SpringBoot集成Kafka
引入Kafka依赖
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency>
修改配置文件
spring:kafka:bootstrap-servers: 127.0.0.1:9092,127.0.0.1:9093 #集群IP用,隔开producer:retries: 3batch-size: 16384 #生产者缓存每次发送batchSize大小的数据buffer-memory: 33554432 #设置缓冲区的最大大小acks: 1 #leader接受到以后就返回结果,不需要等待follower同步key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializerconsumer:group-id: default-groupenable-auto-commit: false #设置每条消息手动提交auto-offset-reset: earliest #一个消费组中默认从最早的消息开始消费,如果消费过了,则从offset开始消费key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializermax-poll-records: 500 #每次最多拉取500条listener:ack-mode: manual_immediateserver:port: 9700
测试编写消息生产者
@RestController@RequestMapping("/msg")public class MsgRestController {private final static String TOPIC_NAME = "my-replicated-topic";@Autowiredprivate KafkaTemplate<String,String> kafkaTemplate;@RequestMapping("/send")public String sendMessage(){// kafkaTemplate.send(TOPIC_NAME,"this is a message!");//不指定key与分区// kafkaTemplate.send(TOPIC_NAME,"key","this is a message!"); //指定key,kafka会对key进行hash算法,根据算法结果保存到指定分区// kafkaTemplate.send(TOPIC_NAME,0,"key","this is a message!");//明确指定要发送的分区kafkaTemplate.send(TOPIC_NAME,"this is a message!");return "send success!";}}
在生产者发送消息时,可以指定分区,也可以不指定分区,如果不指定,则kafka会轮训发送。如果指定了消息的key,则会根据指定的key进行hash算法得出保存的分区。
获取分区数据
@KafkaListener(topics = "my-replicated-topic", groupId = "myGroup")public void listenGroup(ConsumerRecord<String, String> record,Acknowledgment ack) {System.out.println("我是消费者1");String value = record.value();System.out.println("value = " + value);System.out.println("record = " + record);// ack.acknowledge(); //如果不手动提交,则消息会被重复消费}
使用@KafkaListener注解绑定某个方法来实现数据的消费。这里消费时还是有蛮多细节的。
- topics : 指定消费的主题,SpringBoot封装了消费,一个KafkaListener注解就是一个消费者,两个方法就是两个注解。
groupId :指定此消费者所属的消费组,一个队列,或者一个分区同一个消费组中只能有一个消费者消费,当该消费者中的消费者宕机以后,触发kafka的reblance机制重选更新消费者。
@KafkaListener(groupId = “countTotal”,
topicPartitions = {@TopicPartition(topic = "countTotal1",partitions = {"0,1"}),@TopicPartition(topic = "countTotal2",partitions = {"0"},partitionOffsets = {@PartitionOffset(partition = "0",initialOffset = "100")})})
如果一个消费者同时消费多个主题,则可以使用topicPartitions,@TopicPartition 指定多个消费的队列。
消息的生产与消费
- 为了保证消息尽可能不丢失,kafka生产者在发送消息时要设置ack机制,如果ack值为1,则表示只要集群中的leader将此条消息保存到log文件中就行了,但是消费者端有HW机制,也就是说消费者端允许消费的消息只能是所有集群全部同步后的消息,这也是高可用的一种机制,保证leader宕机后的follower可以不丢失消息。
- 消费者端设置手动提交而不是自动提交,在application.yml中配置了ack-mode: manual_immediate,这种消费方式为等待消费者处理完消息以后调用签收方法通知给kafka,表示此条消息被消费了,kafka则会更新这个分区的offset。注意:每个主题、每个分区的offset都是独立的。
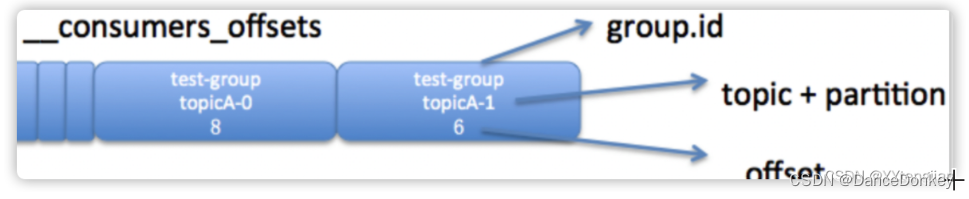
- 消费者的分区分配策略:如果一个主题有2个分区,那么对于多个消费者来说,如果在拉取消息的时候没有指定分区,则有kafka使用ribbon或者range算法来分配每个分区的消费者,如果消费者数小于分区数,则只能是一个消费者去消费多个分区的数据了。Topic的分区不一定保存在一个broker上,如果kafka集群是3个broker[broker0,broker1,broker2],那么在创建topic时,指定对应的分区数为2个,则有可能是分区1保存在broker0,分区2保存在broker1上。同时如果还指定了副本,则根据副本数,分别创建到对应的broker上,同时选举出leader和follower。



























")






还没有评论,来说两句吧...