My SQL常用命令及其知识点
练习题1:大概两百多行,需要的可以关注一下,私我分享给你

思维导图:需要的可以关注一下,私我分享给你
My SQL基本概念:
数据库的英文单词:DataBase 简称:DB
什么是数据库?
用于存储和管理数据的仓库
数据库的特点:
1.持久化存储数据的,其实数据库就是一个文件系统.
2.方便存储和管理数据
3.使用了统一的方式操作数据库—SQL
My SQL服务启动
1.手动
2.cmd-services.msc打开服务的窗口
3.使用管理员打开cmd
net start mysql:启动数据库
net stop mysql:关闭数据库
登录与退出
登录:
1.mysql -uroot -p密码
2.mysql -hip -uroot -p密码连接目标的密码
3.mysql —host=ip —user=root —password=密码连接目标的密码
退出:
1.exit
2.quit
定义语言
用来定义数据库对象:数据库.表.列等
操作数据库:
查看:数据库
查看当前数据库show databases;#显示数据库的名字
创建:数据库
#创建数据库create database heima;#特殊的创建数据库的方式:只有数据库不存在时候才创建,存在不创建create database if not exists heima;
删除数据库
#删除数据库drop database heima;#特殊的删除方式:只有数据库存在时才删除drop database if exists heima;
使用:数据库
#使用场景:#应用场景:当有多个数据库时,需要进行数据库的切换.例如现在使用的是A数据库需要切换到B数据库上:use heima;#查看使用那个数据库select database();
修改:数据库:
#通常是修改数据库的编码表(字符集)例如现在把heima的数据库修改为GBK;alter database heima charset GBK;
操作数据表:
创建数据表:
create table 表名(列名1 数据类型,列名2 数据类型,......列名n 数据类型,);
My SQL常用数据类型:
整数:int小数:double(长度) 长度用来规范该字符串只能存储多少个字符数据的decimal(6,2) 长度(有6个符号位,小数点后最多两位)例如:100.00字符串:varcharcharname varchar(5) 最多存储5个字符,可变长度[只要不超过5个字符即可]例如:存储"AB" 实际存储的是"AB" (不需要填充空格)name char(5) 最多存储5个字符,可变长度[必须存储5个字符,不够时自动补充空格]例如:存储"AB" 实际存储的是"AB "日期:date 格式:yyyy-MM-dd(年月日)datetime 格式:yyyy-MM-dd HH:mm:ss (年月日)年月日时分秒
常用聚合函数:
count:统计指定列不为NULL的记录行数;
sum:计算指定列的数值和,如果指定列类型不是数值类型,那么计算结果为0;
max:计算指定列的最大值,如果指定列是字符串类型,那么使用字符串排序运算;
min:计算指定列的最小值,如果指定列是字符串类型,那么使用字符串排序运算;
avg:计算指定列的平均值,如果指定列类型不是数值类型,那么计算结果为0;
查看当前数据库下所有表:
show tables;
查看表结构:
desc 数据表表名;
删除表
删除student的表drop table student;特殊的删除数据表的方式:只有在表存在的时候才会删除drop table if exists student;
修改表
修改表的名字alter table 表的名字 rename to 新表的名字;
操作表中数据列
添加:新列 新增一列
alter table 表名 add 新列名 数据类型;
删除:列 删除已有列
alter table 表名 drop 列名;alter table 表名 drop 列名,drop 列名;
修改:列
修改列名#仅修改列名alter table 表名 change 原列名 新列名 原有数据类型;#仅修改数据类型alter table 表名 change 原列名 原列名 新数据类型;#修改列名和数据类型alter table 表名 change 原列名 新列名 新数据类型;#修改数据类型alter table 表名 modify 列名 要修改的数据类型;
DML数据操作语言
针对数据表中的数据进行增删改操作
- 添加一行数据
- 删除一行数据(不能删除一列数据)
修改数据
