操作系统底层工作原理
1、CPU指令结构
CPU内部结构
- 控制单元
- 运算单元
- 数据单元
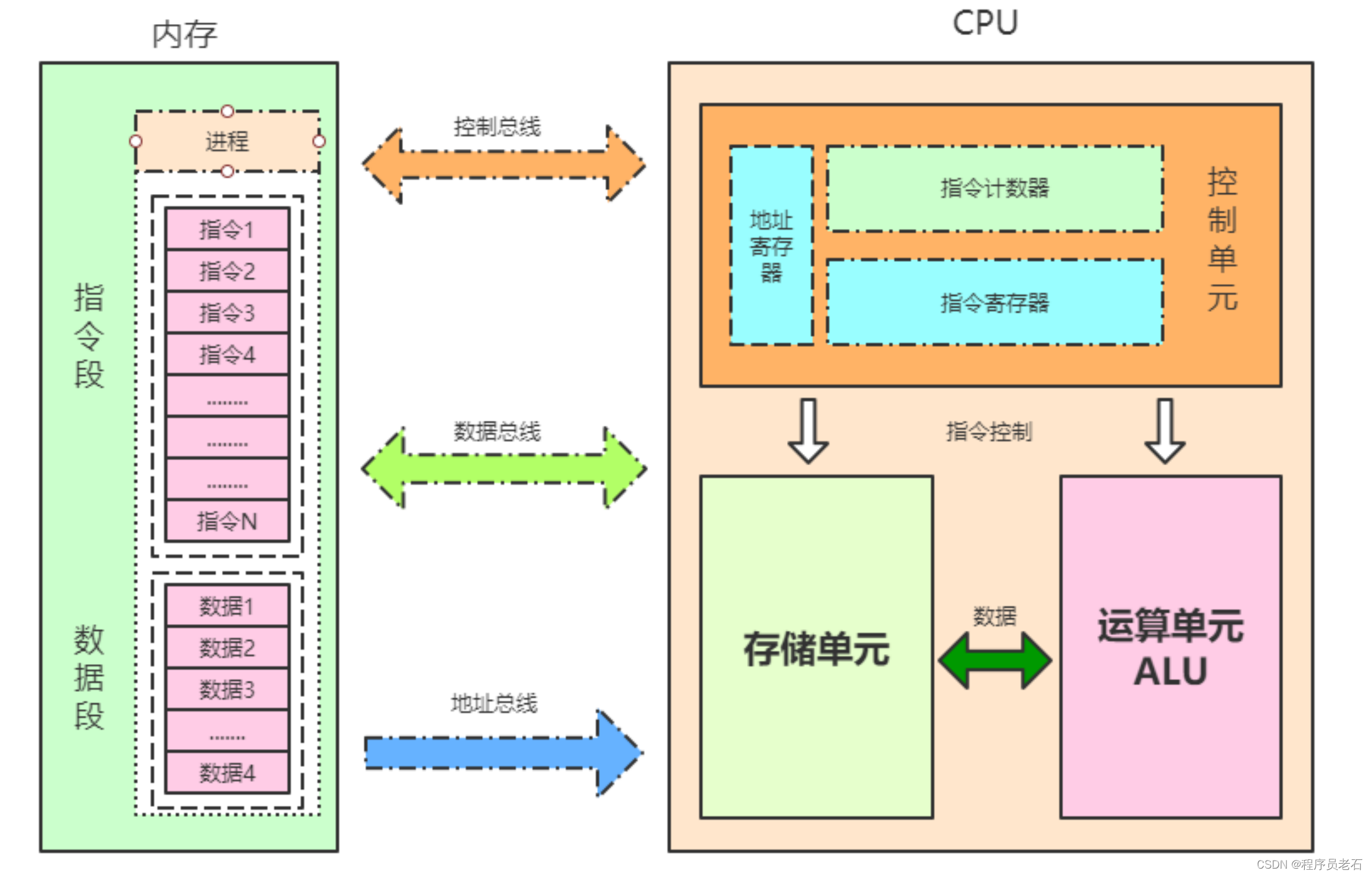
1)控制单元,给我们提供些指令进行控制, 那为什么要用到控制单元呢?像我们的程序代码中,经常要使用到if判断都操作时,就需要使用到控制单元中的指令。
2)运算单元,将运算的逻辑都放在运算单元。
3)存储单元,主要是用来运算结果临时存储的功能,存储单元主要由寄存器和CPU的缓存组成,是CPU中暂时存放数据的地方。存储单元存储了两部分东西,一部分是指令,一部分是数据。
4)内存,内存主要是存放指令和数据。java中的代码通过javac命令编译成class文件,字节码class文件被类加载器加载到JVM的元空间里面,元空间就有了这些指令和数据。
2、CPU缓存结构
现代CPU为了提升执行效率,减少CPU与内存的交互(交互影响CPU效率),一般在CPU上集成了多级缓存架构,常见的为三级缓存结构
一个CPU可以使多核的,一台电脑上也可安装多个CPU
