Java爬虫第四篇:使用selenium、Jsoup 抓取图片
系列文章目录
通过Java+Selenium查询某个博主的Top100文章质量分
通过Java+Selenium查询某个博主的Top40文章质量分
通过Java+Selenium查询文章质量分
【在线商城系统】数据来源-爬虫篇
使用selenium、Jsoup 抓取图片
使用Jsoup 抓取文章
准备 chromedriver与chrome
文章目录
- 系列文章目录
- 在这里插入图片描述
- 前言
- 1、安装依赖
- 2、Selenium辅助类
- 3、核心测试代码
- 3.1、最终效果
" class="reference-link">
前言
通过自动化工具selenium模拟人工浏览器行为,并捕获到html代码,并用Jsoup 处理html代码,提取出其中的图片数据。
1、安装依赖
创建Java maven工程,在pom.xml里引入依赖
<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><!-- https://mvnrepository.com/artifact/org.jsoup/jsoup --><dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.11.3</version></dependency><dependency><groupId>org.seleniumhq.selenium</groupId><artifactId>selenium-java</artifactId><version>4.9.1</version></dependency>
2、Selenium辅助类
包含Chrome WebDriver驱动,图片存储路径,图片下载方法等;
import lombok.extern.slf4j.Slf4j;import java.io.File;import java.io.FileOutputStream;import java.io.InputStream;import java.io.OutputStream;import java.net.URL;import java.net.URLConnection;import java.util.Date;import java.util.regex.Matcher;import java.util.regex.Pattern;/**** @title SeleniumUtil* @desctption Selenium辅助类* @author Kelvin* @create 2023/5/19 14:28**/@Slf4jpublic class SeleniumUtil {public final static String CHROMEDRIVERPATH = "D://java/chrome/chromedriver.exe";public final static String LOCATION_IMG_BASE_PATH = "D://java//code//carData/img/";public static void sleep(int m) {try {Thread.sleep(m);} catch (InterruptedException e) {e.printStackTrace();}}/*** 文件下载到指定路径** @param urlString 链接* @throws Exception*/public static boolean download(String urlString, String parentFile , String key) {String savePath = SeleniumUtil.LOCATION_IMG_BASE_PATH + parentFile + "/" + key + "/";String filename = new Date().getTime() + ".png";try{// 构造URLURL url = new URL(urlString);// 打开连接URLConnection con = url.openConnection();//设置请求超时为20scon.setConnectTimeout(20 * 1000);//文件路径不存在 则创建File sf = new File(savePath);if (!sf.exists()) {sf.mkdirs();}//jdk 1.7 新特性自动关闭try (InputStream in = con.getInputStream();OutputStream out = new FileOutputStream(sf.getPath() + "//" + filename)) {//创建缓冲区byte[] buff = new byte[1024];int n;// 开始读取while ((n = in.read(buff)) >= 0) {out.write(buff, 0, n);}} catch (Exception e) {return false;}} catch (Exception e) {return false;}log.info("【下载图片成功,本地地址:{}】" , savePath + filename);return true;}/*** 是否包含中文* @param str* @return*/public static boolean isContainChinese(String str) {Pattern p = Pattern.compile("[\u4e00-\u9fa5]");Matcher m = p.matcher(str);if (m.find()) {return true;}return false;}}
3、核心测试代码
大部分网站都是在html文档加载之后,在预定义的div里去异步请求加载数据,因此在打开网页时,需要停顿1-5秒(看网速和网站性能)。
