一文搞懂ByteBuffer使用与原理
前言
已知NIO中有三大组件:Channel,Buffer和Selector。那么Buffer的作用就是提供一个缓冲区,用于用户程序和Channel之间进行数据读写,也就是用户程序中可以使用Buffer向Channel写入数据,也可以使用Buffer从Channel读取数据。
ByteBuffer是Buffer子类,是字节缓冲区,特点如下所示。
- 大小不可变。一旦创建,无法改变其容量大小,无法扩容或者缩容;
- 读写灵活。内部通过指针移动来实现灵活读写;
- 支持堆上内存分配和直接内存分配。
本文将对ByteBuffer的相关概念,常用API以及使用案例进行分析。全文约1万字,知识点脑图如下。

正文
一. Buffer
在NIO中,八大基础数据类型中除了boolean外,都有相应的Buffer的实现,类图如下所示。

Buffer类对各种基础数据类型的缓冲区做了顶层抽象,所以要了解ByteBuffer,首先应该学习Buffer类。
- Buffer的属性
所有缓冲区结构都有如下属性。
| 属性 | 说明 |
|---|---|
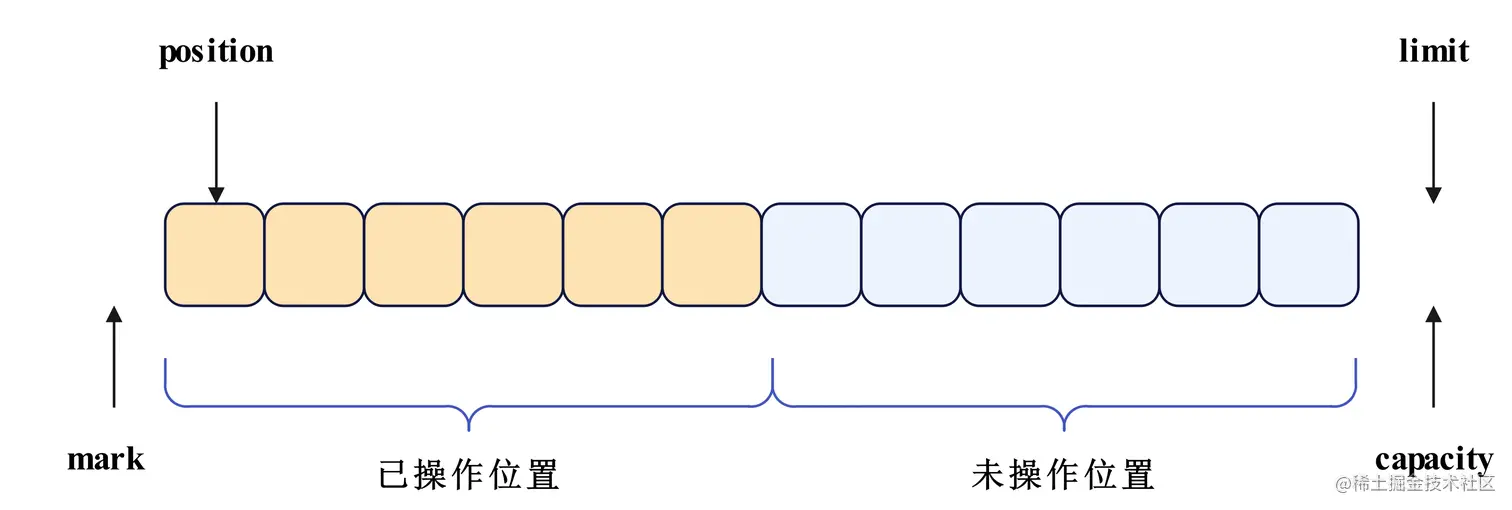
| int position | 位置索引。代表下一次将要操作的元素的位置,默认初始为0,位置索引最小为0,最大为limit |
| int limit | 限制索引。限制索引及之后的索引位置上的元素都不能操作,限制索引最小为0,最大为capacity |
| int capacity | 容量。缓冲区的最大元素个数,创建缓冲区时指定,最小为0,不能改变 |
三者之间的大小关系应该是:0 <= position <= limit <= capacity,图示如下。

除此之外,还有一个属性叫做mark,如下所示。
| 属性 | 说明 |
|---|---|
| int mark | 标记索引。mark会标记一个索引,在Buffer#reset调用时,将position重置为mark。mark不是必须的,但是当定义mark后,其最小为0,最大为position |
关于mark还有如下两点说明。
- position或limit一旦小于mark则mark会被丢弃;
没有定义mark时如果调用了Buffer#reset则会抛出InvalidMarkException。
Buffer的读模式
Buffer有两种模式,读模式和写模式,在读模式下,可以读取缓冲区中的数据。那么对于一个缓冲区,要读取数据时,分为两步。
- 拿到position位置索引;
- 取position位置的数据。
那么Buffer提供了nextGetIndex() 方法和nextGetIndex(int nb) 方法来获取position,先看一下nextGetIndex() 方法的实现。
final int nextGetIndex() {// limit位置是不可操作的if (position >= limit) {throw new BufferUnderflowException();}// 返回当前position// 然后position后移一个位置return position++;}复制代码
nextGetIndex() 方法首先校验一下position是否大于等于limit,因为limit及之后的位置都是不可操作的,所以只要满足position大于等于limit则抛出异常,然后返回当前的position(也就是当前可操作的位置),最后position后移一位。
而nextGetIndex(int nb) 方法,则是用于Buffer的子类ByteBuffer使用,因为ByteBuffer的一个元素就是一个字节,而如果想要通过ByteBuffer获取一个整形数据,那么此时就需要连续读取四个字节。nextGetIndex(int nb) 方法如下所示。
final int nextGetIndex(int nb) {// 判断一下剩余可操作元素是否够本次获取if (limit - position < nb) {throw new BufferUnderflowException();}// 暂存当前positionint p = position;// 然后position后移nb个位置position += nb;// 返回暂存的positionreturn p;}复制代码
拿到position后,实际的读取数据,由Buffer的子类来实现。
- Buffer的写模式
有读就有写,在Buffer的写模式下,写入数据也是分为两步。
- 拿到position位置索引;
- 写入数据到position位置。
写模式下,Buffer同样为获取position提供了两个方法,如下所示。
final int nextPutIndex() {// limit位置是不可操作的if (position >= limit) {throw new BufferOverflowException();}// 返回当前position// 然后position后移一个位置return position++;}final int nextPutIndex(int nb) {// 判断一下剩余可操作元素是否够本次写入if (limit - position < nb) {throw new BufferOverflowException();}// 暂存当前positionint p = position;// 然后position后移nb个位置position += nb;// 返回暂存的positionreturn p;}复制代码
同样,拿到position后,实际的写入数据,由Buffer的子类来实现。
- Buffer读写模式切换
Buffer提供了读模式和写模式,同一时间Buffer只能在同一模式下工作,相应的,Buffer提供了对应的方法来做读写模式切换。
首先是读模式切换到写模式,先看如下示意图。