以下CPU是一个单CPU 4核(物理核)、8个逻辑处理器(一个物理核可以同时执行两个线程)、三级缓存(L1、L2、L3)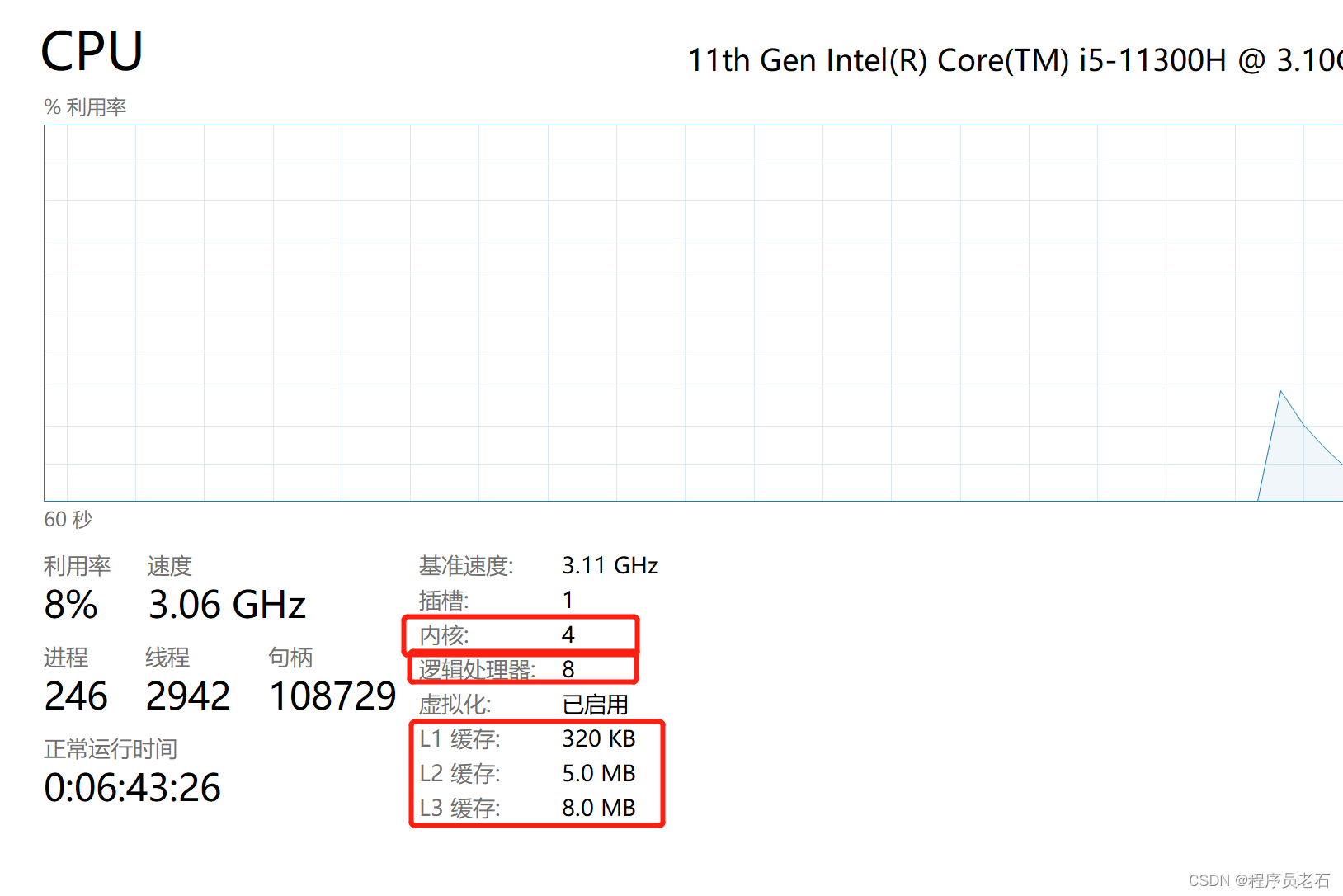
1)为什么要在CPU上设计三级缓存呢?
摩尔定律:每18个月CPU性能至少提升一倍。
内存的发展速度远远跟不上CPU的发展速度,因此,CPU的性能远远要高于内存,由于CPU到内存中读取指令是一个很复杂的过程,效率很低。CPU和内存在主板的不同位置,两者之间的通信就相当耗时了。那么为了减少CPU和内存之间的交互,在CPU上设计了缓存。
2)为什么三级缓存的大小依次递增的?
三级缓存的速度:
CPU中的寄存器 > L1 > L2 > L3 > 内存
存储器存储空间大小:内存 > L3 > L2 > L1 > 寄存器
L1一级缓存是离CPU内核最近的缓存
