Elasticsearch基本操作:索引、文档、搜索
1、索引
在 Elasticsearch 中开始为数据建立索引之前要做的第一步操作是创建——我们的数据主要容器。这里的索引类似于 SQL 中的数据库概念。它是类型(相当于 SQL 中的表)和文档(相当于 SQL 中的记录)的容器。
存储数据的行为叫作索引。在 Elasticsearch 中,文档会归属于一种类型,这些类型会存在于索引中。
Elasticsearch 集群和数据库中核心概念的对应关系如下:
| Elasticsearch 集群 | 关系型数据库 |
|---|---|
| 索引 | 数据库 |
| 类型 | 表 |
| 文档 | 行数据 |
| 字段 | 列数据 |
1.1 创建索引
定义一个博客信息(blog_info)的数据表结构:
| 字段 | 类型 | 说明 |
|---|---|---|
| blog_id | long | 博客ID |
| blog_name | text | 博客名称 |
| blog_url | keyword | 博客地址 |
| blog_points | double | 博客积分 |
| blog_describe | text | 博客描述 |
字段类型必须映射到 Elasticsearch 的基本类型之一,并且需要添加有关如何索引字段的选项。
推荐本博客文章1:《Elasticsearch映射类型》
推荐本博客文章2:《Elasticsearch基本操作》
Elasticsearch教程:《Elasticsearch教程》
使用 Elasticsearch 命令创建索引:
PUT /blog_info{"settings": {"index": {"number_of_shards": "2","number_of_replicas": "1"}},"mappings": {"properties": {"blog_id": {"type": "long"},"blog_name": {"type": "text"},"blog_url": {"type": "keyword"},"blog_points": {"type": "double"},"blog_describe": {"type": "text","analyzer": "ik_max_word"}}}}
参数说明:
number_of_shards:该参数控制组成索引的分片(Shard)的数量。
number_of_replicas:该参数可控制复制副本(Replica)的数量,也就是说,为了实现高可用性,在集群中复制数据的次数。比较好的做法是设置该值至少为1。
执行结果:
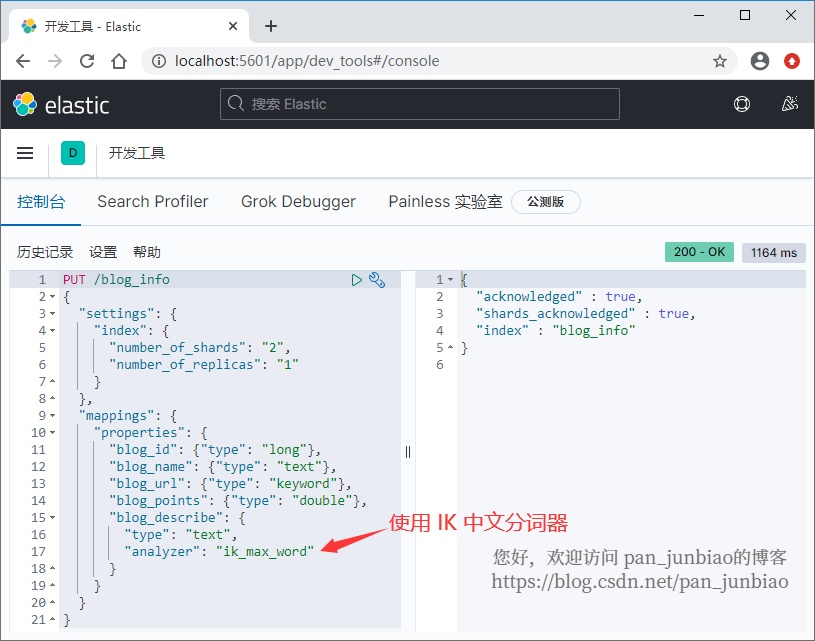
注意:创建索引时,索引名称必须小写。
1.2 删除索引
与创建索引相对的就是删除索引。删除索引意味着删除其分片、映射和数据。
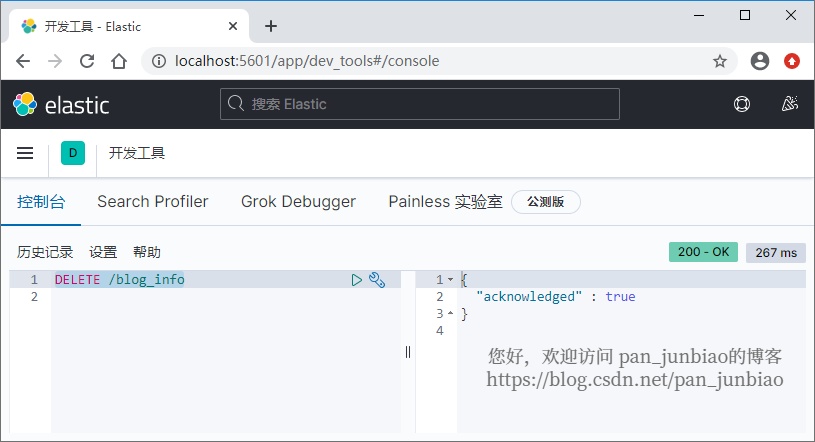
使用 Elasticsearch 命令删除索引:
DELETE /blog_info
执行结果:
1.3 检查索引是否存在
一个常见的陷阱错误是查询不存在的索引。为避免此问题,Elasticsearch 给用户提供了检查索引是否存在的功能。
该检查通常用于应用程序启动期间,以创建正常工作所需的索引。
使用 Elasticsearch 命令检查索引是否存在:
HEAD /blog_info/
执行结果:
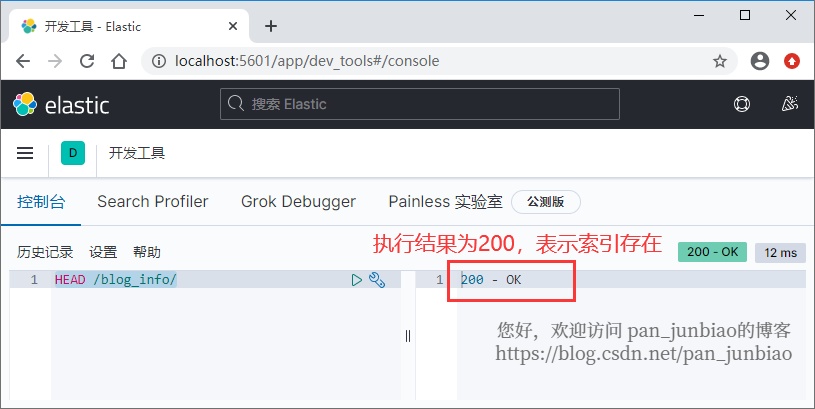
如果索引存在,则返回HTTP状态码200;如果不存在,则返回404代码。
这是一个典型的 HEAD REST 调用,用于检查某些东西是否存在。它不返回正文响应,仅返回状态码,即操作的结果状态。
最常见的状态码如下:
20X系列:表示一切正常。
404:表示资源不可用。
50X系列:表示存在服务器错误。
1.4 打开或关闭索引
如果想要保留数据并且节省资源(内存或CPU),则删除索引的一种不错的替代方法是关闭索引。
Elasticsearch 允许打开和关闭索引,使其进入在线或离线模式。
使用 Elasticsearch 命令打开索引:
POST /blog_info/_open
使用 Elasticsearch 命令关闭索引:
POST /blog_info/_close
1.5 重建索引
有很多常见的情况都涉及更新映射。由于 Elasticsearch 映射的限制,无法删除已定义的映射,因此通常需要为索引数据重建索引。
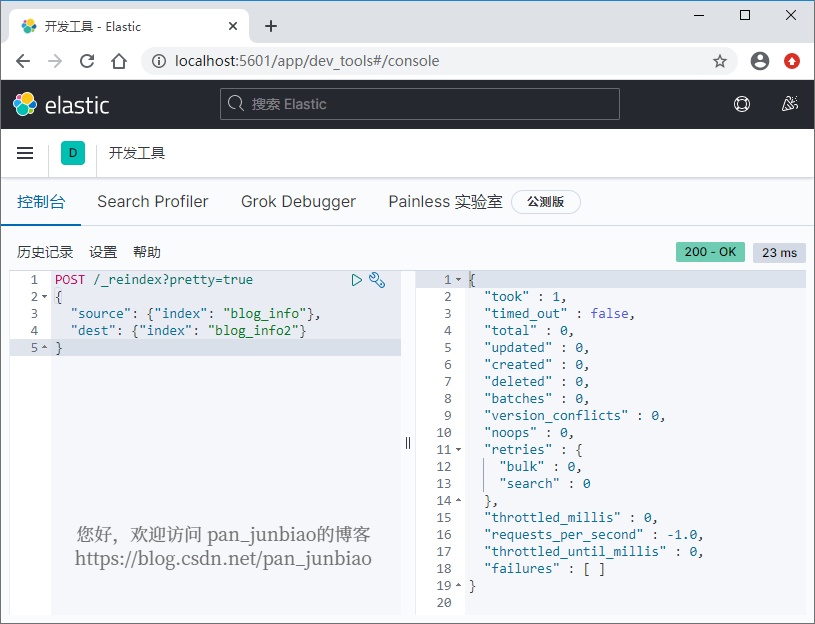
如果要将 blog_info 数据重建索引为 blog_info2 索引,使用 Elasticsearch 命令重建索引:
POST /_reindex?pretty=true{"source": {"index": "blog_info"},"dest": {"index": "blog_info2"}}
执行结果:
除了上述索引的操作方法外,还有:刷新索引、冲洗索引、强制合并索引、缩小索引、索引别名、滚动索引等操作。这里不作介绍。