上图中的情况是缓冲区中的数据已经全部被读完,那么此时如果要切换到写模式,对应的方法是clear() 方法,如下所示。
public final Buffer clear() {// 重置position为0position = 0;// 设置limit为capacitylimit = capacity;// 重置mark为-1mark = -1;return this;}复制代码
注意,虽然方法名叫做clear(),但是实际缓冲区中的数据并没有被清除,而只是将位置索引position,限制索引limit进行了重置,同时清除了标记状态(也就是将mark设置为-1)。切换到写模式后,缓冲区示意图如下所示。

然后是写模式切换到读模式,先看如下示意图。

数据已经写入完毕了,此时如果要切换到读模式,对应的方法是flip(),如下所示。
public final Buffer flip() {// 因为position位置还没写入数据// 所以将position位置设置为limitlimit = position;// 重置position为0position = 0;// 重置mark为-1mark = -1;return this;}复制代码
因为position永远代表下一个可操作的位置,那么在写模式下,position代表下一个写入的位置,那么其实就还没有数据写入,所以调用flip() 方法后,首先将position位置设置为limit,表示数据最多读取到limit的上一个位置,然后重置position和mark。切换到读模式后,缓冲区示意图如下所示。

- Buffer的rewind操作
在使用Buffer时,可以针对已经操作的区域进行重操作,假设缓冲区示意图如下。

再看一下rewind() 方法的实现,如下所示。
public final Buffer rewind() {// 重置position为0position = 0;// 清除markmark = -1;return this;}复制代码
主要就是将位置索引position重置为0,这样就能重新操作已经操作过的位置了,同时如果启用了mark,那么还会清除mark,也就是重置mark为-1。rewind() 方法调用后的缓冲区示意图如下所示。
- Buffer的reset操作
在使用Buffer时,可以启用mark来标记一个已经操作过的位置,假设缓冲区示意图如下。

再看一下reset() 方法的实现,如下所示。
public final Buffer reset() {int m = mark;// 只要启用mark那么mark就不能为负数if (m < 0) {throw new InvalidMarkException();}// 将position重置为markposition = m;return this;}复制代码
在没有启用mark时,mark为-1,只要启用了mark,那么mark就不能为负数。在reset() 中主要就是将位置索引position重新设置到mark标记的位置,以实现对mark标记的位置及之后的位置进行重新操作。reset() 方法调用后的缓冲区示意图如下所示。

二. ByteBuffer
在上一节主要对Buffer进行了一个说明,那么本节会在上一节的基础上,对ByteBuffer及其实现进行学习。
- ByteBuffer的属性
ByteBuffer相较于Buffer,多了如下三个属性。
| 属性 | 说明 |
|---|---|
| byte[] hb | 字节数组。仅HeapByteBuffer会使用到,HeapByteBuffer的数据存储在hb中 |
| int offset | 偏移量。仅HeapByteBuffer会使用到,后面会详细说明 |
| isReadOnly | 是否只读。仅HeapByteBuffer会使用到,后面会详细说明 |
NIO中为ByteBuffer分配内存时,可以有两种方式。
- 在堆上分配内存,此时得到HeapByteBuffer;
- 在直接内存中分配内存,此时得到DirectByteBuffer。
类图如下所示。

