MySQL之分库分表
MySQL之分库分表
- 为什么要分库分表?
- 分库分表
- 如何把系统迁移到分库分表
- 分库分表后全局 id 如何生成
- 4.1 数据库自增 id
- 4.2 uuid
- 4.3 系统当前时间戳
- 4.4 SnowFlask
1. 为什么要分库分表?
倘若我们没有进行分库分表,那么整个架构图如下所示:
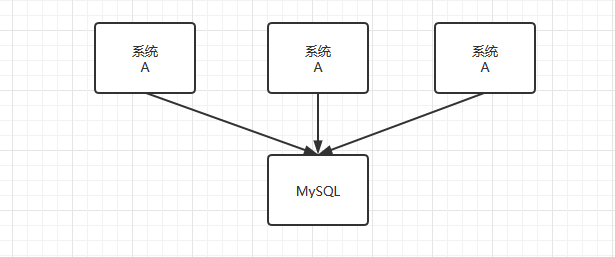
可以看到,多个系统的实例都在访问同一个`MySQL`实例,随着业务量的增加,我们可以在增加系统的实例,但是始终访问的都是同一个实例。并且,如果每一个系统实例的读写请求都特别高,一个`MySQL`实例也是顶不住过多的请求,便造成数据库的宕机,整个系统无法服务。而如果进行分库分表之后,架构图如下所示:
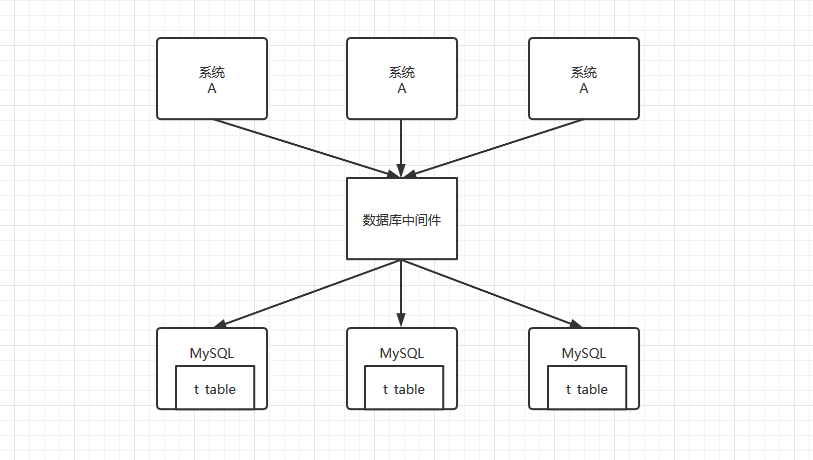
可以看到,原本的读写请求由一台`MySQL`实例,现在由三台`MySQL`实例承担。不仅提高了读写请求的承担能力,同时,数据也可以被接近于平均分配到每台`MySQL`实例中,这样数据查询速度也提高了。
2. 分库分表
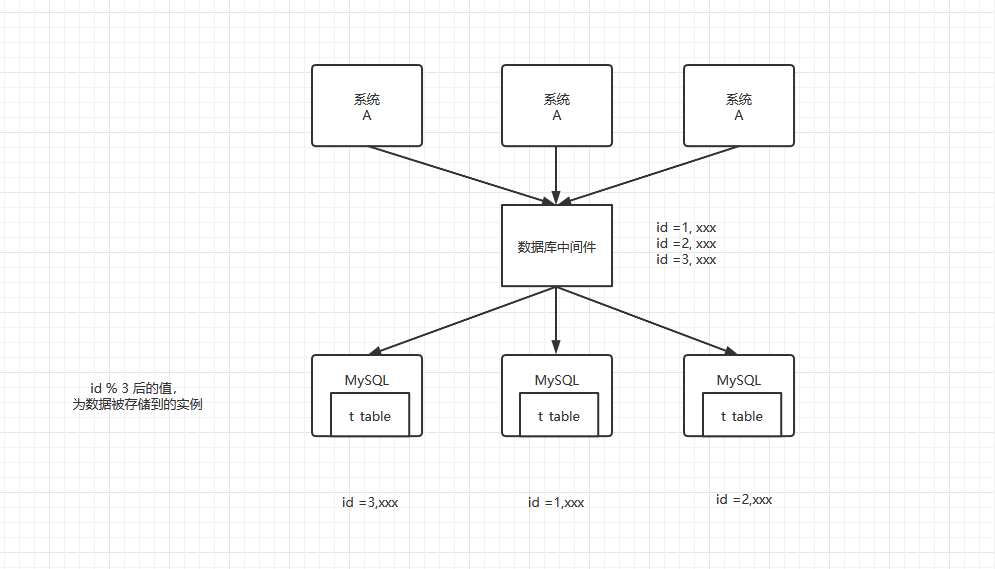
首先需要知道的是,分库、分表是两个不同的概念。分库指的是将一个库的数据拆分到多个库中,访问的时候就访问一个库好了。多台`MySQL`的实例中,每个实例中都有一摸一样的表,除了表中的数据。分表指的是把一个表的数据放到多个表中,然后查询的时候你就查一个表。同时,分表又分为水平切分和垂直切分。水平拆分的意思,就是把一个表的数据给弄到多个库的多个表里去,但是每个库的表结构都一样,只不过每个库表放的数据是不同的,所有库表的数据加起来就是全部数据。水平拆分的意义,就是将数据均匀放更多的库里,然后用多个库来抗更高的并发,还有就是用多个库的存储容量来进行扩容。
