mysql增删改查基本操作
mysql创建(用户)表
DROP TABLE if `base_member` ;CREATE TABLE `base_member` (`id` int(11) NOT NULL AUTO_INCREMENT,`nickname` varchar(255) DEFAULT NULL COMMENT '昵称',`avatar_url` varchar(255) DEFAULT NULL COMMENT '头像',`gender` char(1) DEFAULT NULL COMMENT '性别',`real_name` varchar(50) DEFAULT NULL COMMENT '姓名',`mobile` varchar(50) DEFAULT NULL COMMENT '手机号码',`login_name` varchar(50) DEFAULT NULL COMMENT '登录账号',`password` varchar(100) DEFAULT NULL COMMENT '密码',`user_type` int(11) DEFAULT NULL COMMENT '用户类型',`school_id` int(11) DEFAULT NULL COMMENT '书院id',`class_id` int(11) DEFAULT NULL COMMENT '班级id',`create_time` datetime DEFAULT NULL COMMENT '创建时间',PRIMARY KEY (`id`) USING BTREE//指定id列为主键,使用B树作为索引。) ENGINE=InnoDB AUTO_INCREMENT=90 DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='学生用户';
要是不加索引
DROP TABLE if `base_member`;CREATE TABLE `base_member`(`id` int(11) NOT NULL PRIMARY KEY AUTO_INCREMENT ,`nickname` varchar(255) DEFAULT NULL COMMENT '昵称',`avatar_url` varchar(255) DEFAULT NULL COMMENT '头像',`gender` char(1) DEFAULT NULL COMMENT '性别',`real_name` varchar(50) DEFAULT NULL COMMENT '姓名',`mobile` varchar(50) DEFAULT NULL COMMENT '手机号码',`login_name` varchar(50) DEFAULT NULL COMMENT '登录账号',`password` varchar(100) DEFAULT NULL COMMENT '密码',`user_type` int(11) DEFAULT NULL COMMENT '用户类型',`school_id` int(11) DEFAULT NULL COMMENT '书院id',`class_id` int(11) DEFAULT NULL COMMENT '班级id',`create_time` datetime DEFAULT NULL COMMENT '创建时间')ENGINE=InnoDB AUTO_INCREMENT=90 DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='学生用户';
增删改查sql语句(base_member是要查询的表名):
在表中插入/增加一条数据:
insert into base_member(id,nickname,orderName) values( 1, ‘张三’,‘http://localhost:8080/img/avatar.png’,‘1’,'张小三‘ ,123456,123,1234,1,2,1,2023-01-24 11:45:09);
在表中插入/增加多条数据:
insert into base_member(id,nickname,orderName) values( 1, ‘张三’,‘http://localhost:8080/img/avatar.png’,‘1’,'张小三‘ ,123456,123,1234,1,2,1,2023-01-24 11:45:09),
(2, ‘李四’,‘ http://localhost:8080/img/avatar.png’,‘1’,'李小四‘ ,12345,12,123,10,2,1,2023-01-24 11:45:09),(3, ‘王五’,‘http://localhost:8080/img/avatar.png’,‘1’,'王小五‘ ,1234,11,12,1,2,1,2023-01-24 11:45:09);删除数据:
drop table base_member;删除表结构和数据
truncate base_member; 只删除数据,不删除表结构,删除后不可恢复
delete from base_member; 删除整个表的数据,不删除表结构删除一条数据:(修改编号1的用户)
delete from base_member where id=1;
修改一条数据:(修改编号2的学生名字为赵莹)
update base_member set real_name =’赵莹’where Sid =’2’
查询一条数据:(查询名字为赵莹的用户表数据)
select * from base_member where real_name=’赵莹’;
查询5条数据(可以查询任意多条,如果不选查询的是整个表的数据):
select * from base_member limit 5;
- 查询第几条到第几条数据(至于第几条到第几条由自己决定):
select * from base_member limit 1,5;
拓展:
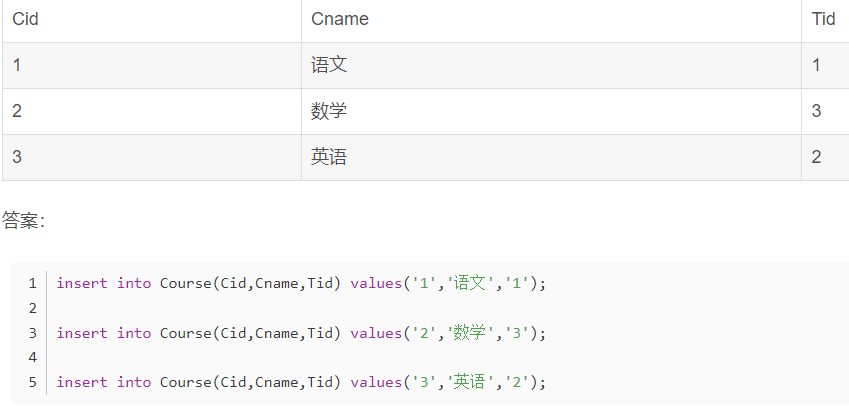
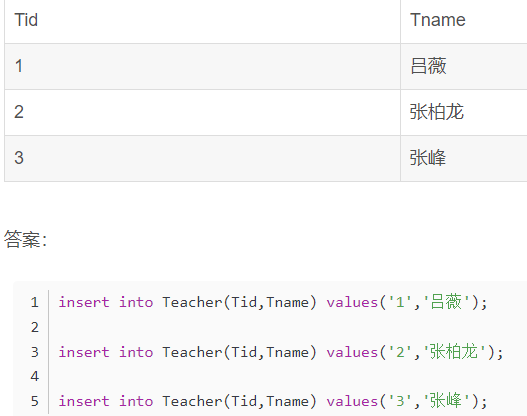
多表查询:两表联查
用inner join联查两个表select teacher.Tname from teacherinner join coursewhere teacher.Tid = course.Tid and course.Tid = '1'统计语文成绩大于70的学生信息select a.Sname,a.Sage,a.Ssex,b.score from Student a, SC bwhere a.Sid=b.Sid and b.Cid=1 and b.score >70统计各科分数大于80的人select a.Sid,a.Snamefrom student a,(select Sid from scgroup by Sidhaving min(score) > 80) as bwhere b.Sid = a.Sid;
聚合函数、group by 、having 。聚合函数是将“若干行数据”经过计算后聚合成“一行数据”
常用的聚合函数:
1.MAX:返回某列的最大值2.MIN(column) 返回某列的最高值3.COUNT(column) 返回某列的总行数4.COUNT(*) 返回表的总行数5.SUM(column) 返回某列的相加总和6.AVG(column) 返回某列的平均值
下面我们简单使用一下这些聚合函数。
我们计算一下员工表中最大工资和最小工资。
select Max(sal) , Min(sal) from emp;
计算一下工资总和和平均工资。
select sum(sal),avg(sal) from emp;
count函数是计算总行数。count(*)是计算表中总行数。
count(列名)是计算某一列总行数(不包括null值)。
select count(*),count(comm) from emp;
为什么count(*)和count(comm)的值不一样呢?
