【Python】ImportError: cannot import name ‘jaccard_similarity_score‘ from ‘sklearn.metrics‘
一、错误信息
在运行代码时,遇到了一个问题:
---------------------------------------------------------------------------ImportError Traceback (most recent call last)Cell In [117], line 1----> 1 from sklearn.metrics import jaccard_similarity_score2 ovr = OneVsRestClassifier(RandomForestClassifier())3 ovr.fit(X_train, y_train)ImportError: cannot import name 'jaccard_similarity_score' from 'sklearn.metrics' (d:\Anaconda\envs\PyTorch\lib\site-packages\sklearn\metrics\__init__.py)

问题代码为:
from sklearn.metrics import jaccard_similarity_scoreovr = OneVsRestClassifier(RandomForestClassifier())ovr.fit(X_train, y_train)Y_pred_ovr = ovr.predict(X_test)ovr_jaccard_score = jaccard_similarity_score(y_test, Y_pred_ovr)ovr_jaccard_score
二、问题分析
一开始以为是scikit-learn安装出了问题,尝试直接定义jaccard,修改sklearn为scikit-learn都不行,找到好久才发现是引入的包的文件名不对。
2.1 报错:
from sklearn.metrics import jaccard_similarity_score
2.2 原因
新的scikit-learn不再自动修改语法。通过路径找到存放jaccard的py文件,发现其中的jaccard函数名称为jaccard_score
2.3 修改
将 from sklearn.metrics import jaccard_similarity_score改为 from sklearn.metrics import jaccard_score
三、问题再临
我们按照上面的方式修改后,还是出现报错:
ValueError: Target is multiclass but average='binary'. Please choose another average setting, one of [None, 'micro', 'macro', 'weighted'].
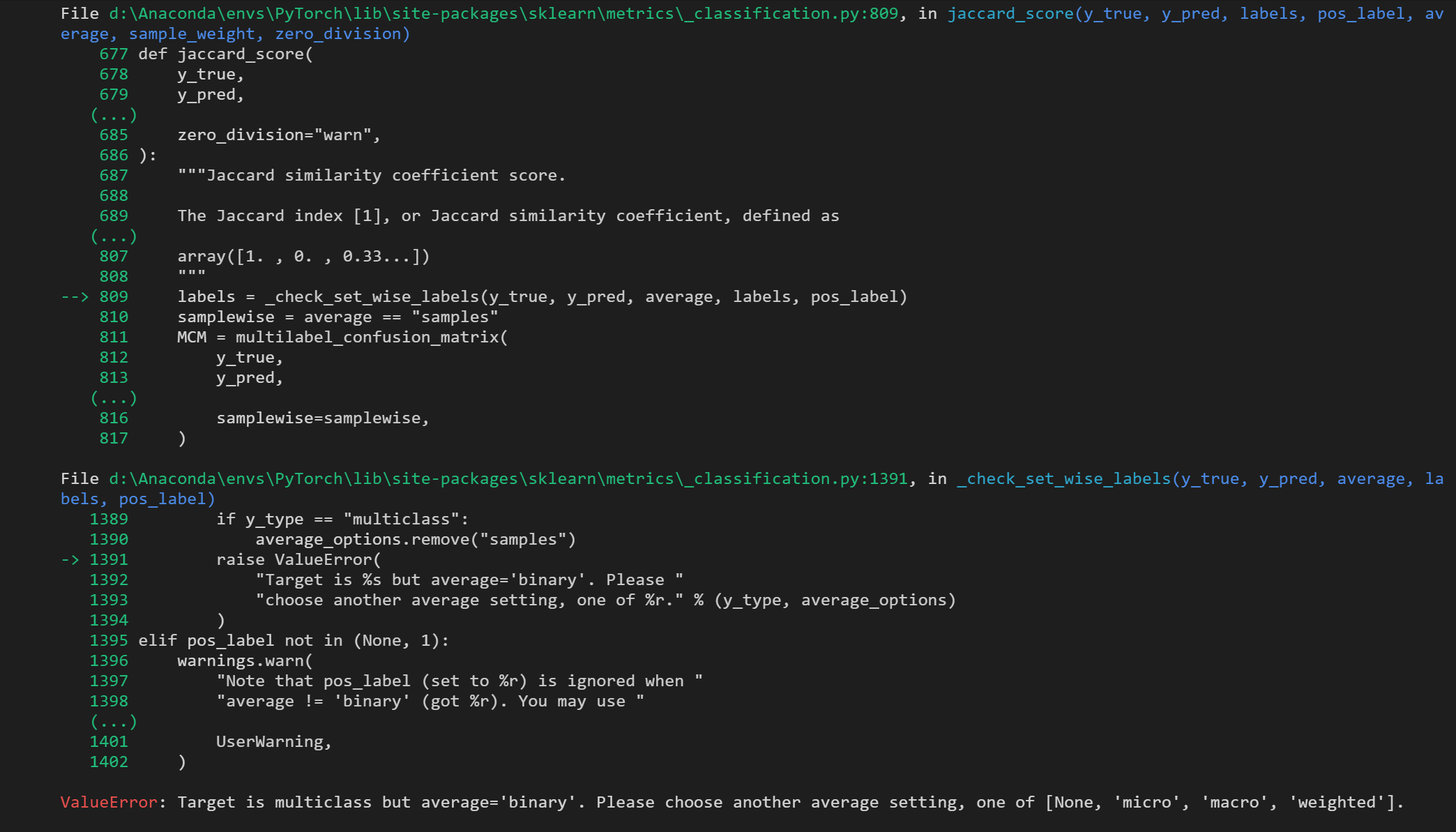
原因:二分类时average参数默认是binary;多分类时,可选参数有micro、macro、weighted和samples。
修改:将jaccard_score(y_true, y_pred)改为jaccard_score(y_true, y_pred,average='micro)
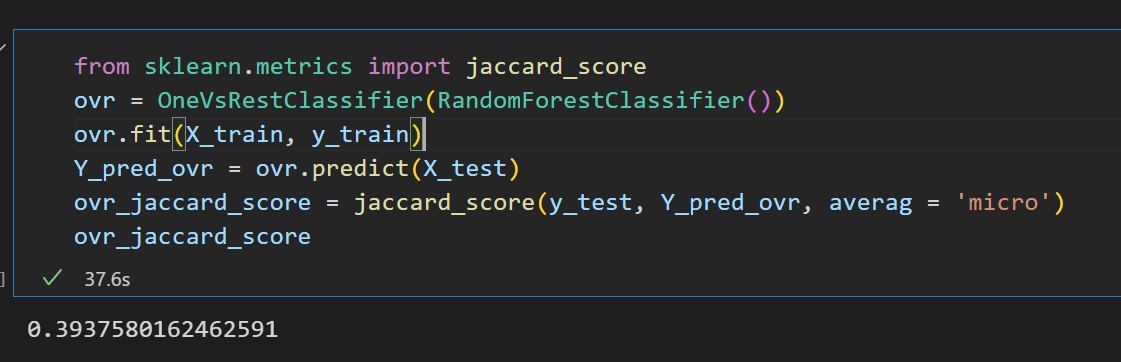
四、问题解决
修改后的代码为:
from sklearn.metrics import jaccard_scoreovr = OneVsRestClassifier(RandomForestClassifier())ovr.fit(X_train, y_train)Y_pred_ovr = ovr.predict(X_test)ovr_jaccard_score = jaccard_score(y_test, Y_pred_ovr, averag = 'micro')ovr_jaccard_score




























![向中国车黑宣战,长城汽车[官宣]第二弹:我们忍够了!!](https://image.dandelioncloud.cn/images/20210923/63b6569c8c0d46a1a1205b30111c3d7c.png "向中国车黑宣战,长城汽车[官宣]第二弹:我们忍够了!!")





还没有评论,来说两句吧...