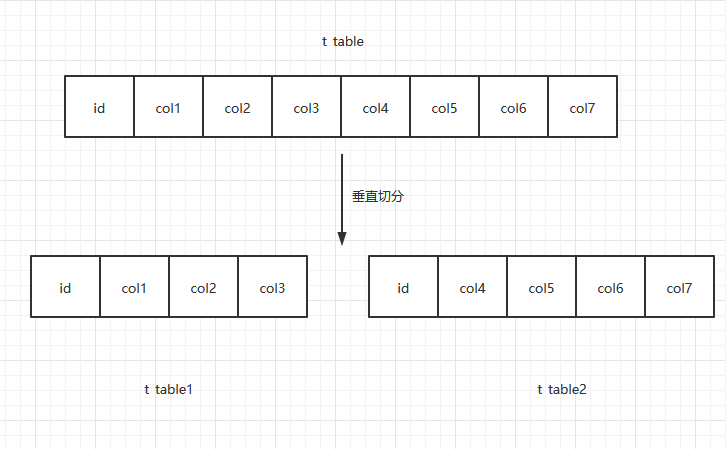
垂直拆分的意思,就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。每个库表的结构都不一样,每个库表都包含部分字段。一般来说,会将较少的访问频率很高的字段放到一个表里去,然后将较多的访问频率很低的字段放到另外一个表里去。因为数据库是有缓存的,你访问频率高的行字段越少,就可以在缓存里缓存更多的行,性能就越好。这个一般在表层面做的较多一些。
3. 如何把系统迁移到分库分表
倘若我们的系统之前采用单台`MySQL`实例的方案,现在要将其进行分库分表,那么表中的数据应该如何进行迁移,同时不能对用户造成干扰。
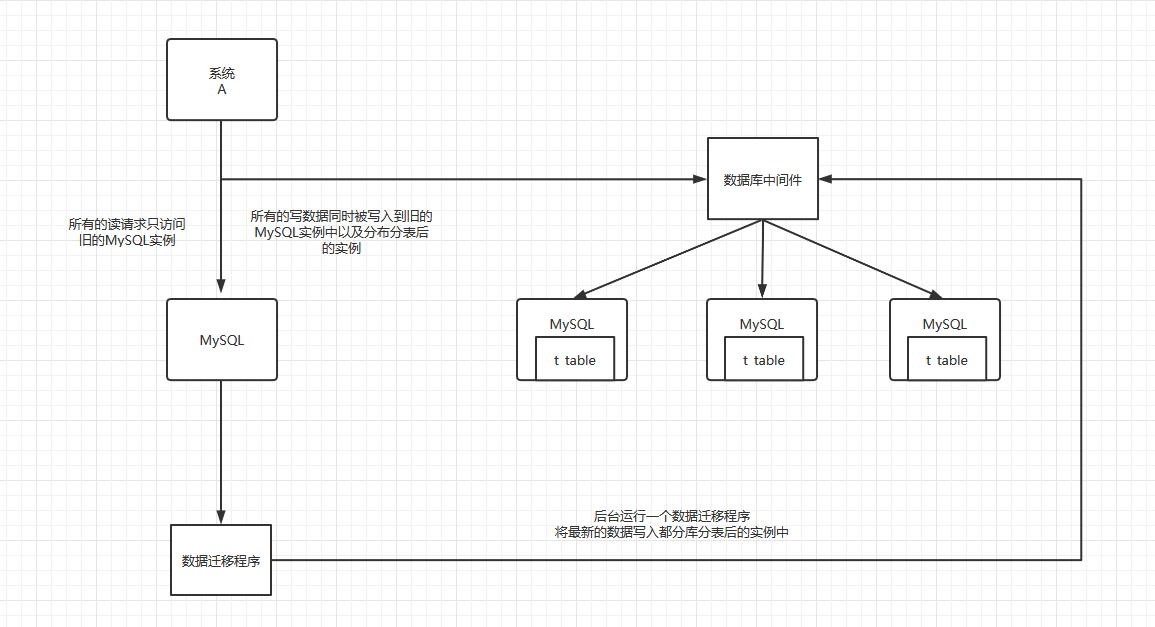
迁移过程如上图所示,后台将数据迁移完成后,替换掉之前读写旧数据库的代码即可。
4. 分库分表后全局 id 如何生成
在单实例的情况下,我们通常都是采用自增主键的方式进行 id 的生成,这样做到好处是,数据 id 向增大的方向生成,可以避免随机生成带来数据页的频繁裂化,降低`MySQL`的效率。如果我们根据`id`对数据进行分库分表,如果每张表依然开启主键自增,显然是不够合适的。每张表中可能会出现`id`相同的数据,这样情况显然是不被允许的。之前在实习的过程中,是这样做到,调用一个`RPC`的方法,专门用于生成全局唯`id`。现在让我们研究一下全局`id`应如何生成。