答案是:聚合函数只作用非null,因为null数据不参与运算。
请大家在使用聚合函数的时候一定要记住这一点,不然计算的结果可能不是你想要的。我们以奖金的平均值来做测试,代码如下:
select avg(comm),avg(ifnull(comm,0)) from emp;
为啥同样是计算comm表明平均值,但是计算出来值不一样呢?null在聚合函数中不参与计算。
avg(comm)只计算了4个人的奖金(关羽,张飞,貂蝉,吴用)取平均值。
而avg(ifnull(comm,0))却是计算了所有人的奖金,取平均值。所以值要小的多,这其中的关键就是用了ifnull() 函数(ifnull函数的作用就是发现值为null后将其值变为0)。
温馨提示:聚合函数使用时注意空值的情况,要配合ifnull函数使用哦~
GROUP BY 语句
下面我们有这样一个需求:
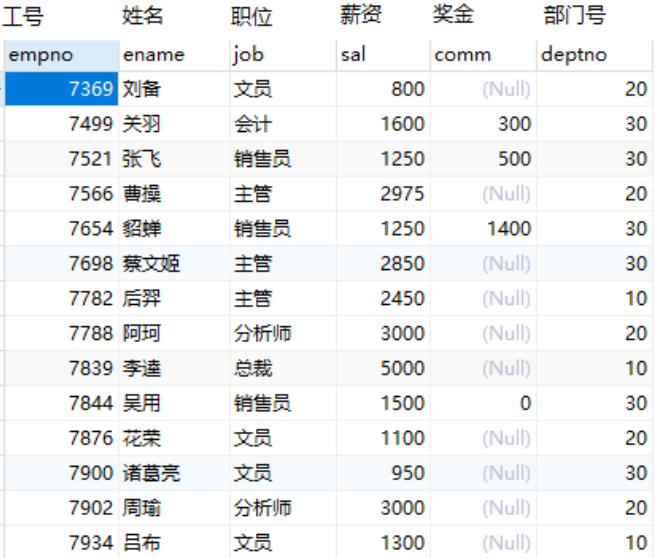
求每个部门所有工资总和。
简简单单的一句话,光用where是很难做到的。但group by 就非常简单(部门号相同的分到一组)
select deptno,sum(sal) from emp groupby deptno;
通过deptno字段对表数据进行分组后,然后通过sum(sal)来计算每个分组的总和。
查询每个部门工资大于1500的的人数。1.每个部门:按照deptno分组,select deptno from emp groupby deptno;2.工资大于1500:where sal >15003.人数:count(*)函数。select deptno,count(*) from emp where sal >1500 groupby deptno;
HAVING用于分组后的再次筛选,只能用于分组。(注意:分组后)
练习:求工资总和大于9000的部门,并按照工资总和排序。
这个问题是接上面:“求每个部门所有工资总和”,再加一条分组后的筛选:
select deptno,sum(sal) total from emp groupby deptno havingsum(sal) >9000orderbysum(sal) asc;
having和where区别:
1.having是分组后,where是分组前2.where不用使用聚合函数,having可以使用聚合函数。3.where在分组之前就会进行筛选,过滤掉的数据不会进入分组。
关键字的执行顺序总结
关键字的书写顺序如下:
1.select2.from3.where4.groupby5.having6.orderby7.limit
关键字的执行顺序如下:
1.from //行过滤2.where3.groupby4.having5.select //列过滤6.order by//排序7.limit//附加
还是以员工表为例,我们以下面这条语句为例子逐步解析一下。
select deptno,sum(sal) total from emp where sal>1000groupby deptno havingsum(sal) >9000orderbysum(sal) asc;
第一步:执行from关键字
等同于执行语句:select * from emp;
第二步:在第一步的基础上执行where
等同于:select deptno from emp where sal >1000;
第三步:在第二步的基础上执行group by
等同于:select deptno from emp where sal >1000groupby deptno;
第四步:在第三步的基础上执行having
等同于:select deptno from emp where sal >1000groupby deptno havingsum(sal) >9000;
第五步:在第三步的基础上选择列。
等同于:select deptno,sum(sal) total from emp where sal >1000groupby deptno havingsum(sal) >9000;
第六步:order by 排序(略)
第七步:limit(略)




























还没有评论,来说两句吧...