因为DirectByteBuffer是分配在直接内存中,肯定无法像HeapByteBuffer一样将数据存储在字节数组,所以DirectByteBuffer会通过一个address字段来标识数据所在直接内存的开始地址。address字段定义在Buffer中,如下所示。
long address;复制代码
- ByteBuffer的创建
ByteBuffer提供了如下四个方法用于创建ByteBuffer,如下所示。
| 方法 | 说明 |
|---|---|
| allocate(int capacity) | 在堆上分配一个新的字节缓冲区。说明如下: 1. 创建出来后,position为0,并且limit会取值为capacity; 2. 创建出来的实际为HeapByteBuffer,其内部使用一个字节数组hb存储元素; 3. 初始时hb中所有元素为0 |
| allocateDirect(int capacity) | 在直接内存中分配一个新的字节缓冲区。说明如下: 1. 创建出来后,position为0,并且limit会取值为capacity; 2. 创建出来的实际为DirectByteBuffer,是基于操作系统创建的内存区域作为缓冲区; 3. 初始时所有元素为0 |
| wrap(byte[] array) | 将字节数组包装到字节缓冲区中。说明如下: 1. 创建出来的是HeapByteBuffer,其内部的hb字节数组就会使用传入的array; 2. 改变HeapByteBuffer会影响array,改变array会影响HeapByteBuffer; 3. 得到的HeapByteBuffer的limit和capacity均取值为array.length; 4. position此时都为0 |
| wrap(byte[] array, int off, int length) | 将字节数组包装到字节缓冲区,说明如下。 1. 创建出来的是HeapByteBuffer,其内部的hb字节数组就会使用传入的array; 2. 改变HeapByteBuffer会影响array,改变array会影响HeapByteBuffer; 3. capacity取值为array.length; 4. limit取值为off + length; 5. position取值为off |
下面结合源码,分析一下上述四种创建方式。
首先是allocate(int capacity),如下所示。
public static ByteBuffer allocate(int capacity) {if (capacity < 0) {throw new IllegalArgumentException();}// 直接创建HeapByteBuffer// HeapByteBuffer(int cap, int lim)return new HeapByteBuffer(capacity, capacity);}复制代码
然后是allocateDirect(int capacity),如下所示。
public static ByteBuffer allocateDirect(int capacity) {return new DirectByteBuffer(capacity);}DirectByteBuffer(int cap) {// MappedByteBuffer(int mark, int pos, int lim, int cap)super(-1, 0, cap, cap);boolean pa = VM.isDirectMemoryPageAligned();int ps = Bits.pageSize();long size = Math.max(1L, (long)cap + (pa ? ps : 0));Bits.reserveMemory(size, cap);long base = 0;try {// 分配堆外内存base = unsafe.allocateMemory(size);} catch (OutOfMemoryError x) {Bits.unreserveMemory(size, cap);throw x;}unsafe.setMemory(base, size, (byte) 0);// 计算堆外内存起始地址if (pa && (base % ps != 0)) {address = base + ps - (base & (ps - 1));} else {address = base;}// 通过虚引用的手段来监视DirectByteBuffer是否被垃圾回收// 从而可以及时的释放堆外内存空间cleaner = Cleaner.create(this, new Deallocator(base, size, cap));att = null;}复制代码
然后是wrap(byte[] array),如下所示。
public static ByteBuffer wrap(byte[] array) {return wrap(array, 0, array.length);}复制代码
其实wrap(byte[] array) 方法就是调用的wrap(byte[] array, int off, int length),下面直接看wrap(byte[] array, int off, int length) 方法的实现。
public static ByteBuffer wrap(byte[] array, int off, int length) {try {return new HeapByteBuffer(array, off, length);} catch (IllegalArgumentException x) {throw new IndexOutOfBoundsException();}}复制代码
这里先简单说明一下上述方法中的off和length这两个参数的含义。
- off就是表示字节数组封装到字节缓冲区后,position的位置,所以有position = off;
- length简单理解就是用于计算limit,即limit = position + length。其实length是理解为字节数组封装到字节缓冲区后,要使用的字节数组的长度。
下面给出一张wrap(byte[] array, int off, int length) 方法的作用示意图。

最后说明一点,无论是wrap(byte[] array) 还是wrap(byte[] array, int off, int length) 方法,均构造的是HeapByteBuffer。
- ByteBuffer的slice操作
在ByteBuffer中定义了一个抽象方法叫做slice(),用于在已有的ByteBuffer上得到一个新的ByteBuffer,两个ByteBuffer的position,limit,capacity和mark都是独立的,但是底层存储数据的内存区域是一样的,那么相应的,对其中任何一个ByteBuffer做更改,会影响到另外一个ByteBuffer。
下面先看一下HeapByteBuffer对slice() 方法的实现。
public ByteBuffer slice() {return new HeapByteBuffer(hb, -1, 0, this.remaining(), this.remaining(), this.position() + offset);}public final int remaining() {return limit - position;}protected HeapByteBuffer(byte[] buf, int mark, int pos, int lim, int cap, int off) {super(mark, pos, lim, cap, buf, off);}ByteBuffer(int mark, int pos, int lim, int cap,byte[] hb, int offset) {super(mark, pos, lim, cap);this.hb = hb;this.offset = offset;}复制代码
新的HeapByteBuffer的mark重置为了-1,position重置为了0,limit等于capacity等于老的HeapByteBuffer的未操作数据的长度(老的limit - posittion)。
此外,两个HeapByteBuffer存储数据的字节数组hb是同一个,且新的HeapByteBuffer的offset等于老的HeapByteBuffer的position,什么意思呢,先看下面这张图。

意思就是,在新的HeapByteBuffer中,操作position位置的元素,实际是在操作hb[position + offset] 位置的元素,那么这里也就解释了ByteBuffer中offset属性的作用,就是表示要操作字节数组时的索引偏移量。
有了上面对HeapByteBuffer的理解,那么现在再看DirectByteBuffer就显得很简单了,DirectByteBuffer对slice() 方法的实现如下所示。
public ByteBuffer slice() {int pos = this.position();int lim = this.limit();assert (pos <= lim);int rem = (pos <= lim ? lim - pos : 0);int off = (pos << 0);assert (off >= 0);return new DirectByteBuffer(this, -1, 0, rem, rem, off);}DirectByteBuffer(DirectBuffer db,int mark, int pos, int lim, int cap,int off) {super(mark, pos, lim, cap);address = db.address() + off;cleaner = null;att = db;}复制代码
DirectByteBuffer对slice() 方法的实现和HeapByteBuffer差不多,只不过在HeapByteBuffer中是对字节数组索引有偏移,而在DirectByteBuffer中是对堆外内存地址有偏移,同时偏移量都是老的ByteBuffer的position的值。
最后针对slice() 方法,有一点小说明,在DirectByteBuffer的att中有这么一段注释。
If this buffer is a view of another buffer then …
这里提到了view,翻译过来叫做视图,其实调用ByteBuffer的slice() 方法,可以想象成就是为原字节缓冲区创建了一个视图,这个视图和原字节缓冲区共享同一片内存区域,但是有新的一套mark,position,limit和capacity。
- ByteBuffer的asReadOnlyBuffer操作
ByteBuffer定义了一个抽象方法叫做asReadOnlyBuffer(),会在当前ByteBuffer基础上创建一个新的ByteBuffer,创建出来的ByteBuffer能看见老ByteBuffer的数据(共享同一块内存),但只能读不能写(只读的),同时两个ByteBuffer的position,limit,capacity和mark是独立的。
先看一下HeapByteBuffer对asReadOnlyBuffer() 方法的实现,如下所示。
public ByteBuffer asReadOnlyBuffer() {return new HeapByteBufferR(hb,this.markValue(),this.position(),this.limit(),this.capacity(),offset);}protected HeapByteBufferR(byte[] buf,int mark, int pos, int lim, int cap,int off) {super(buf, mark, pos, lim, cap, off);this.isReadOnly = true;}复制代码
也就是会new一个HeapByteBufferR出来,并且会指定其isReadOnly字段为true,表示只读。HeapByteBufferR继承于HeapByteBuffer,表示只读HeapByteBuffer,HeapByteBufferR重写了HeapByteBuffer的所有写相关方法,并且在这些写相关方法中抛出ReadOnlyBufferException异常,下面是部分写方法的示例。
public ByteBuffer put(int i, byte x) {throw new ReadOnlyBufferException();}public ByteBuffer put(byte x) {throw new ReadOnlyBufferException();}复制代码
再看一下DirectByteBuffer对asReadOnlyBuffer() 方法的实现,如下所示。
public ByteBuffer asReadOnlyBuffer() {return new DirectByteBufferR(this,this.markValue(),this.position(),this.limit(),this.capacity(),0);}DirectByteBufferR(DirectBuffer db,int mark, int pos, int lim, int cap,int off) {super(db, mark, pos, lim, cap, off);}复制代码
也是会new一个只读的DirectByteBufferR,DirectByteBufferR继承于DirectByteBuffer并重写了所有写相关方法,并且在这些写相关方法中抛出ReadOnlyBufferException异常。
- ByteBuffer的写操作
ByteBuffer中定义了大量写操作相关的抽象方法,如下图所示。