内存中读取的数据会先放到L3,再将L3的数据拷贝到L2,再将L2的数据拷贝到L1,再从L1中的数据拷贝到CPU的寄存器中,CPU操作的存储空间永远是寄存器中存取。每一个CPU都有一个自己独有的寄存器,这个寄存器只有自己的CPU可以访问,其他的CPU不能访问。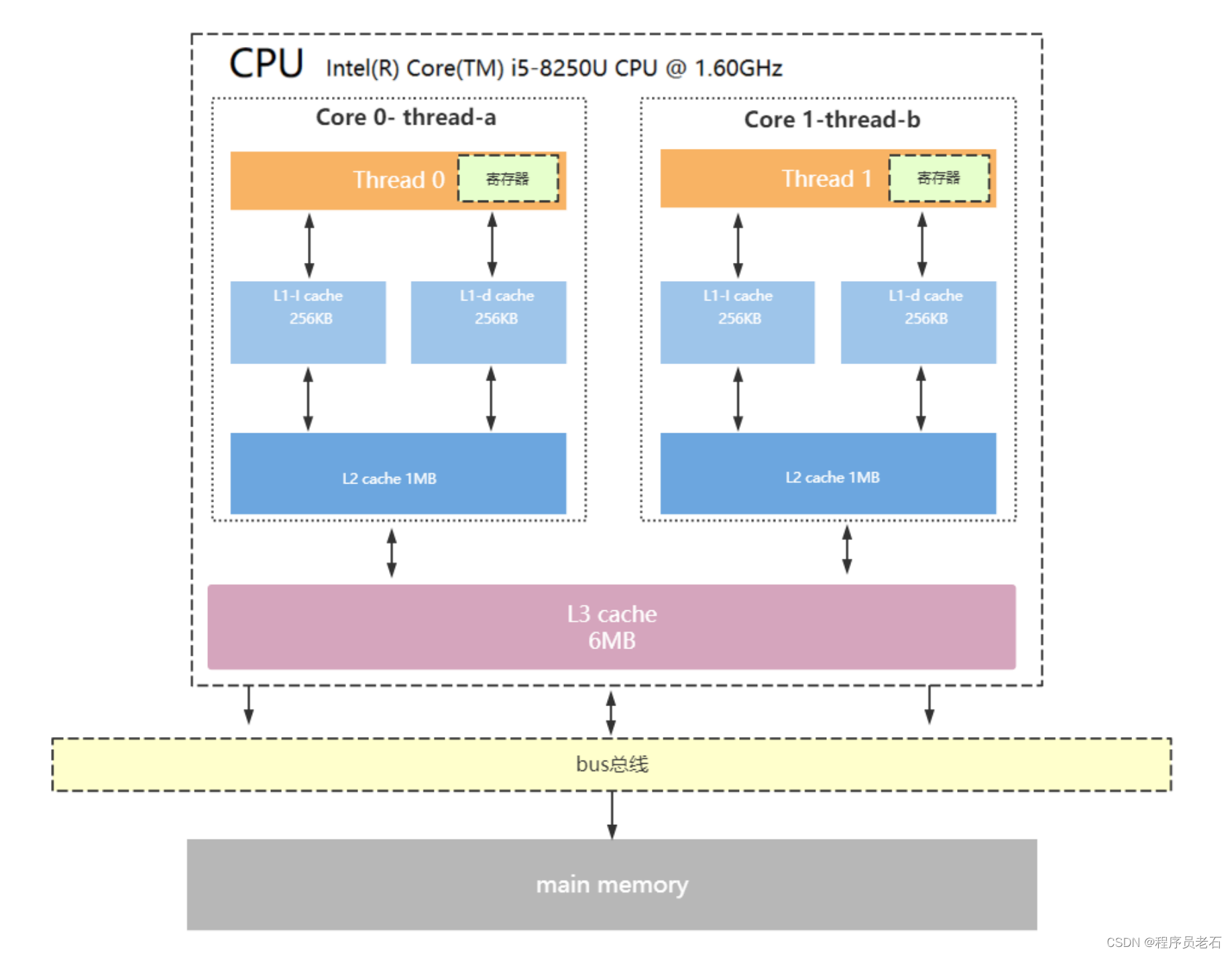
L3缓存是整个CPU上所有内核共享的,L1和L2是CPU上每个内核独享的。L1在上图中做了逻辑上的划分,划分为两部分,一部分存储指令,一部分存储数据。
3)CPU读取数据的过程:
首先CPU从L1缓存中找,如果没有找到则从L2缓存中找,如果没有找到,则从L3缓存中找,如果没有找到,则从内存中找。
读取到的数据不能立刻存放到寄存器中,会先存放到L3缓存中,再拷贝一份到L2缓存和L1缓存中,再读取到寄存器中。
4)空间局部性原则(Spatial Locality):如果一个存储器的位置被引用,那么将来他附近的位置也会被引用。比如顺序执行的代码、连续创建的两个对象、数组等。CPU会将它相邻的数据加载进内存。
