String name();// 定义注解属性默认值为12int age() default 12;// 定义一个数组,使用时必填String[] like();// 定义一个数组,默认为空,使用时选填String[] boll() default {};// 定义一个布尔值类型属性boolean isMan() default true;// 定义一个枚举值ElementType TYPE();// 错误定义示范//void show();}
通过反射解析上文自定义注解myAnotation获取注解的属性值:
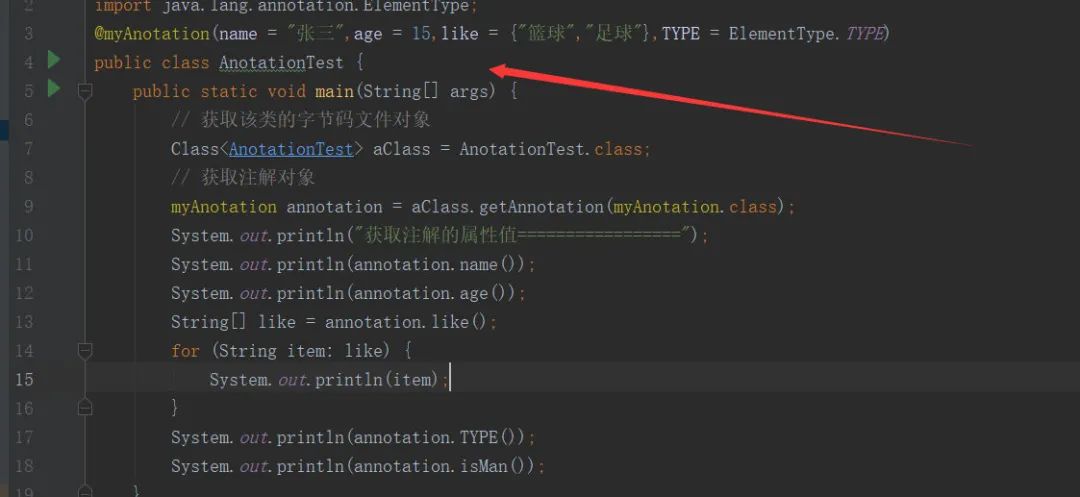
运行结果如图:
通过上文学习,我们对如何定义一个自定义注解和如何获取自定义注解属性值已经有所了解,那现在我们继续往下学习
注解结合Aop使用案例
场景:在自定义注解标记的方法执行前获取到注解属性值
idea新建Spring Initializr 项目,不用添加任何其他依赖(步骤省略)
根据Spirng版本手动新增aop依赖如下:
org.springframework.boot