总体可以进行如下归类。

下面将对上述部分写方法结合源码进行说明。
Ⅰ. put(byte)
首先是最简单的put(byte) 方法,作用是往字节缓冲区的position位置写入一个字节,先看一下HeapByteBuffer对其的实现,如下所示。
public ByteBuffer put(byte x) {hb[ix(nextPutIndex())] = x;return this;}protected int ix(int i) {return i + offset;}// Buffer#nextPutIndex()final int nextPutIndex() {if (position >= limit) {throw new BufferOverflowException();}return position++;}复制代码
再看一下DirectByteBuffer对put(byte) 方法的实现,如下所示。
public ByteBuffer put(byte x) {unsafe.putByte(ix(nextPutIndex()), ((x)));return this;}private long ix(int i) {return address + ((long)i << 0);}// Buffer#nextPutIndex()final int nextPutIndex() {if (position >= limit) {throw new BufferOverflowException();}return position++;}复制代码
都是会调用到Buffer#nextPutIndex() 方法来拿到当前的position,区别是HeapByteBuffer是将字节写入到堆上的数组,而DirectByteBuffer是写在直接内存中。
Ⅱ. put(int, byte)
put(int, byte) 方法能够在指定位置写入一个字节,注意该方法写入字节不会改变position。
HeapByteBuffer对其实现如下所示。
public ByteBuffer put(int i, byte x) {hb[ix(checkIndex(i))] = x;return this;}protected int ix(int i) {return i + offset;}// Buffer#checkIndex(int)final int checkIndex(int i) {if ((i < 0) || (i >= limit)) {throw new IndexOutOfBoundsException();}return i;}复制代码
DirectByteBuffer对put(int, byte) 方法的实现如下所示。
public ByteBuffer put(int i, byte x) {unsafe.putByte(ix(checkIndex(i)), ((x)));return this;}private long ix(int i) {return address + ((long) i << 0);}// Buffer#checkIndex(int)final int checkIndex(int i) {if ((i < 0) || (i >= limit)) {throw new IndexOutOfBoundsException();}return i;}复制代码
Ⅲ. put(byte[], int, int)
put(byte[], int, int) 方法是批量的将字节数组中指定的字节写到ByteBuffer。
put(byte[], int, int) 方法并不是抽象方法,在ByteBuffer中定义了其实现,但同时HeapByteBuffer和DirectByteBuffer也都对其进行了重写。下面分别看一下其实现。
ByteBuffer#put(byte[], int, int) 实现如下所示。
public ByteBuffer put(byte[] src, int offset, int length) {checkBounds(offset, length, src.length);if (length > remaining()) {throw new BufferOverflowException();}int end = offset + length;// 从src的offset索引开始依次将后续的length个字节写到ByteBuffer中for (int i = offset; i < end; i++) {this.put(src[i]);}return this;}复制代码
ByteBuffer对put(byte[], int, int) 方法的实现是循环遍历字节数组中每一个需要写入的字节,然后调用put(byte) 方法完成写入,其中offset表示从字节数组的哪一个字节开始写,length表示从offset开始往后的多少个字节需要写入。
由于ByteBuffer对put(byte[], int, int) 方法的实现的写入效率不高,所以HeapByteBuffer和DirectByteBuffer都有自己的实现,先看一下HeapByteBuffer对put(byte[], int, int) 方法的实现,如下所示。
public ByteBuffer put(byte[] src, int offset, int length) {checkBounds(offset, length, src.length);if (length > remaining()) {throw new BufferOverflowException();}// 使用了native的拷贝方法来实现更高效的写入System.arraycopy(src, offset, hb, ix(position()), length);position(position() + length);return this;}复制代码
由于HeapByteBuffer存储字节是存储到字节数组中,所以直接使用native的arraycopy() 方法来完成字节数组的拷贝是更为高效的手段。
再看一下DirectByteBuffer对put(byte[], int, int) 方法的实现,如下所示。
public ByteBuffer put(byte[] src, int offset, int length) {// 写入字节数大于6时使用native方法来批量写入才更高效if (((long) length << 0) > Bits.JNI_COPY_FROM_ARRAY_THRESHOLD) {checkBounds(offset, length, src.length);int pos = position();int lim = limit();assert (pos <= lim);int rem = (pos <= lim ? lim - pos : 0);if (length > rem) {throw new BufferOverflowException();}// 这里最终会调用到native方法Unsafe#copyMemory来批量写入Bits.copyFromArray(src, arrayBaseOffset,(long) offset << 0,ix(pos),(long) length << 0);// 更新positionposition(pos + length);} else {// 写入字节数小于等于6则遍历每个字节并依次写入会更高效super.put(src, offset, length);}return this;}复制代码
在DirectByteBuffer的实现中,并没有直接调用到native方法来批量操作直接内存,而是先做了判断:如果本次批量写入的字节数大于JNI_COPY_FROM_ARRAY_THRESHOLD(默认是6),才调用native方法Unsafe#copyMemory来完成字节在直接内存中的批量写入,否则就还是一个字节一个字节的写入。DirectByteBuffer的做法主要还是考虑到native方法的调用的一个开销,比如就写入一个字节,那肯定是没有必要调用native方法的。
Ⅳ. put(byte[])
put(byte[]) 方法的作用是将一个字节数组的内容全部写入到ByteBuffer,该方法是一个final方法,所以这里看一下ByteBuffer中该方法的实现,如下所示。
public final ByteBuffer put(byte[] src) {return put(src, 0, src.length);}复制代码
其实就是调用到put(byte[], int, int) 方法来完成批量写入。
Ⅴ. put(ByteBuffer)
put(ByteBuffer) 方法用于将一个ByteBuffer中所有未操作的字节批量写入当前ByteBuffer。ByteBuffer,HeapByteBuffer和DirectByteBuffer都有相应的实现,下面分别看一下。
