互联网求职季--大厂面试题合集(2)
美团面试题汇总
一、事务的ACID,其中把事务的隔离性详细解释一遍。
1.事务原则 : ACID
原子性(Atomicity):一起成功,或一起失败
一致性(Consistency):数据库总是从一个一致性的状态转换到另一个一致性的状态。
隔离性(Isolation):隔离性体现在事务并发时,相互影响的程度,
与隔离级别有之间关系。
持久性(Durability):事务没有提交,恢复到原来状态;事务已经提交,持久化到数据库(提交则不可逆)
2.隔离所导致的问题
脏读:一个事务读取了另一个事务未提交的数据(侧重于修改)
不可重复读:在一个事务内,多次读取,会读取到不同的数据(事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果不一致)
幻读(虚读):指在一个事务内读取到了别的事务插入的数据,导致前后读取不一致(侧重于新增或删除)
3.隔离级别
读未提交(read uncommitted)、读已提交(read committed)、可重复读(repeatable read)、串行化(serializable)
4.Mysql默认:可重复读
5.项目中要用 读已提交
6.事务隔离级别:脏读、不可重复读、幻读
二、jdk1.8中,对hashMap和concurrentHashMap做了哪些优化?
1.jdk1.8之前,ConcurrentHashMap通过将整个Map划分成N(默认16个)个Segment,而Segment继承自ReentrantLock ,通过对每个Segment加锁来实现线程安全。
2.jdk1.8后,摒弃了这种实现方式,采用了CAS + Synchronized,对链表头结点进行加锁,来实现线程安全。
三、MySQL行锁是否会有死锁的情况?
行级锁:开销大,加锁慢,会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
四、Redis高并发快的原因?
1.redis是基于内存的,内存的读写速度非常快;
2.redis是单线程的,省去了很多上下文切换线程的时间;
3.redis使用多路复用技术,可以处理并发的连接。非阻塞IO 内部实现采用epoll,采用了epoll+自己实现的简单的事件框架。epoll中的读、写、关闭、连接都转化成了事件,然后利用epoll的多路复用特性,绝不在io上浪费一点时间。
五、如何利用Redis处理热点数据?
1.所谓热key问题,就是突然有几十万的请求去访问redis上的某个特定key。那么,这样会造成流量过于集中,达到物理网卡上限,从而导致这台redis的服务器宕机。
2.那接下来这个key的请求,就会直接怼到你的数据库上,导致你的服务不可用。
3.**怎么发现热key**:
方法一:凭借业务经验,进行预估哪些是热key
其实这个方法还是挺有可行性的。比如某商品在做秒杀,那这个商品的key就可以判断出是热key。缺点很明显,并非所有业务都能预估出哪些key是热key。
方法二:在客户端进行收集
这个方式就是在操作redis之前,加入一行代码进行数据统计。那么这个数据统计的方式有很多种,也可以是给外部的通讯系统发送一个通知信息。缺点就是对客户端代码造成入侵。
方法三:在Proxy**层做收集**
有些集群架构是下面这样的,Proxy可以是Twemproxy,是统一的入口。可以在Proxy层做收集上报,但是缺点很明显,并非所有的redis集群架构都有proxy。
方法四:用redis**自带命令**
(1)monitor命令,该命令可以实时抓取出redis服务器接收到的命令,然后写代码统计出热key是啥。当然,也有现成的分析工具可以给你使用,比如redis-faina。但是该命令在高并发的条件下,有内存增暴增的隐患,还会降低redis的性能。
(2)hotkeys参数,redis 4.0.3提供了redis-cli的热点key发现功能,执行redis-cli时加上–hotkeys选项即可。但是该参数在执行的时候,如果key比较多,执行起来比较慢。
方法五:自己抓包评估
Redis客户端使用TCP协议与服务端进行交互,通信协议采用的是RESP。自己写程序监听端口,按照RESP协议规则解析数据,进行分析。缺点就是开发成本高,维护困难,有丢包可能性
4.**如何解决:目前业内的方案有两种**
(1)利用二级缓存:
比如利用ehcache,或者一个HashMap都可以。在你发现热key以后,把热key加载到系统的JVM中。针对这种热key请求,会直接从jvm中取,而不会走到redis层。假设此时有十万个针对同一个key的请求过来,如果没有本地缓存,这十万个请求就直接怼到同一台redis上了。现在假设,你的应用层有50台机器,OK,你也有jvm缓存了。这十万个请求平均分散开来,每个机器有2000个请求,会从JVM中取到value值,然后返回数据。避免了十万个请求怼到同一台redis上的情形。
(2)备份热key:
这个方案也很简单。不要让key走到同一台redis上不就行了。我们把这个key,在多个redis上都存一份不就好了。接下来,有热key请求进来的时候,我们就在有备份的redis上随机选取一台,进行访问取值,返回数据。假设redis的集群数量为N,步骤如下图所示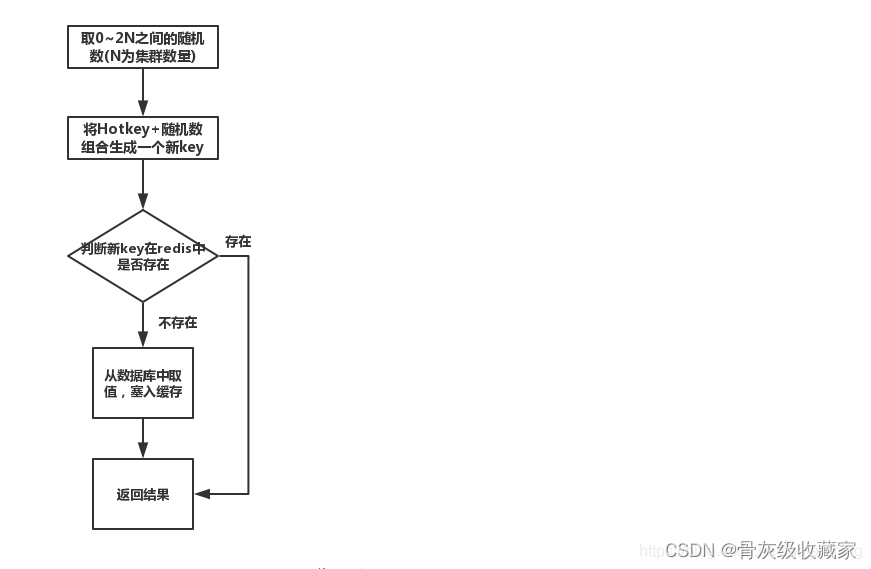

