【MybatisPlus】怎么处理百万级以上数据开发案例
1.需求
数据库的表有一百多万条数据,现在要通过定时任务,去把这些数据发送到kafka 第三方。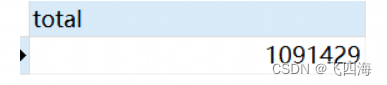
2.遇到的问题
方案1(失败)
首先是想通过分页去一页一页的发送到kafka,但是出现了两个问题。
- 第一是 分页越到后面越慢,经过分析是:当一个数据库表过于庞大,LIMIT offset, length中的offset值过大,则SQL查询语句会非常缓慢
- 第二是 在查询过程中,因为使用的是封装框架的多数据源切换,分页插件也有问题,这个暂时没有解决,直接切换方案。
方案2(成功)
通过查询一些资料,最终使用通过 最大ID方式去 一批一批的拿数据;
之前的sql是:
select * from alert where 1=1 and (first_alert_time BETWEEN ? AND ? ) limit 1000000,100
优化后是:通过每次获取比当前id大的数据,获取100条,处理后,下一次再根据之前最后一条为基础,作为下一次的比较id。
备注:字段已加索引
select * from alert where 1=1 and (first_alert_time BETWEEN ? AND ? ) and alert_seq >1655600780346079 order by alert_seq asc LIMIT 100
如果主键不是自增序列的话,用时间也是可以的,根据创建时间:
select * from alert where 1=1 and (first_alert_time BETWEEN ? AND ? ) and create_time >'2020-01-01 12:29:23' order by create_time asc LIMIT 100
3.解决
使用方案2,分页的问题也解决了,查询慢的问题也解决了。
最后上代码:
public void ltAssetSafeProcess(String username, String password, Integer businessType, String topic, Boolean isToday) {Long startTime = null;Long endTime = null;Integer count = eventSearchTaskMapper.getCount(businessType);if (Objects.nonNull(count) && count == 0) {// 初次上报直接全量startTime = 946656000000L;endTime = new Date().getTime();} else {// 增量上报QueryWrapper<EventSearchTask> queryWrapper = new QueryWrapper();queryWrapper.eq("business_type", businessType);queryWrapper.orderByDesc("create_time");queryWrapper.last("limit 1");EventSearchTask selectOne = eventSearchTaskMapper.selectOne(queryWrapper);startTime = selectOne.getEndTime();endTime = new Date().getTime();}// 处理上报批次EventSearchTask eventSearchTask = new EventSearchTask();eventSearchTask.setId($.toString(SnowFlake.nextId()));eventSearchTask.setDataSource(FeignTemplateType.LT_ZC_INFO.getType());eventSearchTask.setStartTime(startTime);eventSearchTask.setEndTime(endTime);eventSearchTask.setTimeDimension("TODAY");eventSearchTask.setBusinessType(businessType);eventSearchTask.setCreateTime(SystemClock.nowDate());// 处理上报批次QueryWrapper<AlertEntity> queryWrapper = new QueryWrapper<>();queryWrapper.lambda().between(AlertEntity::getFirstAlertTime,new Timestamp(startTime),new Timestamp(endTime));Integer alertCounts = alertService.getCount(queryWrapper);//获取总数eventSearchTask.setAlertCount(alertCounts);eventSearchTaskMapper.insert(eventSearchTask);int pageSize = 1000;int pageCount = PageUtils.pageCount(alertCounts, pageSize);//计算页数// 开始上报String lastAlertSeq = null;for (int i = 0; i <= pageCount; i++) {log.info("处理到第:{}页",i);// 使用alertSeq 去增量获取Map<String,Object> params = new HashMap<>();params.put("startTime",new Timestamp(startTime));params.put("endTime",new Timestamp(endTime));params.put("pageSize",pageSize);if(i == 0){// 获取最早的一条数据 最为第一次基点AlertEntity alertEntity = alertService.getStratAlertOne();params.put("alertSeq",alertEntity.getAlertSeq());}else {params.put("alertSeq",lastAlertSeq);}List<AlertEntity> records = alertService.getAlertPages(params);if(records.size() == 0){log.info("数据:{} 条",records.size());}log.info("处理数据:{} 条",records.size());for(AlertEntity entity : records){lastAlertSeq = entity.getAlertSeq();// 异步发送kafkathreadPoolTaskExecutor.submit(() -> {try {JSON.toJSONString(entity, SerializerFeature.WriteMapNullValue);} catch (Exception e) {log.error("数据存在问题--------------------",e);return;}kafkaAnalyzeProducer.send(topic, JSON.toJSONString(entity, SerializerFeature.WriteMapNullValue), new SendCallBack() {@Overridepublic void sendSuccessCallBack(String topic, String msg) {log.info("sendSuccessCallBack--------------{}----------{}",topic,msg);}@Overridepublic void sendFailCallBack(String topic, String msg, Throwable ex) {log.info("sendFailCallBack--------------{}----------{}---------{}",topic,msg,ex);}});});}}}






























")



还没有评论,来说两句吧...