ByteBuffer#put(ByteBuffer) 思路还是一个字节一个字节的写入,实现如下。
public ByteBuffer put(ByteBuffer src) {if (src == this) {throw new IllegalArgumentException();}if (isReadOnly()) {throw new ReadOnlyBufferException();}// 计算limit - positionint n = src.remaining();if (n > remaining()) {throw new BufferOverflowException();}// 一个字节一个字节的写入for (int i = 0; i < n; i++) {put(src.get());}return this;}复制代码
HeapByteBuffer#put(ByteBuffer) 思路是先判断源ByteBuffer的类型,如果源ByteBuffer是HeapByteBuffer,则调用native方法System#arraycopy完成批量写入,如果源ByteBuffer是在直接内存中分配的,则再判断一下要写入的字节是否大于6,如果大于6就调用native方法Unsafe#copyMemory完成批量写入,否则就一个字节一个字节的写入。实现如下。
public ByteBuffer put(ByteBuffer src) {if (src instanceof HeapByteBuffer) {if (src == this) {throw new IllegalArgumentException();}HeapByteBuffer sb = (HeapByteBuffer) src;// 计算源ByteBuffer剩余的字节数int n = sb.remaining();if (n > remaining()) {throw new BufferOverflowException();}// 调用native方法批量写入System.arraycopy(sb.hb, sb.ix(sb.position()),hb, ix(position()), n);// 更新源ByteBuffer的positionsb.position(sb.position() + n);// 更新当前ByteBuffer的positionposition(position() + n);} else if (src.isDirect()) {// 计算源ByteBuffer剩余的字节数int n = src.remaining();if (n > remaining()) {throw new BufferOverflowException();}// 批量写入字节到当前ByteBuffer的hb字节数组中src.get(hb, ix(position()), n);// 更新当前ByteBuffer的positionposition(position() + n);} else {super.put(src);}return this;}// DirectByteBuffer#get(byte[], int, int)public ByteBuffer get(byte[] dst, int offset, int length) {if (((long) length << 0) > Bits.JNI_COPY_TO_ARRAY_THRESHOLD) {checkBounds(offset, length, dst.length);int pos = position();int lim = limit();assert (pos <= lim);int rem = (pos <= lim ? lim - pos : 0);if (length > rem) {throw new BufferUnderflowException();}Bits.copyToArray(ix(pos), dst, arrayBaseOffset,(long) offset << 0,(long) length << 0);// 更新源ByteBuffer的positionposition(pos + length);} else {super.get(dst, offset, length);}return this;}复制代码
DirectByteBuffer#put(ByteBuffer) 的思路也是先判断源ByteBuffer的类型,如果源ByteBuffer是DirectByteBuffer,则直接使用native方法Unsafe#copyMemory完成批量写入,如果源ByteBuffer是在堆上分配的,则按照DirectByteBuffer的put(byte[], int, int) 方法的逻辑完成批量写入。实现如下所示。
public ByteBuffer put(ByteBuffer src) {if (src instanceof DirectByteBuffer) {if (src == this) {throw new IllegalArgumentException();}DirectByteBuffer sb = (DirectByteBuffer) src;int spos = sb.position();int slim = sb.limit();assert (spos <= slim);// 计算源ByteBuffer剩余的字节数int srem = (spos <= slim ? slim - spos : 0);int pos = position();int lim = limit();assert (pos <= lim);int rem = (pos <= lim ? lim - pos : 0);if (srem > rem) {throw new BufferOverflowException();}// 调用native方法完成批量写入unsafe.copyMemory(sb.ix(spos), ix(pos), (long) srem << 0);// 更新源ByteBuffer的positionsb.position(spos + srem);// 更新当前ByteBuffer的positionposition(pos + srem);} else if (src.hb != null) {int spos = src.position();int slim = src.limit();assert (spos <= slim);// 计算源ByteBuffer剩余的字节数int srem = (spos <= slim ? slim - spos : 0);// 调用DirectByteBuffer#put(byte[], int, int)完成批量写入put(src.hb, src.offset + spos, srem);// 更新源ByteBuffer的positionsrc.position(spos + srem);} else {super.put(src);}return this;}// DirectByteBuffer#put(byte[], int, int)public ByteBuffer put(byte[] src, int offset, int length) {if (((long) length << 0) > Bits.JNI_COPY_FROM_ARRAY_THRESHOLD) {checkBounds(offset, length, src.length);int pos = position();int lim = limit();assert (pos <= lim);int rem = (pos <= lim ? lim - pos : 0);if (length > rem) {throw new BufferOverflowException();}Bits.copyFromArray(src, arrayBaseOffset,(long) offset << 0,ix(pos),(long) length << 0);// 更新当前ByteBuffer的positionposition(pos + length);} else {super.put(src, offset, length);}return this;}复制代码
最后有一点需要说明,调用put(ByteBuffer) 方法完成批量字节写入后,源ByteBuffer和当前ByteBuffer的position都会被更新。
Ⅵ. 字节序
上述的几种put() 方法都是向ByteBuffer写入字节,但其实也是可以直接将char,int等基础数据类型写入ByteBuffer,但在分析这些写入基础数据类型到ByteBuffer的put() 方法以前,有必要对字节序的相关概念进行演示和说明。
已知在Java中一个int是四个字节,而一个字节是8位,那么就以数字23333为例,示意如下。