六、乐观锁和悲观锁了解吗?JDK中涉及到乐观锁和悲观锁的内容?
乐观锁:
乐观锁是一种乐观思想,即认为读多写少,遇到并发写的可能性低,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,采取在写时先读出当前版本号,然后加锁操作(比较跟上一次的版本号,如果一样则更新),如果失败则要重复读-比较-写的操作。
Java中的乐观锁基本都是通过CAS操作实现的,CAS 是一种更新的原子操作,比较当前值跟传入值是否一样,一样则更新,否则失败。
悲观锁:
悲观锁是就是悲观思想,即认为写多,遇到并发写的可能性高,每次去拿数据的时候都认为别人会修改,所以每次在读写数据的时候都会上锁,这样别人想读写这个数据就会block直到拿到锁。
Java中的悲观锁就是Synchronized,AQS框架下的锁则是先尝试cas乐观锁去获取锁,获取不到,才会转换为悲观锁,如 RetreenLock。
七、synchronized 和 ReentranLock的区别?
相似点:
这两种同步方式有很多相似之处,它们都是加锁方式同步,而且都是阻塞式的同步,也就是说当如果一个线程获得了对象锁,进入了同步块,其他访问该同步块的线程都必须阻塞在同步块外面等待,而进行线程阻塞和唤醒的代价是比较高的(操作系统需要在用户态与内核态之间来回切换,代价很高,不过可以通过对锁优化进行改善)。
功能区别:
这两种方式最大区别就是对于Synchronized来说,它是java语言的关键字,是原生语法层面的互斥,需要jvm实现。而ReentrantLock它是JDK 1.5之后提供的API层面的互斥锁,需要lock()和unlock()方法配合try/finally语句块来完成
便利性:
很明显Synchronized的使用比较方便简洁,并且由编译器去保证锁的加锁和释放,而ReenTrantLock需要手工声明来加锁和释放锁,为了避免忘记手工释放锁造成死锁,所以最好在finally中声明释放锁。
性能的区别:
在Synchronized优化以前,synchronized的性能是比ReenTrantLock差很多的,但是自从Synchronized引入了偏向锁,轻量级锁(自旋锁)后,两者的性能就差不多了,在两种方法都可用的情况下,官方甚至建议使用synchronized,其实synchronized的优化我感觉就借鉴了ReenTrantLock中的CAS技术。都是试图在用户态就把加锁问题解决,避免进入内核态的线程阻塞
八、Nginx负载均衡策略?
内置负载策略:
轮循(round-robin)**默认策略:**根据请求次数,将每个请求均匀分配到每台服务器,如果后端服务器宕机,自动剔除。
权重(Weight**):**把请求更多的分配到高配置的后端服务器上,默认每个服务器的权重都是1。
ip_hash**:**同一客户端的Web请求被分发到同一个后端服务器进行处理,使用该策略可以有效的避免用户Session失效的问题。该策略可以连续产生1045个互异的value,经过20次hash仍然找不到可用的机器时,算法会退化成轮循。
最少连接(last_conn)**:**Web请求会被转发到连接数最少的服务器上。
扩展策略:扩展策略默认不被编译进nginx内核,如果启用该策略,需要自行编译安装
Fair**:**根据后台服务器的响应时间判断负载情况,从中选出负载最轻的后端服务。但是在实际请款中,网络环境往往不那么简单,所以慎用。
在编译安装后,如果需要启用该策略,需要在upstream标签中添加fair;,启用该策略后,加权轮循将失效。
url_hash**:**按照请求url的hash结果来分配请求,试每个url定向到同一个后端服务器,在1.7.2之后的nginx版本中,该模块应集成到内核中,不需要单独安装。
启用该策略,需要在upstream标签中添加hash $request_url;
九、聚集索引和非聚集索引的区别?
区别:聚集索引一个表只能有一个,而非聚集索引一个表可以存在多个
聚集索引存储记录是物理上连续存在,而非聚集索引是逻辑上的连续,物理存储并不连续
聚集索引:物理存储按照索引排序;聚集索引是一种索引组织形式,索引的键值逻辑顺序决定了表数据行的物理存储顺序。
非聚集索引:物理存储不按照索引排序;非聚集索引则就是普通索引了,仅仅只是对数据列创建相应的索引,不影响整个表的物理存储顺序。
索引是通过btree的数据结构来描述的,我们可以这么理解聚簇索引:索引的叶节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。
优势与缺点:
聚集索引插入数据时速度要慢(时间花费在“物理存储的排序”上,也就是首先要找到位置然后插入),查询数据比非聚集数据的速度快。
更多面试真题前往官网:https://www.funit.cn/

























")








还没有评论,来说两句吧...