4.1 数据库自增 id
这里的数据库自增 `id` ,并不是指开启分库分表的自增。而是单独搞一张表,用于生成`id`。每次有新的数据插入,都访问这张表,获取自增后的`id`,作为分库分表后的数据`id`,如此便一定能保证全局唯一`id`。create table t_generateId(id bigint primary key auto_increment);
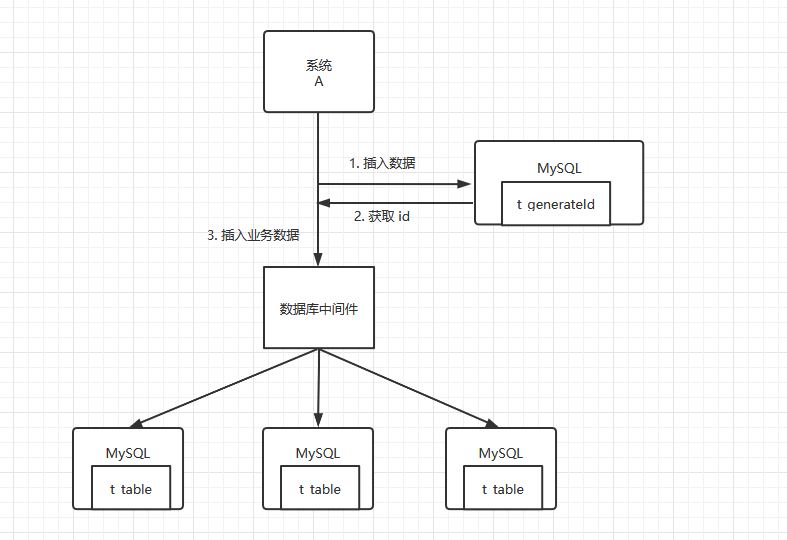
该方案适用于并发量很低的情况,我们做分库分表,就表明并发量较高了。如果生成`id`的这台`MySQL`实例不能顶得住过多的写请求,很容易造成整个系统的宕机。
4.2 uuid
前面说了,选择主键时,通常会让其向一个方向进行增长,这样可以避免数据页的频繁裂化及合并。而`uuid`增完全是随机的,很容易造成上述情况,所以并不推荐使用。其主要用于设置文件名,如我们QQ截图时,可以用`uuid`作为截图后的文件名。
4.3 系统当前时间戳
时间戳比`uuid`的好处时,其数据是朝一个方向进行增长的。到那时如果并发量很高的时候,同一时刻有多个请求,显然是不合适的。适合的场景:一般如果用这个方案,是将当前时间跟很多其他的业务字段拼接起来,作为一个id,如果业务上你觉得可以接受,那么也是可以的。你可以将别的业务字段值跟当前时间拼接起来,组成一个全局唯一的编号,订单编号,时间戳 + 用户id + 业务含义编码。
4.4 SnowFlask
[SnowFlask][]


































还没有评论,来说两句吧...