那么上述的一个int数据,存储在内存中时,如果高位字节存储在内存的低地址,低位字节存储在内存的高地址,这种就称为大端字节序(Big Endian),示意图如下所示。

反之如果低位字节存储在内存的低地址,高位字节存储在内存的高地址,这种就称为小端字节序(Little Endian),示意图如下所示。

上述其实是主机字节序,表示计算机内存中字节的存储顺序。在Java中,数据的存储默认是按照大端字节序来存储的。
然后还有一种叫做网络字节序,表示网络传输中字节的传输顺序,分类如下。
- 大端字节序(Big Endian)。从二进制数据的高位开始传输;
- 小端字节序(Little Endian)。从二进制数据的低位开始传输。
在网络传输中,默认按照大端字节序来传输。
Ⅶ. putInt(int)
putInt(int) 方法是ByteBuffer定义的用于直接写入一个int的抽象方法,先看HeapByteBuffer的实现,如下所示。
public ByteBuffer putInt(int x) {// 通过nextPutIndex(4)方法拿到当前position,并让position加4// 然后调用Bits#putInt完成写入,其中bigEndian默认是trueBits.putInt(this, ix(nextPutIndex(4)), x, bigEndian);return this;}// Bits#putIntstatic void putInt(ByteBuffer bb, int bi, int x, boolean bigEndian) {if (bigEndian) {putIntB(bb, bi, x);} else {putIntL(bb, bi, x);}}// Bits#putIntBstatic void putIntB(ByteBuffer bb, int bi, int x) {// 通过Bits#int3方法拿到x的第3字节(最高位字节)// 然后写入到hb字节数组的索引为bi的位置bb._put(bi , int3(x));// 通过Bits#int2方法拿到x的第2字节(次高位字节)// 然后写入到hb字节数组的索引为bi+1的位置bb._put(bi + 1, int2(x));// 通过Bits#int1方法拿到x的第1字节(次低位字节)// 然后写入到hb字节数组的索引为bi+2的位置bb._put(bi + 2, int1(x));// 通过Bits#int0方法拿到x的第0字节(最低位字节)// 然后写入到hb字节数组的索引为bi+3的位置bb._put(bi + 3, int0(x));}// Bits#int3private static byte int3(int x) {return (byte) (x >> 24);}// HeapByteBuffer#_putvoid _put(int i, byte b) {hb[i] = b;}复制代码
HeapByteBuffer实现的putInt(int) 方法中,会依次将int的高位到低位写入到hb字节数组的低索引到高索引,而在堆中,内存地址是由低到高的,也就是随着数组索引的增加,内存地址也会逐渐增高,所以上述的就是按照大端字节序的方式来直接写入一个int。
再看一下DirectByteBuffer对putInt(int) 方法的实现,如下所示。
public ByteBuffer putInt(int x) {// 通过nextPutIndex(4)方法拿到当前position,并让position加4// 通过ix()方法拿到实际要写入的内存地址putInt(ix(nextPutIndex((1 << 2))), x);return this;}// DirectByteBuffer#putInt(long, int)private ByteBuffer putInt(long a, int x) {if (unaligned) {int y = (x);unsafe.putInt(a, (nativeByteOrder ? y : Bits.swap(y)));} else {// 调用Bits#putInt完成写入,其中bigEndian默认是trueBits.putInt(a, x, bigEndian);}return this;}// Bits#putIntstatic void putInt(long a, int x, boolean bigEndian) {if (bigEndian) {putIntB(a, x);} else {putIntL(a, x);}}// Bits#putIntBstatic void putIntB(long a, int x) {// 通过Bits#int3方法拿到x的第3字节(最高位字节)// 然后写入到直接内存地址为a的位置_put(a , int3(x));// 通过Bits#int2方法拿到x的第2字节(次高位字节)// 然后写入到直接内存地址为a+1的位置_put(a + 1, int2(x));// 通过Bits#int1方法拿到x的第1字节(次低位字节)// 然后写入到直接内存地址为a+2的位置_put(a + 2, int1(x));// 通过Bits#int0方法拿到x的第0字节(最低位字节)// 然后写入到直接内存地址为a+3的位置_put(a + 3, int0(x));}// Bits#int3private static byte int3(int x) {return (byte) (x >> 24);}// Bits#_putprivate static void _put(long a, byte b) {unsafe.putByte(a, b);}复制代码
在DirectByteBuffer的实现中,会依次将int的高位到低位写入到直接内存的低地址到高地址,整体也是一个大端字节序的写入方式。
Ⅷ. putInt(int, int)
putInt(int, int) 方法可以在指定位置写入int,同时也不会更改position。putInt(int, int) 方法实现原理和putInt(int) 一样,故这里不再赘述。
其它的写入非字节的方法,本质和写入int一致,故也不再赘述。
- ByteBuffer的读操作
ByteBuffer中定义了大量读操作相关的抽象方法,如下图所示。