- 修改单个数据
- 修改多个数据
操作数据:添加数据(insert)
#方式1:给指定的列下添加数据-- 给指定的id和name列添加数据insert into 表名(id,name) values (1, '上海');-- 给指定的表中所有列添加数据insert into 表名(name,gedner,id,score) values ('上海', '男' , 1 ,99.5);#方式2:给所有列下添加数据-- 要求:按照表中列的排列顺序添加数据。 例:student(id,name,gender,score)-- 在mysql中,字符串和字符全部都使用英文单引号表示 (双引号也可以)insert into 表名 values (1, '上海', '男' , 99.5);#正确写法insert into 表名 values ('上海', '男' , 1 ,99.5);#错误写法#方式3:批量添加数据insert into 表名(name,gedner,id,score) values('上海', '男' , 1 ,99.5),('北京', '女' , 2 ,9.5),('广州', '男' , 3 ,90.5);
操作数据:删除数据(delete)
# 删除:符合条件的记录delete from 表名 where 条件# 删除: 表中所有的记录delete from 表名# 删除表中所有记录truncate table 表名;属于DDL里面truncate table 表名 VS delete from 表名-- delete: 是删除表中的数据行,是一行一行删除表中的数据。-- truncate : 直接删除整张表,在重新创建表 (效率高)delete from student where id in(12,14)删除id为12或者14的记录行delete from student where id=12 orid=14;删除id为12或者14的记录行
操作数据:修改数据(update)
# 没有条件的修改语句update 表名 set 字段1=新值1,字段2=新值2,....-- 以上代码执行完之后: 把表中的对应列下的所有数据全部修改为新值 (慎用)# 带有条件的修改语句 (推荐)update 表名 set 字段1=新值1,字段2=新值2,.... where 条件-- 以上代码执行之后: 只修改符合条件的表中数据值
DQL:数据查询语言
作用:针对数据表中的数据进行查询操作
数据查询:select
简单查询
# 查询指定字段数据select 字段1,字段2,...字段n from 表名;# 查询所有字段数据select * from 表名; -- 开发中不推荐select 字段1,字段2,...字段n from 表名; -- 推荐写法(查询所有列数据,把所有列名全部写出来)# 去除重复记录查询select distinct 字段1,字段2 from 表名;# 查询时起别名-- 给查询的字段起别名select 字段1 AS 别名1 , 字段2 , 字段3 别名3 ... from 表名;-- 给查询的表起别名select 表别名.字段1, 表别名.字段2, 表别名.字段3 from 表名 AS 表别名;
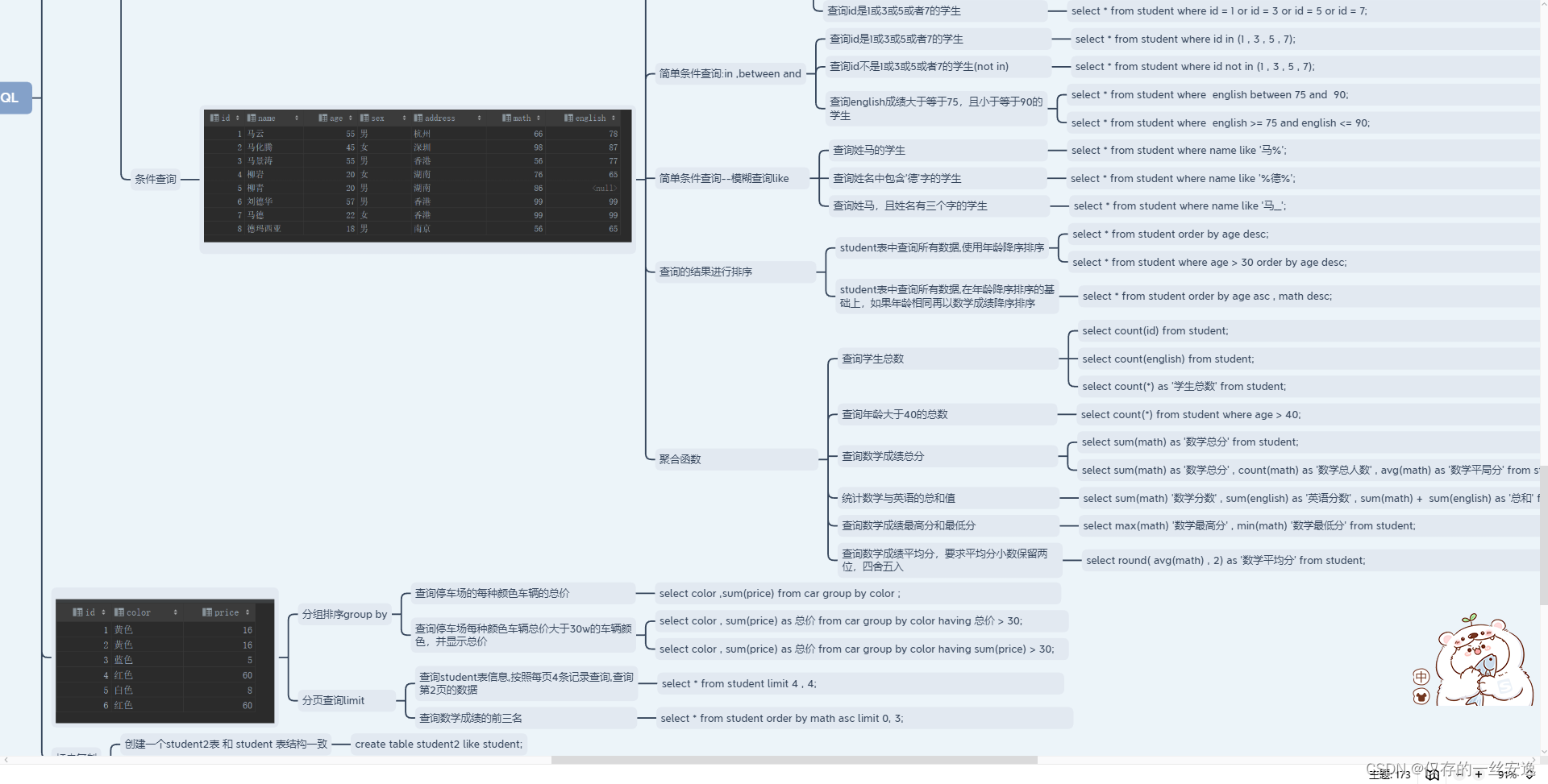
条件查询
select 字段1,字段2,...字段n from 表名 where 条件列表;not in 取反大于等于50并且小于等于90between 50 and 90(范围50-90)查询空值 is null查询地址不为空 is not null;
模糊查询
在京东上,搜索: 手机京东就会去检索:包含"手机"关键字的所有相关信息。 例: 小米手机、 手机膜、 手机壳、苹果手机充电器这种方式:就是模糊查询# 在mysql中可以进行:模糊查询select 字段1,字段2,...字段n from 表名 where 字段名 LIKE '通配符字符串';-- 通配符字符串: 就是包含mysql通配符的字符串-- mysql通配符: % _-- % : 任意个字符'马%' 马开头'%马%' 前面任意 马 后面任意-- _ : 单个字符'马__' 两个下划线 代表查询姓马的名字三个字;
排序查询
排序查询: 对查询出来的数据进行排序(升序[从小到大]、降序)select 字段1,字段2,...字段nfrom 表名where 条件列表order by 字段1 排序规则1 , 字段2 排序规则2 , ......# 排序规则: 升序、 降序# MySQL中的升序:ASC --默认# MySQL中的降序:DESC