public class TwoDimensionalArraySum {private static final int RUNS = 100;private static final int DIMENSION_1 = 1024 * 1024;private static final int DIMENSION_2 = 6;private static long[][] longs;public static void main(String[] args) throws Exception {/** 初始化数组*/longs = new long[DIMENSION_1][];for (int i = 0; i < DIMENSION_1; i++) {longs[i] = new long[DIMENSION_2];for (int j = 0; j < DIMENSION_2; j++) {longs[i][j] = 1L;}}System.out.println("Array初始化完毕....");long sum = 0L;long start = System.currentTimeMillis();for (int r = 0; r < RUNS; r++) {for (int i = 0; i < DIMENSION_1; i++) {//DIMENSION_1=1024*1024for (int j=0;j<DIMENSION_2;j++){//6sum+=longs[i][j];}}}System.out.println("spend time1:"+(System.currentTimeMillis()-start));System.out.println("sum1:"+sum);sum = 0L;start = System.currentTimeMillis();for (int r = 0; r < RUNS; r++) {for (int j=0;j<DIMENSION_2;j++) {//6for (int i = 0; i < DIMENSION_1; i++){//1024*1024sum+=longs[i][j];}}}System.out.println("spend time2:"+(System.currentTimeMillis()-start));System.out.println("sum2:"+sum);}}
结果: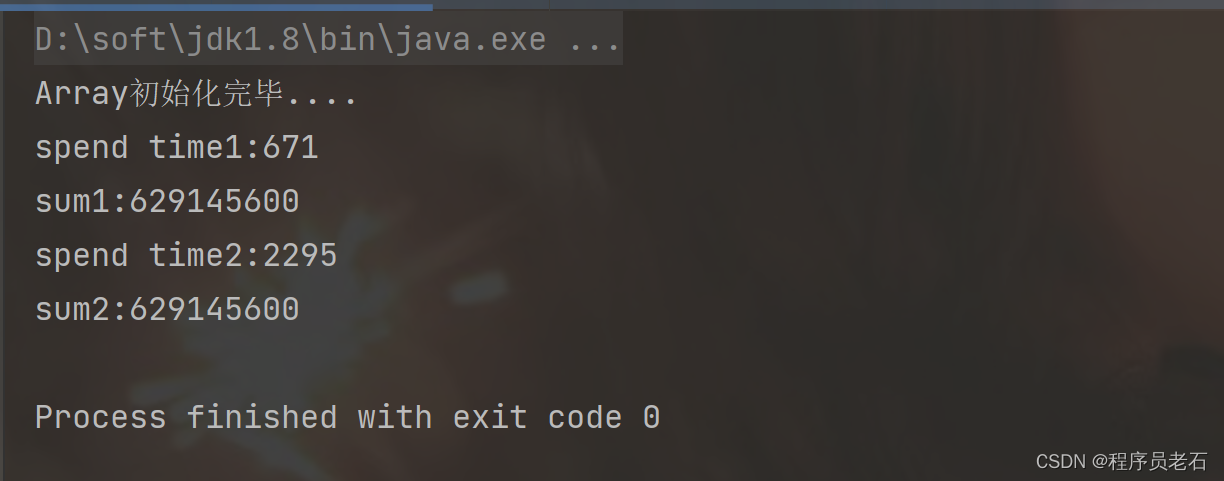
以上代码是创建了一个二维数组,第一种方式是按行循环相加,第二种是按列循环相加。安装CPU的空间局部性原则,第一种的循环方式远远要高于第二种,因为CPU在按行循环的时候就将相邻的数据加载到内存中,而按列则只能一个一个加载到CPU的内存中。
5)时间局部性原则:如果一个信息项正在被访问,那么在近期它很可能还会被再次访问。CPU不会立即将其清除。
6)内核空间和用户空间
4 GB 的内存空间中,只有 3 GB 可以用于用户应用程序。
用户方式下用的是
一般的堆栈(用户空间的堆栈),而内核方式下用的是固定大小的堆栈(内核空间的对战,一
般为一个内存页的大小),即每个进程与线程其实有两个堆栈,分别运行与用户态与内核
态。