2、文档
创建文档表示将一个或多个文档存储在索引中,这与在关系型数据库中插入记录的概念是类似的。
在 Elasticsearch 的核心引擎 Lucene 中,插入或更新文档的成本是相同的:在 Lucene 和 Elasticsearch 中,更新意味着替换。
2.1 批量新增文档
在 Elasticsearch 中可以使用批量操作命令,向索引中批量新增文档。
使用 Elasticsearch 命令批量新增文档:
POST _bulk{"create":{"_index":"blog_info","_id":"1"}}{"blog_id":1,"blog_name":"pan_junbiao的博客","blog_url":"https://blog.csdn.net/pan_junbiao","blog_points":150.68,"blog_describe":"您好,欢迎访问 pan_junbiao的博客"}{"create":{"_index":"blog_info","_id":"2"}}{"blog_id":2,"blog_name":"pan_junbiao的博客","blog_url":"https://blog.csdn.net/pan_junbiao","blog_points":276.34,"blog_describe":"您好,欢迎访问 pan_junbiao的CSDN博客"}{"create":{"_index":"blog_info","_id":"3"}}{"blog_id":3,"blog_name":"pan_junbiao的博客","blog_url":"https://blog.csdn.net/pan_junbiao","blog_points":316.58,"blog_describe":"您好,欢迎访问 pan_junbiao的CSDN博客"}