总体可以进行如下归类。

下面将对上述部分读方法结合源码进行说明。
Ⅰ. get()
get() 方法用于读取一个字节,HeapByteBuffer的实现如下所示。
public byte get() {return hb[ix(nextGetIndex())];}复制代码
上述方法是读取字节数组中position索引位置的字节,然后position加1。再看一下DirectByteBuffer对get() 方法的实现,如下所示。
public byte get() {return ((unsafe.getByte(ix(nextGetIndex()))));}复制代码
上述方法是基于native方法拿到address + position位置的字节然后position加1。
Ⅱ. get(int)
get(int) 方法用于读取指定位置的字节,HeapByteBuffer的实现如下所示。
public byte get(int i) {return hb[ix(checkIndex(i))];}复制代码
上述方法会读取字节数组中指定索引位置的字节,注意position不会改变。再看一下DirectByteBuffer对get(int) 方法的实现,如下所示。
public byte get(int i) {return ((unsafe.getByte(ix(checkIndex(i)))));}复制代码
上述方法是基于native方法拿到指定位置的字节,同样,position不会改变。
Ⅲ. get(byte[], int, int)
get(byte[], int, int) 方法用于将当前ByteBuffer从position位置开始往后的若干字节写入到目标字节数组的指定位置。ByteBuffer,HeapByteBuffer和DirectByteBuffer都有相应的实现,下面分别看一下。
ByteBuffer对get(byte[], int, int) 方法的实现中是一个字节一个字节的读取并写入,如下所示。
public ByteBuffer get(byte[] dst, int offset, int length) {checkBounds(offset, length, dst.length);if (length > remaining()) {throw new BufferUnderflowException();}int end = offset + length;// 写入目标数组的开始位置是offset// 共写入length个字节for (int i = offset; i < end; i++) {dst[i] = get();}return this;}复制代码
HeapByteBuffer对get(byte[], int, int) 方法的实现中,是调用System#arraycopy本地方法来进行批量拷贝写入,效率比一个字节一个字节的读取并写入更高,且最后会更新当前HeapByteBuffer的position。
public ByteBuffer get(byte[] dst, int offset, int length) {checkBounds(offset, length, dst.length);if (length > remaining()) {throw new BufferUnderflowException();}// 调用native方法来批量写入字节到dst字节数组System.arraycopy(hb, ix(position()), dst, offset, length);// 更新当前HeapByteBuffer的positionposition(position() + length);return this;}复制代码
DirectByteBuffer对get(byte[], int, int) 方法的实现中,会先判断需要读取并写入到目标字节数组中的字节数是否大于6,大于6时会调用native方法来批量写入,否则就一个字节一个字节的读取并写入,最终还会更新当前DirectByteBuffer的position。
public ByteBuffer get(byte[] dst, int offset, int length) {if (((long) length << 0) > Bits.JNI_COPY_TO_ARRAY_THRESHOLD) {// 批量写入的字节数大于6个checkBounds(offset, length, dst.length);int pos = position();int lim = limit();assert (pos <= lim);int rem = (pos <= lim ? lim - pos : 0);if (length > rem) {throw new BufferUnderflowException();}// 最终调用到Unsafe#copyMemory方法完成批量拷贝写入Bits.copyToArray(ix(pos), dst, arrayBaseOffset,(long) offset << 0,(long) length << 0);// 更新当前DirectByteBuffer的positionposition(pos + length);} else {// 批量写入的字节数小于等于6个// 则一个字节一个字节的读取并写入super.get(dst, offset, length);}return this;}复制代码
Ⅳ. get(byte[])
get(byte[]) 方法会从当前ByteBuffer的position位置开始,读取目标字节数组长度个字节,然后依次写入到目标字节数组。get(byte[]) 方法由ByteBuffer实现,如下所示。
public ByteBuffer get(byte[] dst) {return get(dst, 0, dst.length);}复制代码
那么本质还是依赖get(byte[], int, int) 方法,只不过将offset指定为了0(表示从dst字节数组的索引为0的位置开始写入),将length指定为了dst.length(表示要写满dst字节数组)。
Ⅴ. getInt()
getInt() 方法表示从ByteBuffer中读取一个int值,先看一下HeapByteBuffer的实现,如下所示。
public int getInt() {// 通过nextGetIndex(4)拿到当前position,然后position加4// 默认bigEndian为true,表示以大端字节序的方式读取intreturn Bits.getInt(this, ix(nextGetIndex(4)), bigEndian);}// Bits#getIntstatic int getInt(ByteBuffer bb, int bi, boolean bigEndian) {return bigEndian ? getIntB(bb, bi) : getIntL(bb, bi) ;}// Bits#getIntBstatic int getIntB(ByteBuffer bb, int bi) {// 依次拿到低索引到高索引的字节// 这些字节依次对应int值的高位到低位// 最终调用makeInt()方法拼接成int值return makeInt(bb._get(bi),bb._get(bi + 1),bb._get(bi + 2),bb._get(bi + 3));}// Bits#makeIntstatic private int makeInt(byte b3, byte b2, byte b1, byte b0) {return (((b3) << 24) |((b2 & 0xff) << 16) |((b1 & 0xff) << 8) |((b0 & 0xff)));}// HeapByteBuffer#_getbyte _get(int i) {return hb[i];}复制代码
上述方法的实现中,首先获取到当前HeapByteBuffer的position,然后从position位置开始依次读取四个字节,因为默认情况下是大端字节序(也就是写和读都是按照大端字节序的方式),所以读取到的字节应该依次对应int值的高位到低位,所以最终会在Bits#makeInt方法中将四个字节通过错位或的方式得到int值。
再看一下DirectByteBuffer对getInt() 方法的实现,如下所示。