spring-boot-starter-aop
2.4.5
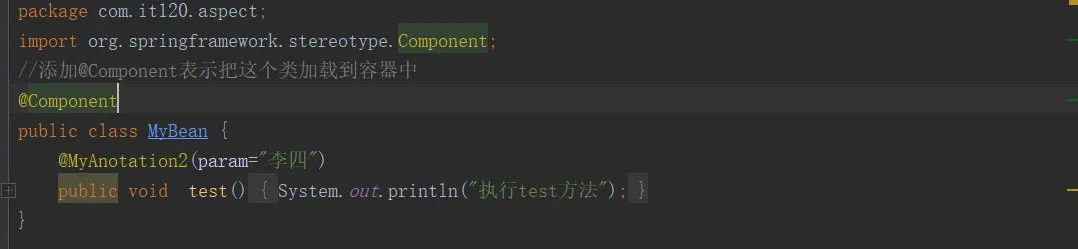
自定义注解:这个注解中我们定义了一个String类型的属性,默认值为“张三”

- 使用注解:在test方法中我们使用了自己的定义的注解并且指定属性值为“李四”,并且在类上添加了@Component注解,这是的意图下文会说
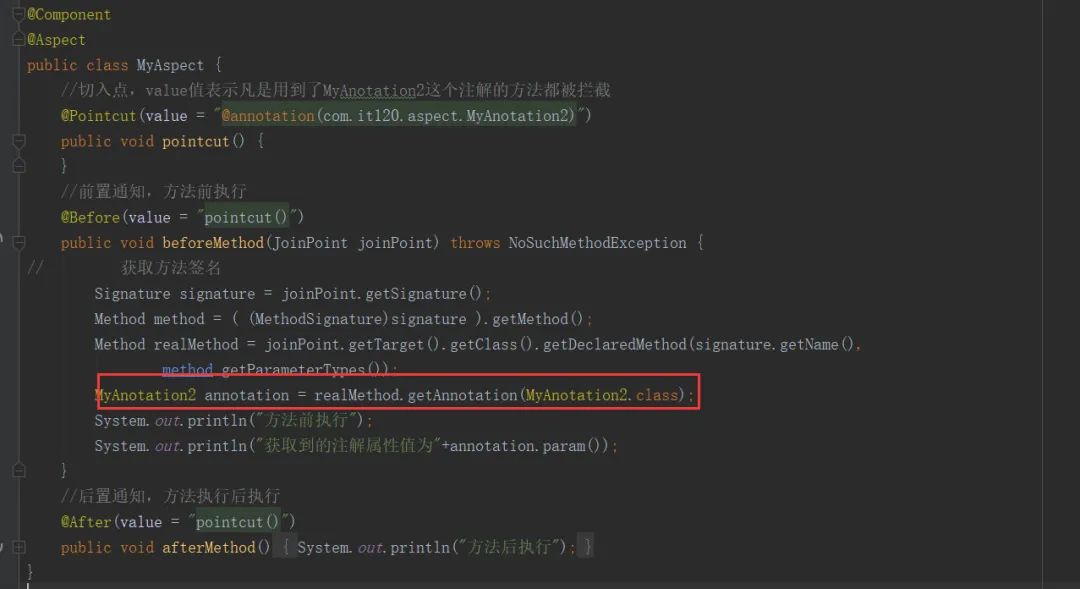
- 新建切面类,如下:
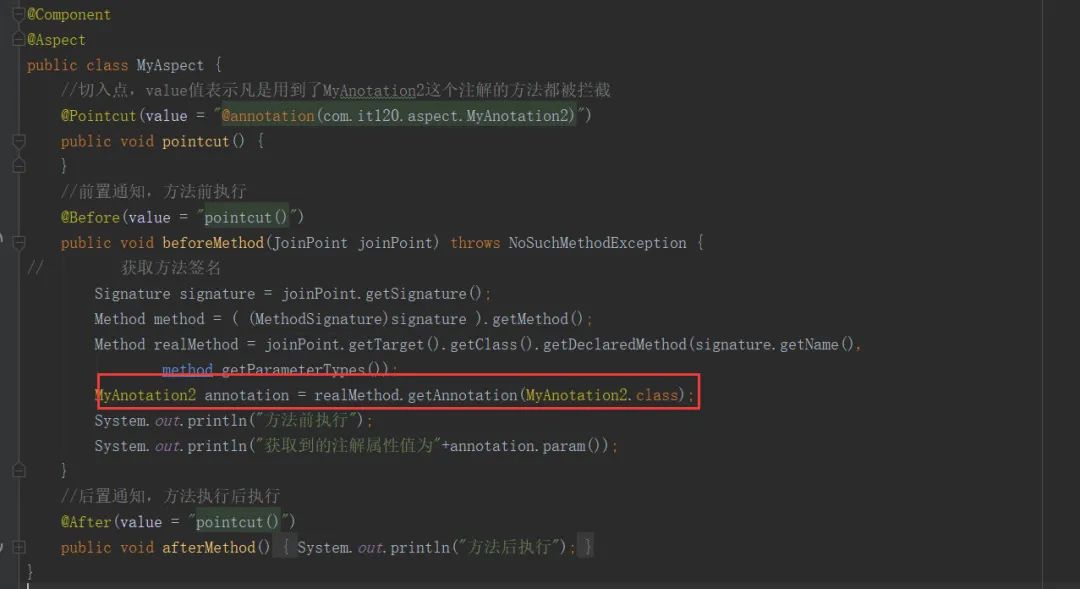
在切面类我们定义了三个方法切入点、前置通知、后置通知、并在前置通知方法中,通过方法签名获取注解属性。
- 在此我们就不启动整个SpringBoot项目了,我们通过注解创建出容器,并把相关的方法通过@Component注解注册近容器中,创建一个容器配置类,声明容器扫描路径如下
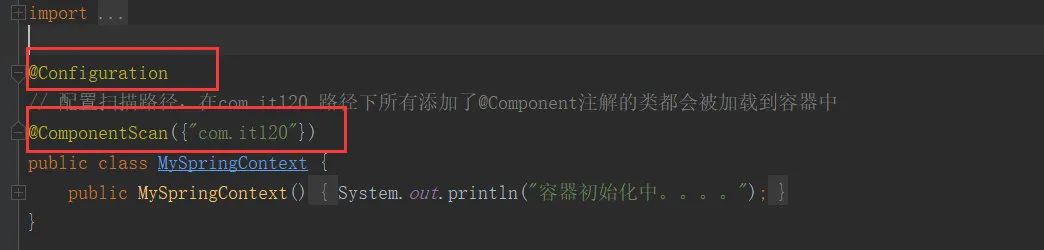
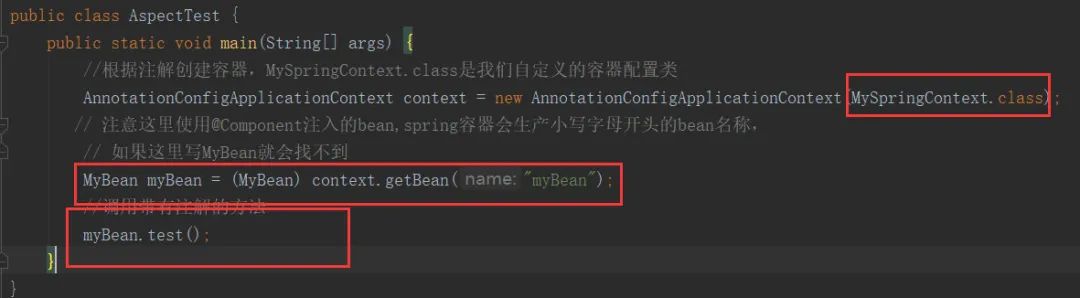
