《专题三分布式系统》之《第三章 集中式缓存Redis》之 《第四节 Memcached》
《3.4.1 Memcached协议》
Memcached相对于Redis的特点:
没有redis的复杂数据结构;
多线程(Redis6.0之后有多线程的io);
CAS?
《3.4.2 Memcached工作原理及优缺点》
- LIbevent库,IO多路复用



- Memcached vs Redis:
| 比较项 | Memcached | Redis |
|---|---|---|
| 多线程 | 单线程(6.0以前) | |
| 高可靠 | 官方支持主从,哨兵,集群等 | |
| 数据持久化 | 更完备 | |
| 存储语义 | 只支持String | 更丰富 |
| 数据规模 | ExtStore伪持久化,更大 | 单机 8-16G |
《3.4.3 缓存中间件实践之缓存和数据库一致性更新原则》
- 15分 结构1:本地缓存:

结构2:
结构3:
- Cache-Aside的4种更新模式:
- 先更db,再更cache,或者相反,都至少可能存在两种问题:
1,第一步成功,第二步失败,则db与cache不一致
2,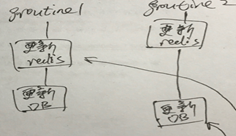
- 先更db,再更cache,或者相反,都至少可能存在两种问题:
- 先删cache,再更db可能的问题:
两个并发进程,一个是更新操作,另一个是查询操作,更新操作删除缓存后,查询操作没有命中缓存,会把老数据读出来后放到缓存中,然后更新操作更新了DB。于是,在缓存中的数据还是老的数据,导致缓存中的数据是脏的
- 先删cache,再更db可能的问题:
- 先更db,后删cache可能的两种问题:
1,第一步成功,第二步失败,则db与cache不一致
2,一个是读操作,但是没有命中缓存,然后就到数据库中取数据,此时来了一个写操作,写完数据库后,让缓存失效,然后,之前的那个读操作再把老的数据放进去,所以,会造成脏数据。
- 先更db,后删cache可能的两种问题:
- 45分: 写多读少的场景,更适合删cache的模式
- Read/Write Through的套路是把更新数据库的操作由缓存自己代理了

- 50分: Write Behind(Write Back)
达成最终一致性的办法:
- 54:40 过期时间TTL:

- 56:40 第三方同步组件进行异步更新:

- 57:59 重试机制,用消息队列

或者不侵入业务逻辑的办法:
60分: 强一致性
可以使用事务或者分布式锁等手段:
附左耳朵耗子陈皓的一篇缓存更新的套路,写得挺不错。
old《专题二》之《3.3.3 memcached集群方案》
- memcached集群的客户端方案:xmemcached
memcached集群的代理中间件方案: Twemproxy (也同样可用于redis)
old《专题二》之《3.3.4 memcached分布式算法》
- 有用到一致性哈希的:kafka, hadoop, mycat分库分表,es, memcache, redis
- 解决一致性哈希算法不均衡(即倾斜)的办法:提前分配虚拟节点:



































还没有评论,来说两句吧...