执行结果:
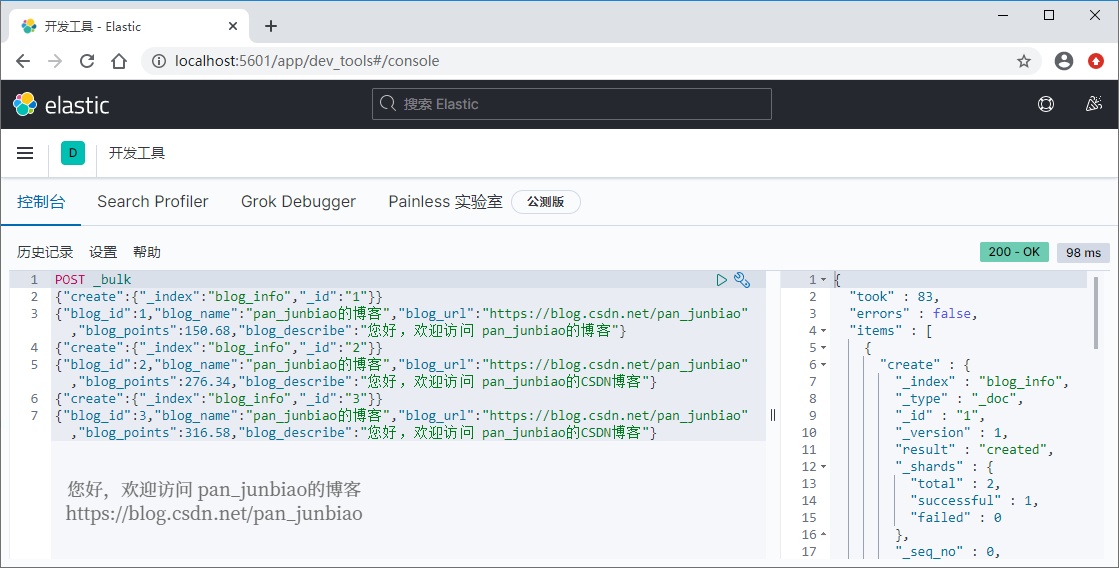
使用 ElasticSearch-head 插件查看执行结果:

2.2 更新文档
Elasticsearch 中存储的文档可以在生存期间进行更新。
将文档 id 为3的数据中的 blog_name 字段的值修改为:pan_junbiao的博客_003
使用 Elasticsearch 命令更新文档:
POST /blog_info/_update/3{"doc":{"blog_id":3,"blog_name":"pan_junbiao的博客_003","blog_url":"https://blog.csdn.net/pan_junbiao","blog_points":316.58,"blog_describe":"您好,欢迎访问 pan_junbiao的CSDN博客"}}
执行结果:
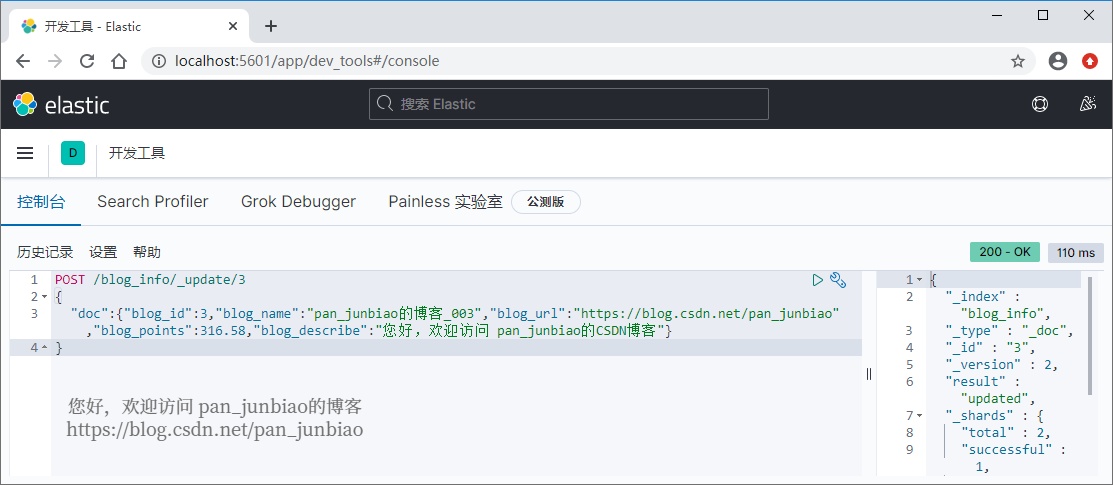
使用 ElasticSearch-head 插件查看执行结果:

2.3 删除文档
在 Elasticsearch 中删除文档的方式有两种:使用 DELETE 调用或 delete_by_query 调用。
将文档 id 为3的数据删除。
使用 Elasticsearch 命令删除文档:
DELETE /blog_info/_doc/3
执行结果:
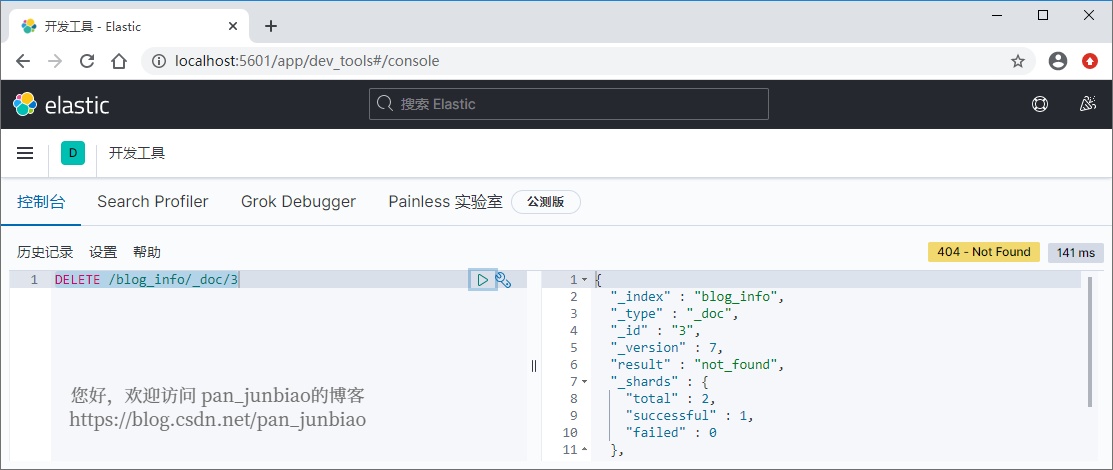
使用 ElasticSearch-head 插件查看执行结果:

从上图结果可以看出,id 为3的文档数据已被删除。
2.4 查询文档
标准 GET 操作非常快,但是如果需要通过文档 id 提取多个文档,则 Elasticsearch 提供了多个 GET 操作。
使用 Elasticsearch 命令查询文档:
GET /blog_info/_doc/1
查询多个文档:
GET /blog_info/_mget{"ids":["1","2"]}
执行结果:
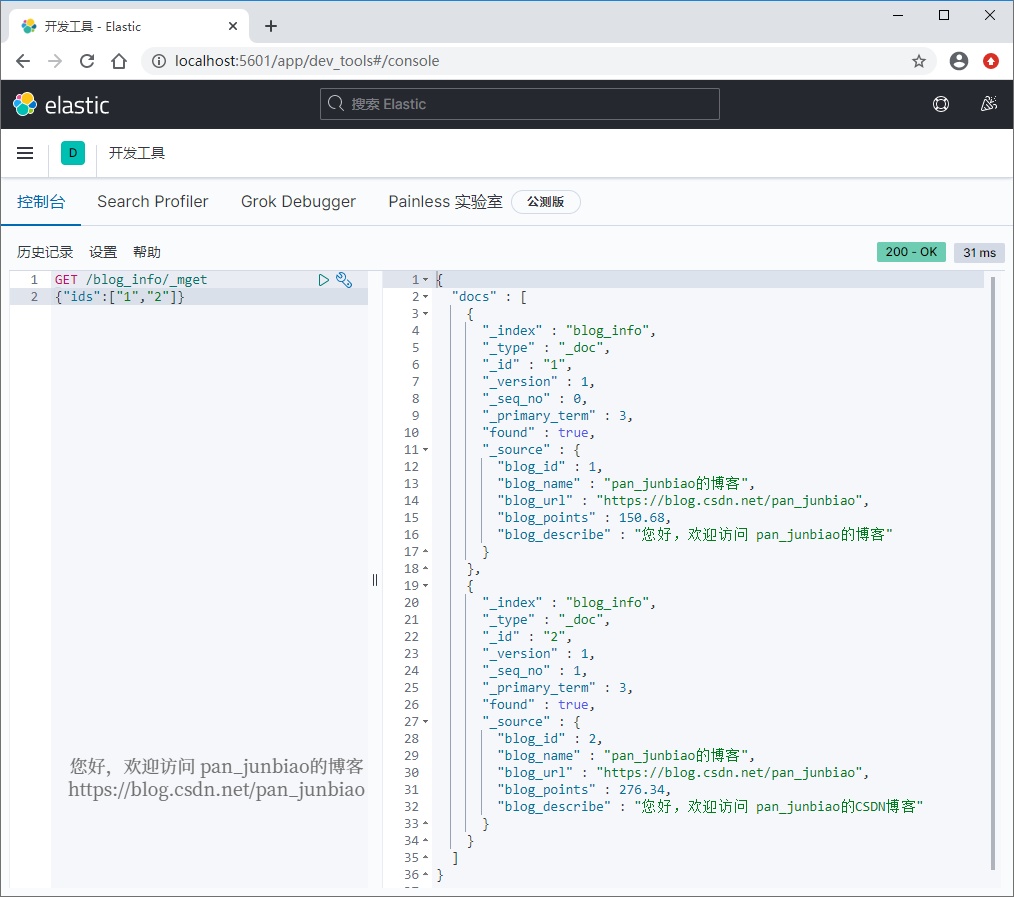
3、搜索
Elasticsearch 是面向文档的,它可存储整个文档。但 Elasticsearch 对文档的操作不仅限于存储,Elasticsearch 还会索引每个文档的内容使之可以被搜索。
在 Elasticsearch 中,用户可以对文档数据进行索引、搜索、排序和过滤等操作,而这也是 Elasticsearch 能够执行复杂的全文搜索的原因之一。
3.1 查看分词结果
在 Elasticsearch 中可以设置分词器,并 查看分词结果。
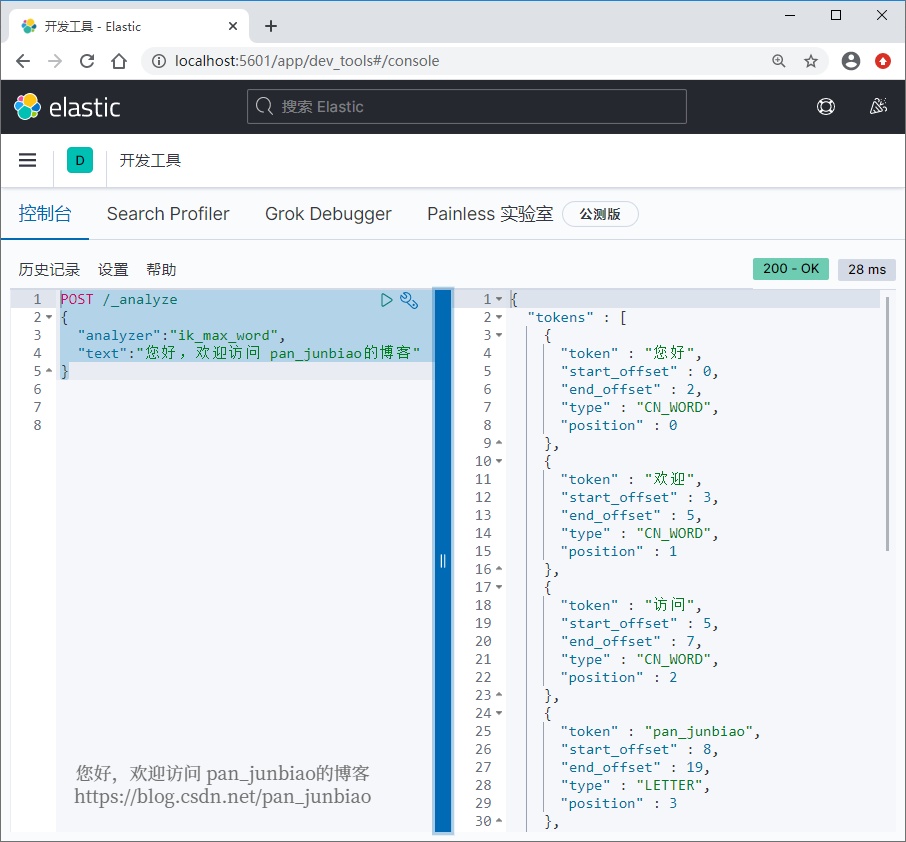
使用 Elasticsearch 命令查看分词结果:
POST /_analyze{"analyzer":"ik_max_word","text":"您好,欢迎访问 pan_junbiao的博客"}
执行结果:
3.2 搜索并排序
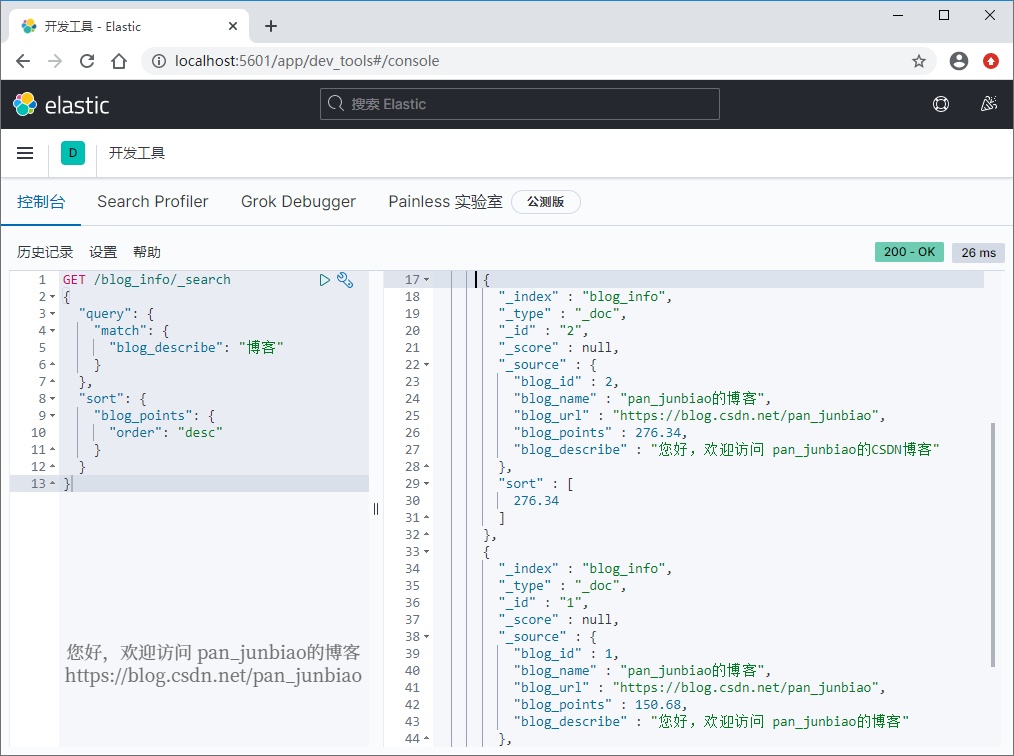