- 创建main方法,并且配置如下:
目前的项目目录如下:
运行main方法,控制台打印如下:
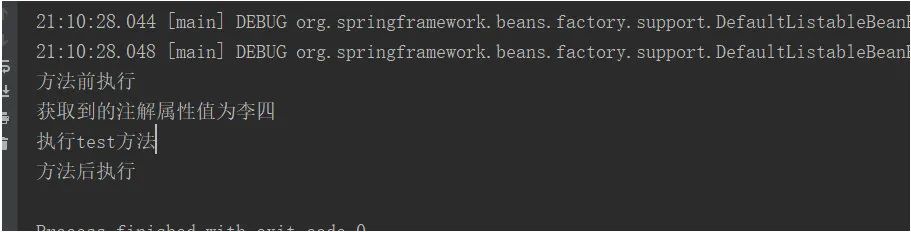
在以上例子中我们不仅学习到了切面和注解的结合使用,还体验了一把个悲剧注解自己创建Spring容器把相关bean注入容器中并获取bean,执行bean的知识知识!!
到这我们学会了如何在切面中获取自定义注解的知识,但是本篇文章并不会到此就早早收场,我们再通过一个案例来深入理解自定义注解和AOP的使用
终极目标,通过自定义注解和aop实现数据库动态数据源的切换
- 添加如下依赖:
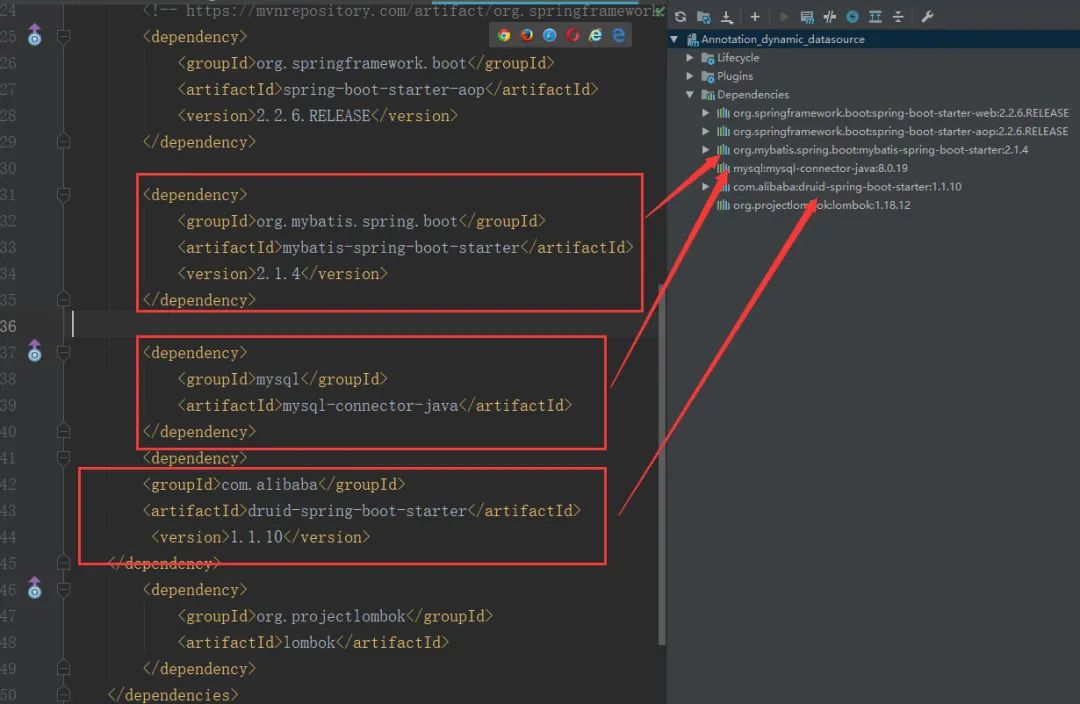
- 在application.yml文件中配置多数据源,如图
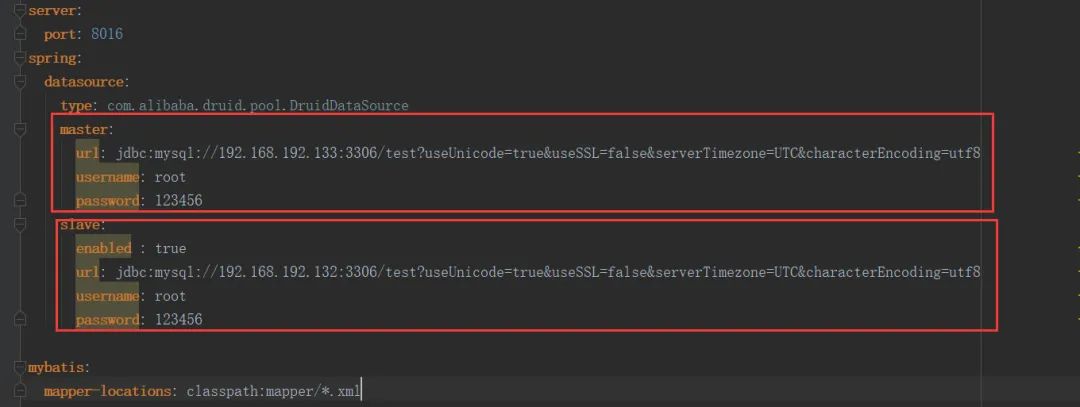
在上图中我们配置了master和slave两个数据源,分别指定不同的机器上的数据库
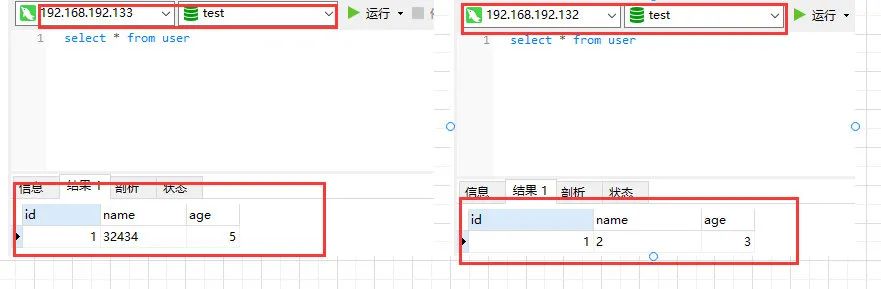