分组查询
-- 分组查询: 通常就是针对数据划分为不同的组,对每组数据进行统计-- 在进行分组统计时:需要使用mysql提供的一些统计函数(聚合函数[聚集在一起合并计算])MySQL中的聚合函数:count(字段) : 按组统计每组的记录数是多少聚合函数不要使用带有null数据的字段作为统计;max(字段): 按组统计每组中指定字段的最大值min(字段): 按组统计每组中指定字段的最小值sum(字段) 按组统计每组中指定字段的总和sum(math+english) 英语和数学总分加起来sum(math)+sum(english)如果存在null.可以使用ifnull(列名 默认值):判断给定的列下的数据是否为null,为null返回默认值 不为null返回字段中的值例如 select ifnull(math,0) 如果是null则返回0,不是null就会返回本身的值avg(字段) 按组统计每组中指定字段的平均值语法:select 聚合函数(字段) from 表名-- 通常聚合函数会和分组查询配合使用注意事项 : null数据不参与聚合函数的计算# 分组查询的语法select 字段1,字段2,...字段nfrom 表名where 条件列表[分组前条件过滤]group by 字段1,字段2,....having 分组后的条件过滤-- 分组SQL代码中的注意事项:1. 使用了group by后,查询的字段必须和分组字段保持一致#错误代码: 语法报错select name , address , age #name字段没有出现在group by后面from studentgroup by address, age #按照address和age分组,没有name2. 使用了group by后,查询的字段和分组字段不一致时,必须保证查询字段使用了聚合函数#正确写法: 未出现在group by后面的字段,要查询时可以放在聚合函数中select count(name) , address , age #name字段没有出现在group by后面from studentgroup by address, age #按照address和age分组,没有namewhere 和 having的区别:1. where是在分组之前执行的条件过滤(条件不满足的,不会参与分组)having是在分组之后执行的条件过滤2. where条件中不能书写:聚合函数having条件中可以书写:聚合函数having不能单独使用,必须跟在group by后面(没有分组就一定没有having)
分页查询
问题:当数据表中有1000W条数据时,使用”select * from 表名”查询所有数据,会有什么问题?
答案:查询非常慢。 给用户展示的数据也不友好(一次让用户看1000W的数据)
开发中,通常针对体量大的数据,会进行:分页查询
- 一次查询出一小部分数据,给用户展示
用户:通过”下一页”,进行后缀数据的查询
mysql中的分页查询
select 字段列表 from 表名 limit 起始位置 , 限定条数[要查询的条数];
— 起始位置: 从数据表的哪一行开始进行查询
— 限定条件: 要查询多少条数据针对mysql数据库,分页查询的公式:
起始位置 = (页码-1)*每页显示条数例如:跳过前面1条显示4条;
select *from student limit 1,4;起始位置是0是可以省略前面的数
select from student limit 4;
不省略的话
select from student limit 0,4;
完整的SQL语句:
select 字段列表 -- 只在说到列表,就表示可以书写多个字段from 表where 分组前条件列表 -- 可以有多个条件group by 分组字段列表having 分组后条件列表 -- 只有分组了才会有用order by 排序字段列表limit 起始位置,查询条数-- mysql语句的执行,并不像java语言一样,从前到后依次执行SELECT语句的执行顺序:1. from 表2. where 分组前条件列表3. group by 分组字段列表4. having 分组后条件列表5. select 字段列表6. order by 排序字段列表-- 查询出数据结果之后,才进行排序7. limit -起始位置,查询语句- 查询出数据结果之后,才进行分页
DCL:数据控制语言
作用:管理数据库的权限、用户



























作为一个窗口?")






还没有评论,来说两句吧...