搜索 blog_describe (博客描述)字段中包含“博客”的数据,并按照博客积分进行倒序排序。
使用 Elasticsearch 命令搜索并排序:
GET /blog_info/_search{"query": {"match": {"blog_describe": "博客"}},"sort": {"blog_points": {"order": "desc"}}}
执行结果:
3.3 使用范围搜索
在实际的应用程序中,使用范围值进行搜索的情况非常普遍。
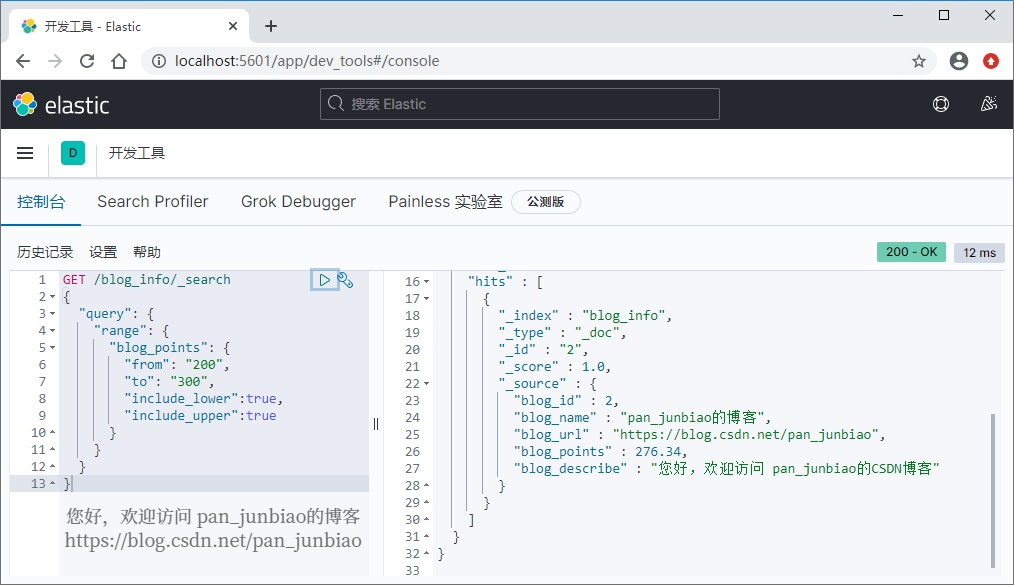
搜索博客积分在200至300的范围内的数据。
GET /blog_info/_search{"query": {"range": {"blog_points": {"from": "200","to": "300","include_lower":true,"include_upper":true}}}}
或者:
GET /blog_info/_search{"query": {"range": {"blog_points": {"gte": "200","lte": "300"}}}}
参数说明:
from:范围的起始值(可选)。
to:范围的结束值(可选)。
include_lower:将范围的起始值包括在内(可选,默认为 true)。
include_upper:将范围的结束值包括在内(可选,默认为 true)。
gt:大于。
gte:大于或等于。
lt:小于。
lte:小于或等于。
执行结果:


































还没有评论,来说两句吧...