- 数据表准备,这里的表就很简单了在133和132数据库上有相同的数据库test和相同的数据表user,但是表中的数据并不相同,这里也是为了区分数据源切换是否成功,表如下:
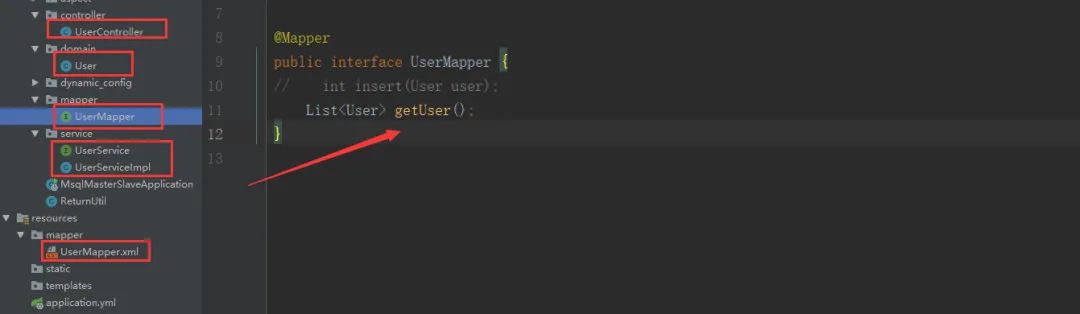
- 新建User实体类,创建UserService、UserServiceImpl、controller、mapper、UserMapper.xml这些常规操作对于大家都很简单了,这里不一一讲解了直接贴个项目目录结构图,如下:
- 自定义注解用于方法上根据注解属性值切换数据源类型
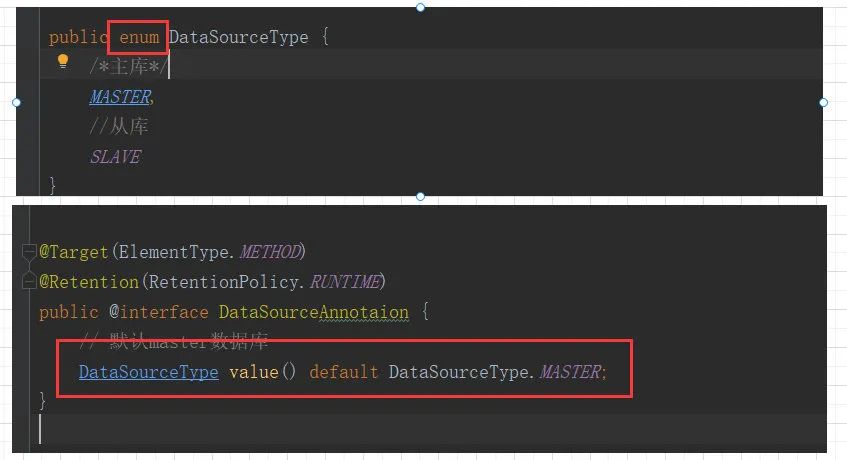
在上图中我们定义了一个DataSourceType的枚举类,定义了一个DataSourceAnnotaion注解,注解的属性值就是定义的枚举类,而且默认值为MASTER
- 每一个线程访问数据库操作方法时指定的数据源都必须是私有的,这里我们用ThrealLocal来存储每个线程访问数据库时指定的数据源类型
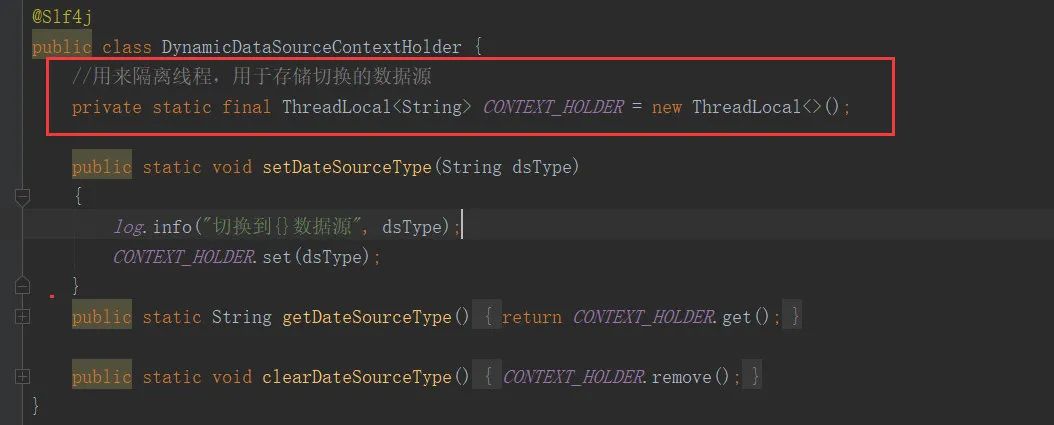
