Fork/Join 并行计算框架
文章目录
- Fork/Join 介绍
- Fork/Join 组件
- Fork/Join原理-分治法
- Fork/Join原理-工作窃取算法
- Fork/Join案例
Fork/Join 介绍
Fork/Join框架自JDK 7引入,是一种并行计算框架,见名知义,其基于Fork和Join两个操作,它们的作用是将一个大任务拆分成多个小任务,并且将这些小任务合并起来得到大任务的结果。使用Fork/Join架构可以充分利用多核CPU的性能优势,提高程序的执行效率。
Fork/Join 组件
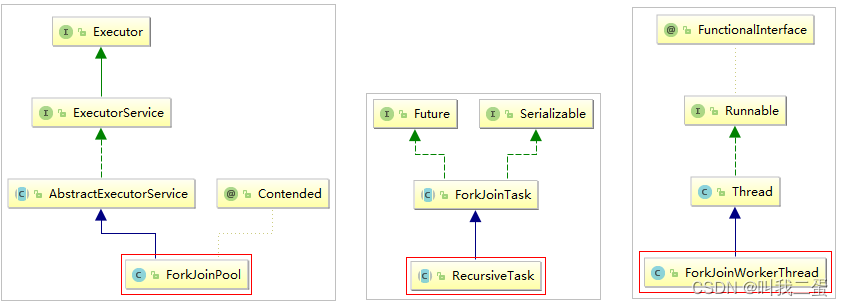
Fork/Join框架主要包含三个组件:
- 线程池:ForkJoinPool维护了一个线程池,用于并行执行任务,它可以根据需要动态调整线程的数量。
- 任务对象:ForkJoinTask是一个抽象类,它表示一个可以拆分的任务。ForkJoinTask的子类(RecursiveAction和RecursiveTask)必须实现fork()和compute()方法,其中fork()方法用于拆分任务并返回子任务的结果,compute()方法用于执行任务的实际计算。
- 执行任务的线程:ForkJoinWorkerThread是ForkJoinPool中的工作线程,它负责执行任务。
Fork/Join原理-分治法
ForkJoinPool主要用来使用分治法(Divide-and-Conquer Algorithm)来解决问题。典型的应用比如快速排序算法,ForkJoinPool需要使用相对少的线程来处理大量的任务。比如要对1000万个数据进行排序,那么会将这个任务分割成两个500万的排序任务和一个针对这两组500万数据的合并任务。以此类推,对于500万的数据也会做出同样的分割处理,到最后会设置一个阈值来规定当数据规模到多少时,停止这样的分割处理。比如,当元素的数量小于10时,会停止分割,转而使用插入排序对它们进行排序。那么到最后,所有的任务加起来会有大概2000000+个。问题的关键在于,对于一个任务而言,只有当它所有的子任务完成之后,它才能够被执行。

Fork/Join原理-工作窃取算法
Fork/Join最核心的地方就是利用了现代硬件设备多核,在一个操作时候会有空闲的cpu,那么如何利用好这个空闲的cpu就成了提高性能的关键,而这里我们要提到的工作窃取(work-stealing)算法就是整个Fork/Join框架的核心理念Fork/Join工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。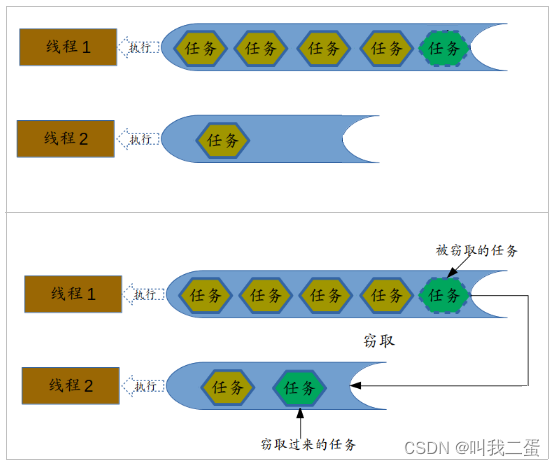
为什么需要使用工作窃取算法呢?假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争。上文中已经提到了在Java 8引入了自动并行化的概念。它能够让一部分Java代码自动地以并行的方式执行,也就是我们使用了ForkJoinPool的ParallelStream。
对于ForkJoinPool通用线程池的线程数量,通常使用默认值就可以了,即运行时计算机的处理器数量。可以通过设置系统属性:java.util.concurrent.ForkJoinPool.common.parallelism=N (N为线程数量),来调整ForkJoinPool的线程数量,可以尝试调整成不同的参数来观察每次的输出结果。
Fork/Join案例
使用Fork/Join计算1-10000的和,当一个任务的计算数量大于3000的时候拆分任务,数量小于3000的时候就计算。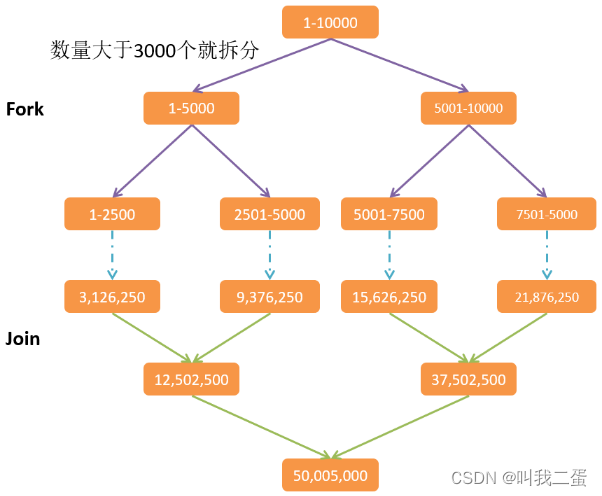
public class Test05 {* @param args*/public static void main(String[] args) {long start = System.currentTimeMillis();ForkJoinPool pool = new ForkJoinPool();SumRecursiveTask task = new SumRecursiveTask(1,10000l);Long result = pool.invoke(task);System.out.println("result="+result);long end = System.currentTimeMillis();System.out.println("总的耗时:" + (end-start));}}class SumRecursiveTask extends RecursiveTask<Long>{// 定义一个拆分的临界值private static final long THRESHOLD = 3000l;private final long start;private final long end;public SumRecursiveTask(long start, long end) {this.start = start;this.end = end;}@Overrideprotected Long compute() {long length = end -start;if(length <= THRESHOLD){// 任务不用拆分,可以计算long sum = 0;for(long i=start ; i <= end ;i++){sum += i;}System.out.println("计算:"+ start+"-->" + end +",的结果为:" + sum);return sum;}else{// 数量大于预定的数量,那说明任务还需要继续拆分long middle = (start+end)/2;System.out.println("拆分:左边 " + start+"-->" + middle+", 右边" + (middle+1) + "-->" + end);SumRecursiveTask left = new SumRecursiveTask(start, middle);left.fork();SumRecursiveTask right = new SumRecursiveTask(middle + 1, end);right.fork();return left.join()+right.join();}}}
































还没有评论,来说两句吧...