import com.hqyj.cardata.util.SeleniumUtil;import lombok.extern.slf4j.Slf4j;import org.jsoup.Jsoup;import org.jsoup.nodes.Document;import org.jsoup.nodes.Element;import org.jsoup.select.Elements;import org.junit.jupiter.api.Test;import org.openqa.selenium.By;import org.openqa.selenium.JavascriptExecutor;import org.openqa.selenium.WebDriver;import org.openqa.selenium.WebElement;import org.openqa.selenium.chrome.ChromeDriver;import org.openqa.selenium.chrome.ChromeOptions;import org.springframework.boot.test.context.SpringBootTest;import org.springframework.util.StringUtils;import java.io.IOException;@Slf4j@SpringBootTestclass CarDataApplicationTests {@Testvoid huabanSearchSeleniumData() throws IOException {log.info("huabanData start!");String baseUrl = "https://huaban.com/search?q=";String parentFile = "huaban";System.setProperty("webdriver.chrome.driver", SeleniumUtil.CHROMEDRIVERPATH );// chromedriver localPathChromeOptions chromeOptions = new ChromeOptions();chromeOptions.addArguments("--remote-allow-origins=*");chromeOptions.addArguments("–no-sandbox"); //--start-maximizedWebDriver driver = new ChromeDriver(chromeOptions);String[] searchs = {"动漫" , "头像" , "情侣" , "AI" , "玫瑰花" , "PPT" , "深圳" , "广州" , "亚洲" , "别墅" , "区域"};String[] sortSearchName = {"dm" , "tx" , "ql" , "ai" , "mgh" , "ppt" , "sz" , "gz" , "yz" , "bs" , "qy"};for (int i = 0; i < searchs.length; i++) {getHuabanSearchData(driver , baseUrl , searchs[i] , sortSearchName[i] , parentFile );}driver.quit();log.info("huabanData end!");}private void getHuabanSearchData(WebDriver driver, String baseUrl , String searchName , String sortName , String parentFile) {String url = baseUrl + searchName;driver.get(url);WebElement mainSelectE = driver.findElement(By.cssSelector("div.kgGJbqsa"));//等待文档加载(大部分网页都是动态加载)SeleniumUtil.sleep(2000);JavascriptExecutor jsDriver = (JavascriptExecutor) driver;//将java中的driver强制转型为JS类型String js ="window.scrollTo(0, document.body.scrollHeight)";jsDriver.executeScript(js);SeleniumUtil.sleep(2000);//Selenium获取网页内容//转化为Jsoup文档处理Document doc = Jsoup.parse( mainSelectE.getAttribute("outerHTML") );Elements elements = doc.select("a.KGdb7ifV");log.info("a 元素的长度:{}" , elements.size() );if(elements!=null&&elements.size()>0) {for (Element ele : elements) {String imgPath = ele.select("img.hb-image").attr("src");if(StringUtils.isEmpty(imgPath) == false) {log.info("图片地址:{} , 目录:{}" , imgPath , sortName);SeleniumUtil.download(imgPath , parentFile , sortName );}}}SeleniumUtil.sleep(500);}}
3.1、最终效果

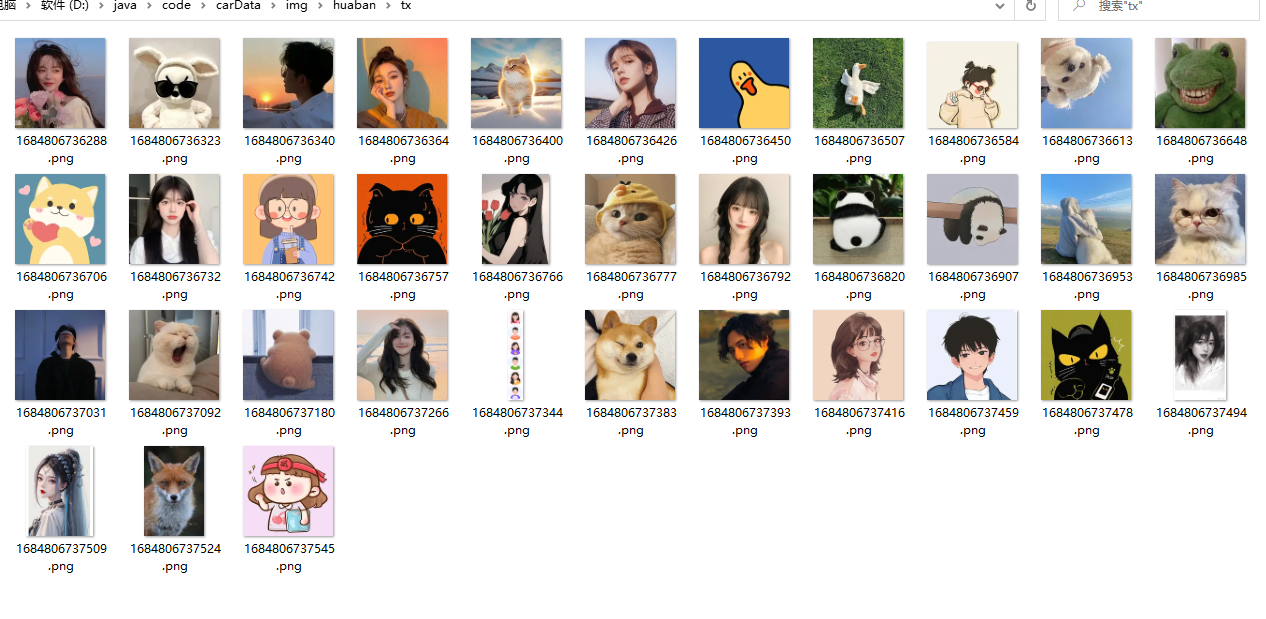


































还没有评论,来说两句吧...