public int getInt() {// 通过nextGetIndex(4)拿到当前position,然后position加4// 通过ix()方法拿到操作的起始地址是address + positionreturn getInt(ix(nextGetIndex((1 << 2))));}// DirectByteBuffer#getInt(long)private int getInt(long a) {if (unaligned) {int x = unsafe.getInt(a);return (nativeByteOrder ? x : Bits.swap(x));}// 默认bigEndian为true,表示默认大端字节序return Bits.getInt(a, bigEndian);}// Bits#getIntstatic int getInt(long a, boolean bigEndian) {return bigEndian ? getIntB(a) : getIntL(a) ;}// Bits#getIntBstatic int getIntB(long a) {// 从低地址拿到int值的高位// 从高地址拿到int值的低位// 然后拼接得到最终的int值return makeInt(_get(a),_get(a + 1),_get(a + 2),_get(a + 3));}// Bits#_getprivate static byte _get(long a) {return unsafe.getByte(a);}// Bits#makeIntstatic private int makeInt(byte b3, byte b2, byte b1, byte b0) {return (((b3) << 24) |((b2 & 0xff) << 16) |((b1 & 0xff) << 8) |((b0 & 0xff)));}复制代码
DirectByteBuffer对getInt() 方法的整体实现思路和HeapByteBuffer是一致的,在默认大端字节序的情况下,从低地址拿到int值的高位字节,从高地址拿到int值的低位字节,最后通过错位或的方式得到最终的int值。请注意,操作完成后,position都会加4,这是因为一个int占四个字节,也就是相当于读取了4个字节。
Ⅵ. getInt(int)
getInt(int) 方法能够从指定位置读取一个int值,实现思路和getInt() 方法完全一致,故这里不再赘述,但需要注意的是,getInt(int) 方法读取一个int值后,不会改变position。
其它的非字节的读取,本质和int值的读取一样,故也不再赘述。
- ByteBuffer的使用示例
在Log4j2日志框架中,最终在将日志进行输出时,对日志内容的处理就有使用到ByteBuffer,下面一起来简单的看一下。(无需关注Log4j2的实现细节)
在将日志内容进行标准输出时,最终是通过OutputStreamManager完成将日志内容输出,它里面有一个字段就是HeapByteBuffer,用于存储日志内容的字节数据。下面先看一下org.apache.logging.log4j.core.layout.TextEncoderHelper#writeEncodedText方法,这里面会有OutputStreamManager的ByteBuffer如何被写入的相关逻辑。
private static void writeEncodedText(final CharsetEncoder charsetEncoder, final CharBuffer charBuf,final ByteBuffer byteBuf, final ByteBufferDestination destination, CoderResult result) {......if (byteBuf != destination.getByteBuffer()) {// 这里的byteBuf存储了处理后的日志内容// 调用flip()方法来进入读模式byteBuf.flip();// 这里的destination就是OutputStreamManager// 这里会将byteBuf的内容写到OutputStreamManager的ByteBuffer中destination.writeBytes(byteBuf);// 切换为写模式,也就是position置0,重置limit等于capacity等byteBuf.clear();}}// OutputStreamManager#writeBytespublic void writeBytes(final ByteBuffer data) {if (data.remaining() == 0) {return;}synchronized (this) {ByteBufferDestinationHelper.writeToUnsynchronized(data, this);}}// ByteBufferDestinationHelper#writeToUnsynchronizedpublic static void writeToUnsynchronized(final ByteBuffer source, final ByteBufferDestination destination) {// 拿到OutputStreamManager中的HeapByteBuffer// 这里称OutputStreamManager中的HeapByteBuffer为目标ByteBufferByteBuffer destBuff = destination.getByteBuffer();// 如果源ByteBuffer剩余可读字节多于目标ByteBuffer剩余可写字节// 则循环的写满目标ByteBuffer再读取完目标ByteBuffer// 最终就是需要将源ByteBuffer的字节全部由目标ByteBuffer消费掉while (source.remaining() > destBuff.remaining()) {final int originalLimit = source.limit();// 先将源ByteBuffer的limit设置为当前position + 目标ByetBuffer剩余可写字节数source.limit(Math.min(source.limit(), source.position() + destBuff.remaining()));// 将源ByteBuffer当前position到limit的字节写到目标ByteBuffer中destBuff.put(source);// 恢复源ByteBuffer的limitsource.limit(originalLimit);// 目标ByteBuffer先将已有的字节全部标准输出// 然后返回一个写模式的目标ByteBufferdestBuff = destination.drain(destBuff);}// 到这里说明源ByteBuffer剩余可读字节小于等于目标ByteBuffer剩余可写字节// 则将源ByteBuffer剩余可读字节全部写到目标ByteBuffer中// 后续会在其它地方将这部分内容全部标准输出destBuff.put(source);}// OutputStreamManager#drainpublic ByteBuffer drain(final ByteBuffer buf) {flushBuffer(buf);return buf;}// OutputStreamManager#flushBufferprotected synchronized void flushBuffer(final ByteBuffer buf) {// 目标ByteBuffer切换为读模式((Buffer) buf).flip();try {if (buf.remaining() > 0) {// 拿到HeapByteBuffer中的字节数组// 最终调用到PrintStream来标准输出字节数组中的字节内容writeToDestination(buf.array(), buf.arrayOffset() + buf.position(), buf.remaining());}} finally {// 目标ByteBuffer切换回写模式buf.clear();}}复制代码
相信如果阅读完本文,那么上述Log4j2中对于ByteBuffer的使用,肯定都是能看明白的,虽然Log4j2中有大量的基于ByteBuffer的使用,但是最终的标准输出还是基于Java的传统IO来输出的,那么为什么中间还要用ByteBuffer来多处理一下呢,其实也就是因为ByteBuffer在读写字节时会考虑性能问题,会使用到性能更高的native方法来批量的操作字节数据,因此以快著称的Log4j2选择了NIO中的ByteBuffer。
- ByteBuffer的缺点
如果要讨论ByteBuffer的缺点,其实可以结合第7小节的使用示例来一并讨论。
首先就是读写模式的切换。在第7小节示例中,会发现存在多处调用flip() 方法来切换到读模式,调用clear() 方法来切换到写模式,这种模式的切换,既麻烦,还容易出错。
然后就是无法扩容。在第7小节示例中,有一个细节就是因为ByteBuffer容量太小了,无法一次写完所有字节数据,所以就只能循环的写满读取然后再写满这样子来操作,如果能扩容就不用这么麻烦了。
最后就是线程不安全。ByteBuffer自身并没有提供对线程安全的保护,要实现线程安全,需要使用者自己通过其它的并发语义来实现。
总结
本文对ByteBuffer的分析可以参照下图。

为啥NIO中偏分析ByteBuffer呢,因为Netty中的缓存是ByteBuf,其对ByteBuffer做了改良,在下一篇文章中,将对Netty中的缓存ByteBuf进行详细分析。

























")



")




还没有评论,来说两句吧...