上图中我们能定义了一个ThreadLocal变量,提供了从ThreadLocal存、取、删这三个方法。
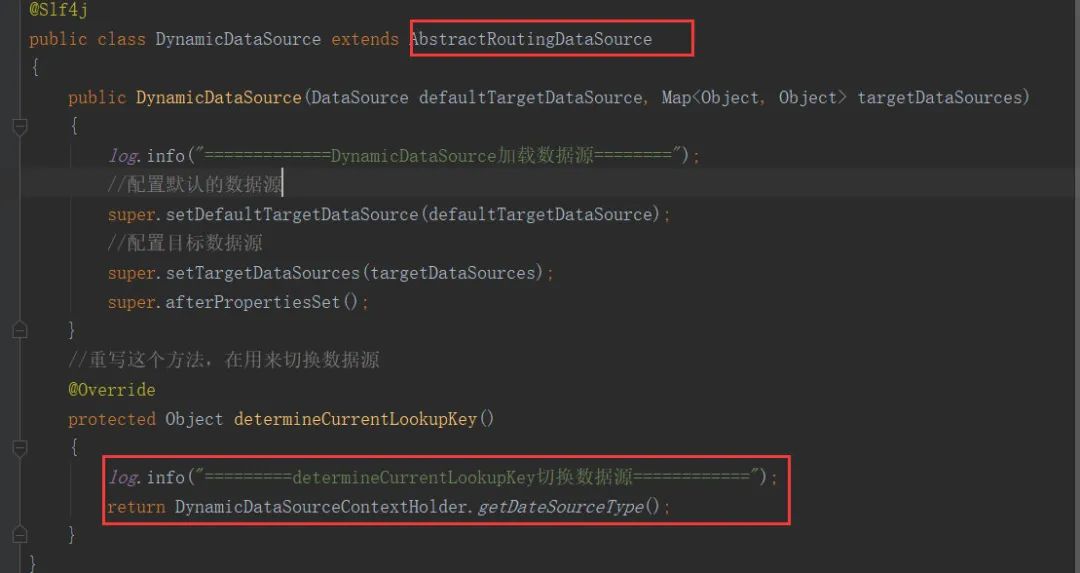
- 定义数据源切换的路由类,新建类继承AbstractRoutingDataSource,重写determineCurrentLookupKey()方法,如图
- 新建数据源配置类,分别根据注解创建数据源对象如图:
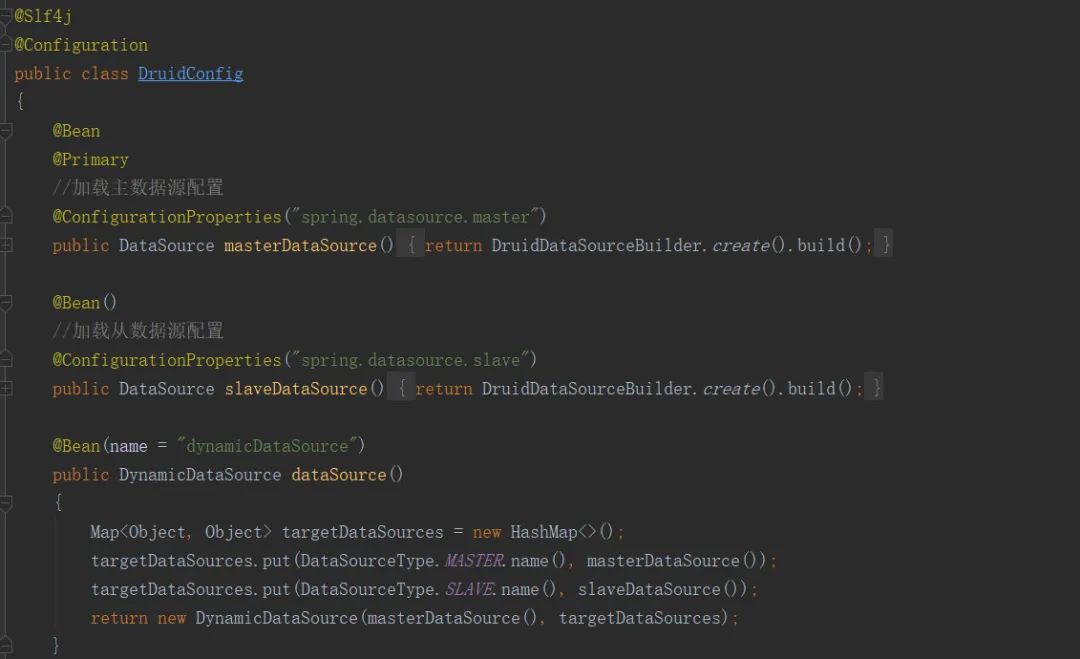
方法中,我们把主从数据源对应的枚举类型作为key,对应的数据源对象作为value存入map中返回创建了DynamicDataSource对象默认数据库为master,在SqlSessionFactoryBean 方法中我们需要重新指定mapper.xml文件的路径,不然这里运行时报找不到指定mapper,我们还添加了platformTransactionManager事务管理器。
- 新建切面类用于拦截有注解标识的方法,根据注解属性值切换数据库如图:
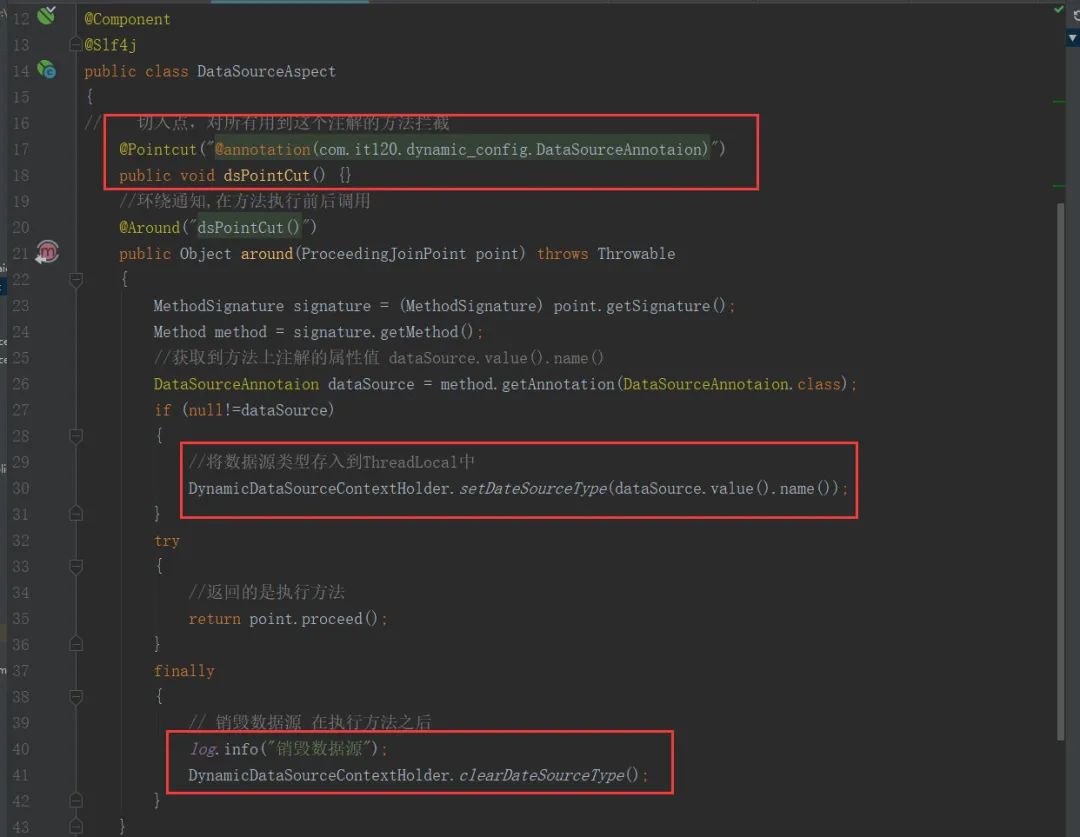
如上图所示我们在环绕通知中,根据方法上注解的属性值将相对应的数据源枚举类存入到ThreadLocal中,return.ponit.procees()这个方法就是执行我们操作数据库的方法,而在操作完数据库中我们在当前线程的ThreadLocal()中删除所以数据源标识。完成的多数据源切换的类代码结构如下:

我们来捋一下这个数据源操作的执行过程
- 在项目启动时DruidConfig类将会首先将读取配置文件中的数据源配置创建出master和slave两个数据源对象。
- DruidConfig类中dataSource()将数据源枚举值和数据源对象存入map中,并执行DynamicDataSource的构造方法,并把数据源集合和目标数据源传给AbstractRoutingDataSource中的对象
- 当我们调用有注解标识的方法时,切面类DataSourceAspect 获取方法上的注解属性类型,存入到当前线程的ThrealLocal对象中,此时将会调用AbstractRoutingDataSource类的determineCurrentLookupKey()方法,这个方法将对应的数据源对象返回,之后切面类环绕通知方法调用 