内核线程模型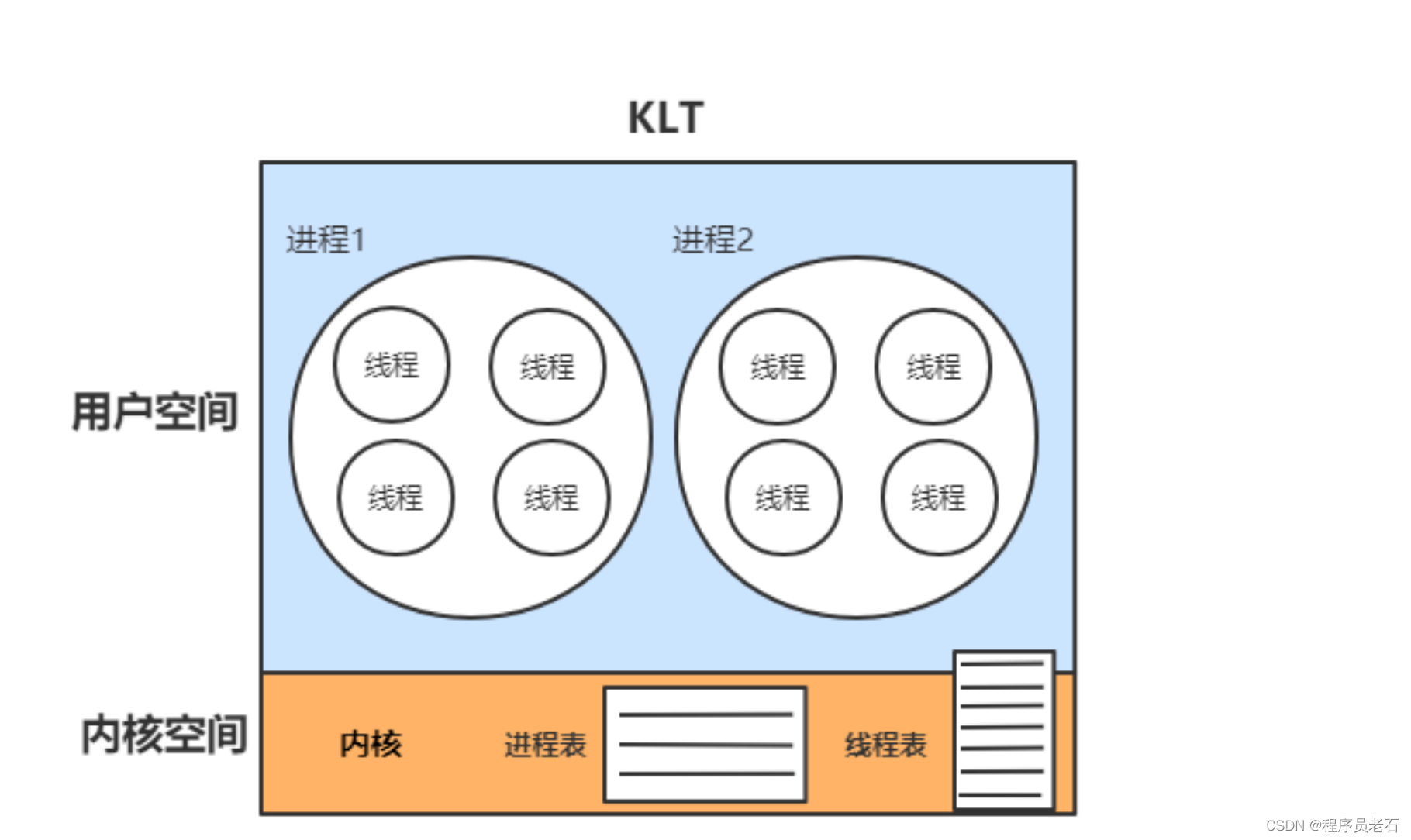
用户线程模型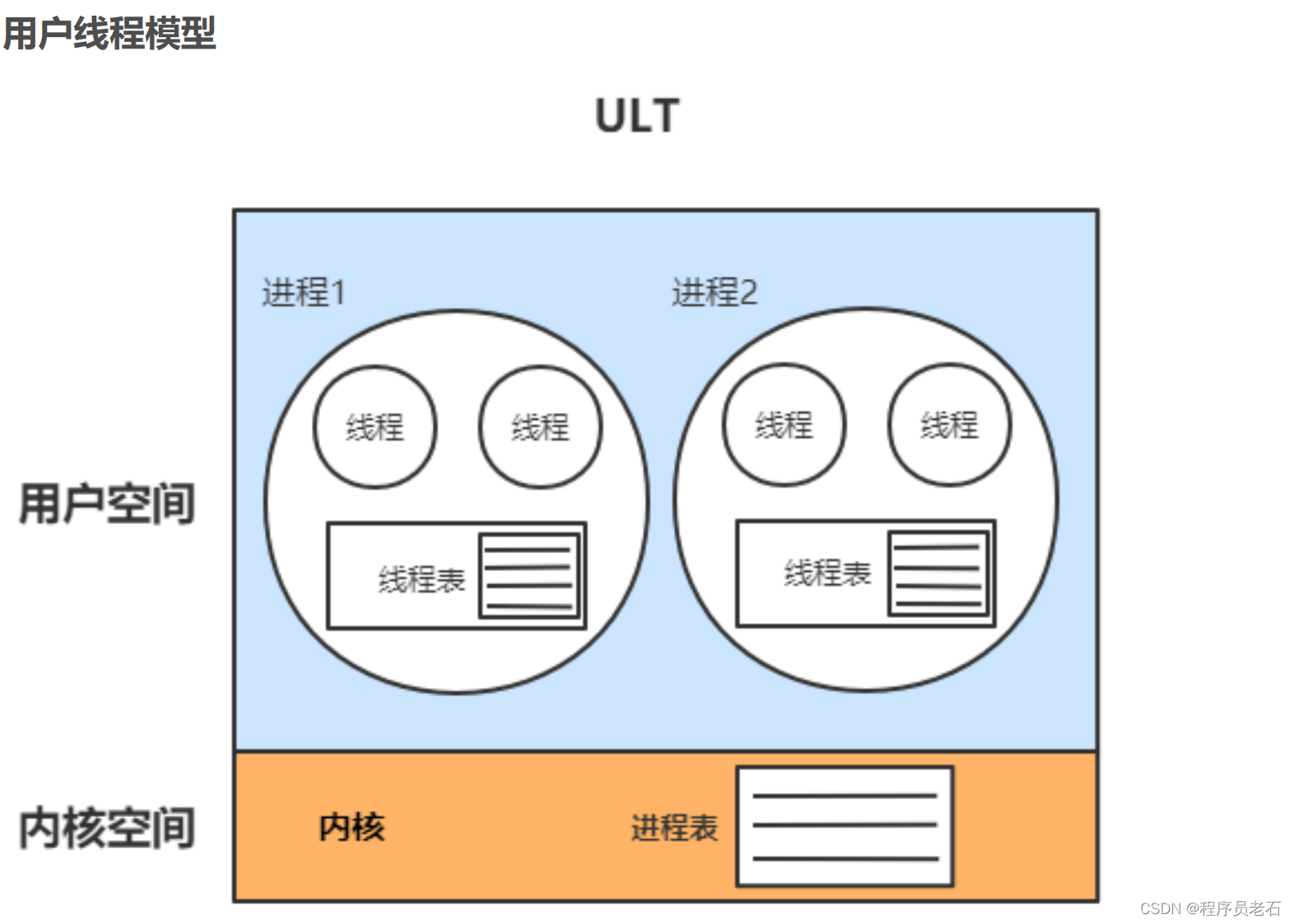
一般像JVM、第三方APP、360浏览器等软件都是运行在用户空间中。操作系统一般运行在内核空间。为什么要分用户空间和内核空间,主要是为了保护我们的操作系统。
JVM在创建线程的时候,实质上是调用操作系统中的库进行创建的,而JVM是位于在用户空间,操作系统是位于在内核空间中,原来所在的用户空间的堆栈就不在有了,而是转移到了内核空间里面。所有一个进程或一个线程其实不是只有一种堆栈,而是有两个堆栈,一个在用户空间,一个在内核空间。
内核线程模型和用户线程模型的本质区别
线程的创建、调度、销毁又程序本身管理的则是用户线程模型(ULT)
线程的创建、调度、销毁又操作系统管理的则是内核线程模型(KLT)
java用的是KLT(内核线程模型)


























还没有评论,来说两句吧...