point.proceed(); 在上文中我们说过调用这个方法其实就是aop执行我们操作数据库的方法,在执行完数据库方法后在当前线程ThreadLocal中把标识清除。
- 在controller中创建访问数据库的接口如图:
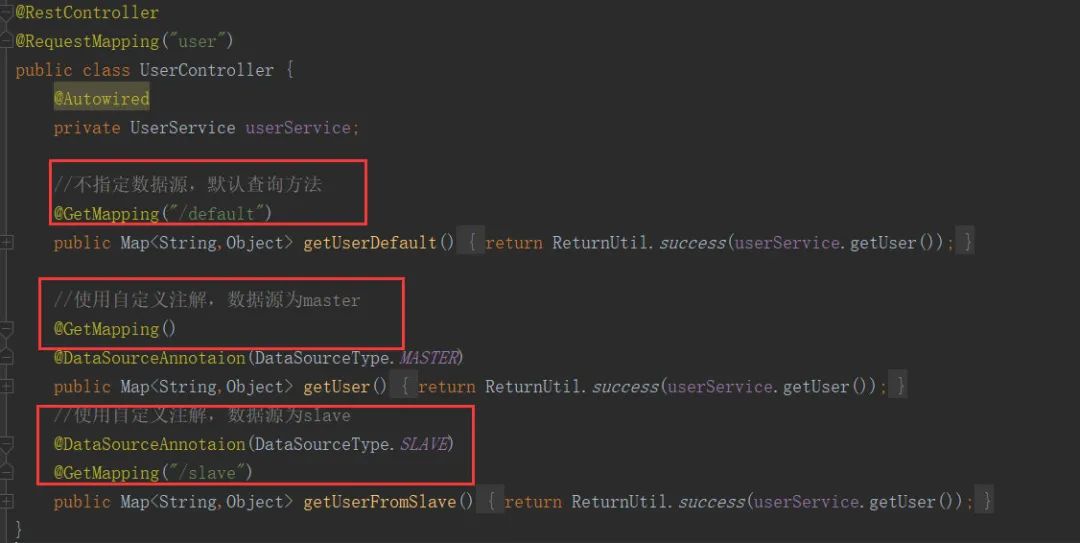
在上图中我们写了三个方法,默认方法不加注解,添加了master属性的方法,和添加了slaves属性的方法,现在我们分别测试这三个方法访问数据表的情况:
调用默认接口,这个接口方法中我们并没有只从任何的数据源,所以默认为master数据源
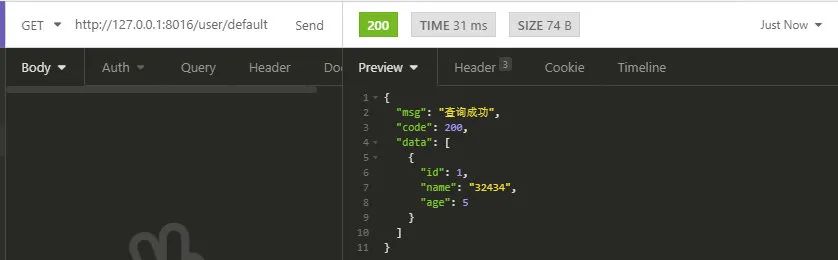
在determineCurrentLookupKey()方法中监听到的日志如下

调用指定master数据源的接口
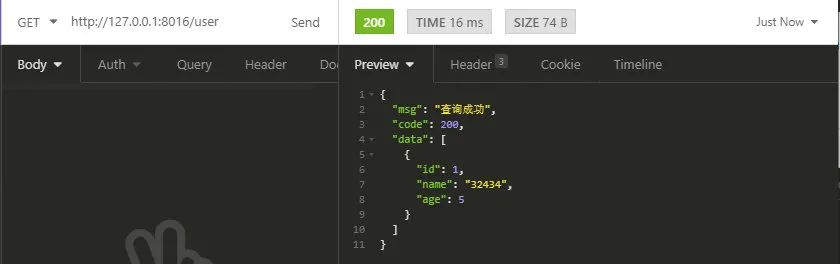
在determineCurrentLookupKey()方法中监听到的日志如下

调用指定slave数据源的接口
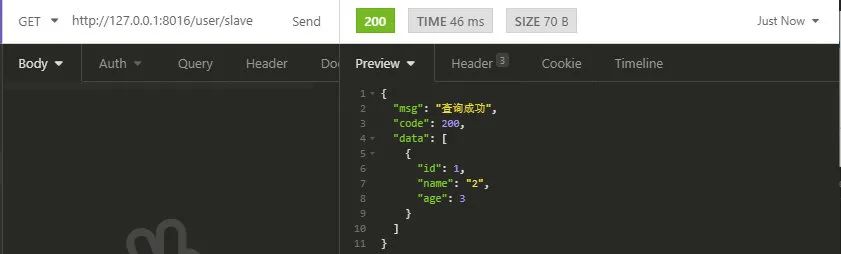
在determineCurrentLookupKey()方法中监听到的日志如下

从以上图中可以看到我们所配置的多数据源切换是成功的,到此测试结束。
总结:在本篇文章中我们可以很直接的认识到aop和注解的强大功能,学好这些知识对于我们自身的技能也是有所提高的,而在mybatis-plus动态数据源切换中也是用到了aop的和注解的知识,通过以上知识我们也能对它的实现原理有了一个大概的认识,本篇文章只是作为一个引子还有很多可扩展的地方,比如我们定义有master注解的方法执行数据库写操作,而有slave注解的数据库操作为读数据库的操作,这样我们也是能粗略的模仿出数据库读写分离的框架了,当然读写分离不仅仅是代码多数据源上的切换,还要配合mysql端的主从复制,基础知识很重要,也许你不能创造出一个新的框架,但是这些知识将会在你接触新框架时让你很快上手。
































还没有评论,来说两句吧...