LeetCode146: LRU缓存机制(字节面试手撕题)
文章目录
- 前言
- 题干
- 举个栗子
- 具体学习
- 实现
- LinkedList+HashMap
- 双向链表+HashMap
- 节点的定义:
- 双向链表API
- 具体执行过程
- 后记
前言
之前在校学习计算机操作系统时候学习过,当时就明白了个什么意思,但是具体的实现老师并没有给我们要求,当时也就没有具体的深入学习,这段时间发现对于基础的部分还是蛮重要的。加上发现对于最近的面试来说这个还蛮重要的,所以这里拿出来自己进行记录一下,希望能帮助到在看的小伙伴。
题干
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制。它应该支持以下操作:
获取数据 get 和 写入数据 put 。
获取数据 get(key) - 如果密钥 (key) 存在于缓存中,则获取密钥的值(总是正数),否则返回 -1。
写入数据 put(key, value) - 如果密钥已经存在,则变更其数据值;如果密钥不存在,则插入该组「密钥/数据值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。
举个栗子
LRUCache cache = new LRUCache( 2 /* 缓存容量 */ );cache.put(1, 1);cache.put(2, 2);cache.get(1); // 返回 1cache.put(3, 3); // 该操作会使得密钥 2 作废// 为什么这里不是1作废呢,是因为对于1来说尽管先于2进行插入,但是对于1有新的get操作,这个操作就算是对进行了一个操作,所以这个时候2是最远没有进行操作的数。cache.get(2); // 返回 -1 (未找到)cache.put(4, 4); // 该操作会使得密钥 1 作废cache.get(1); // 返回 -1 (未找到)cache.get(3); // 返回 3cache.get(4); // 返回 4
具体学习
这里我们举一个更加贴切实际的栗子:
- 首先我们依次在手机上打开CSDN,墨墨,和番茄·TODO,显示如下图所示。
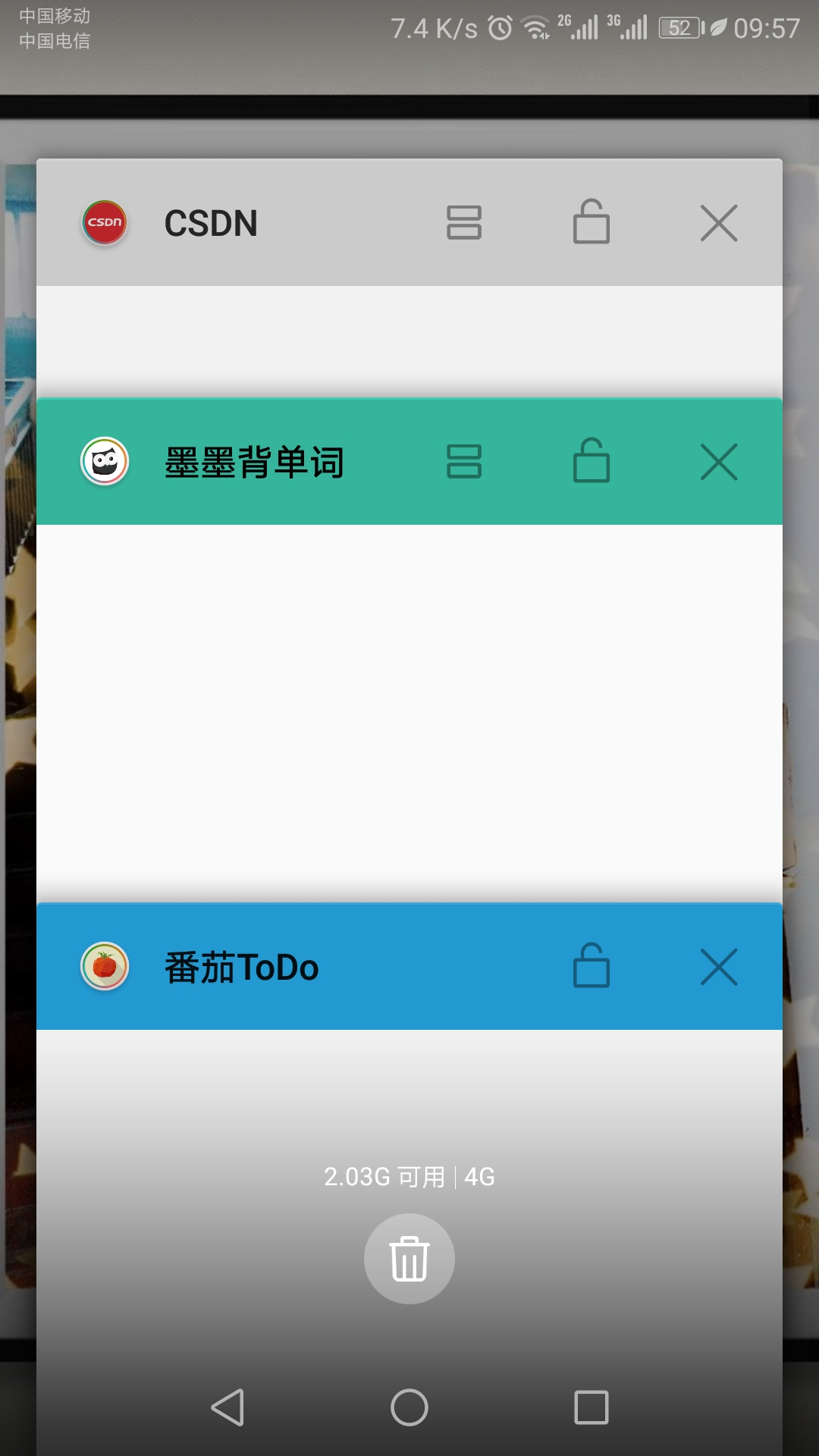
- 然后我们想要打开墨墨背单词,这个时候墨墨就会被调整到最上面。
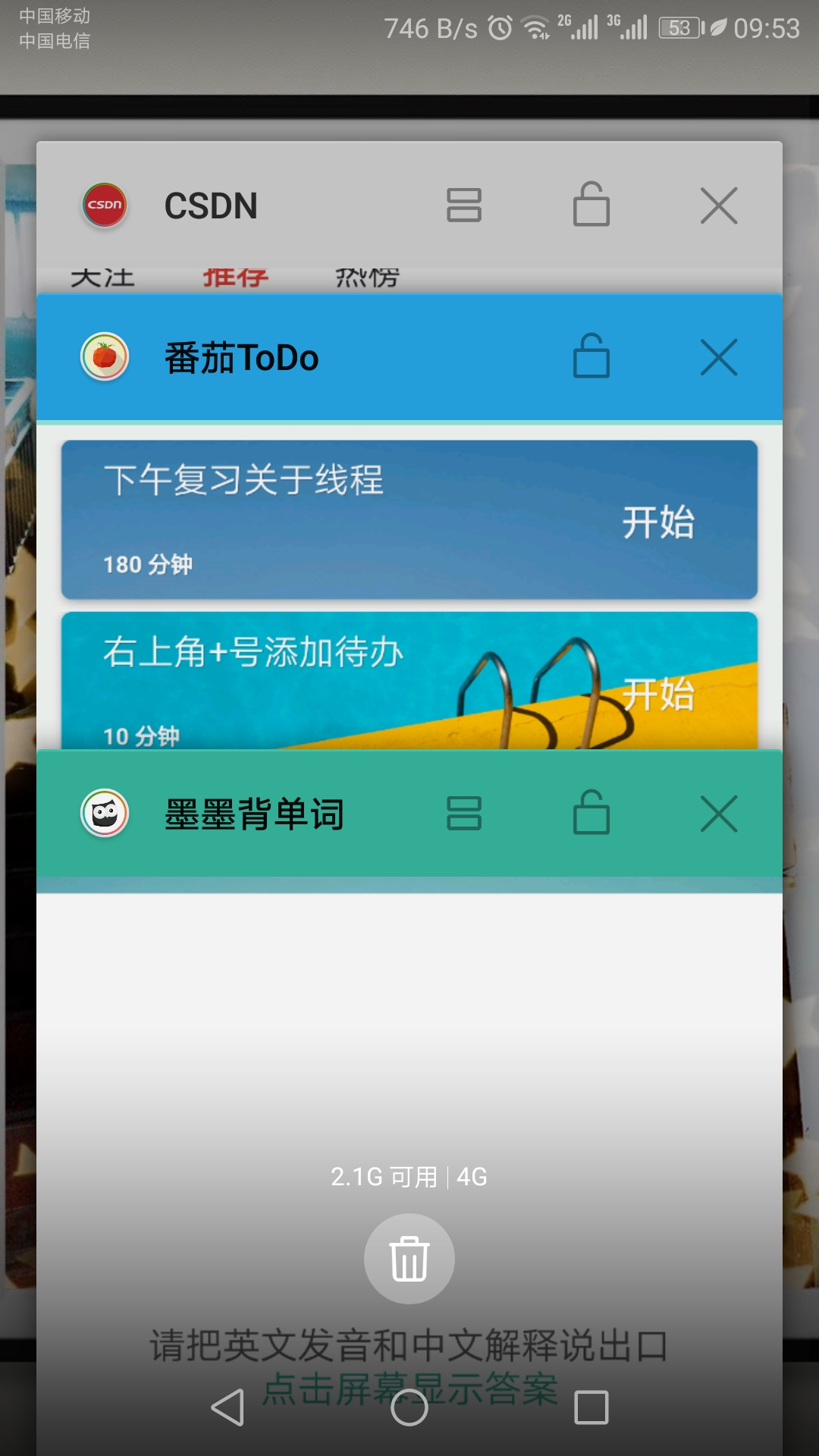
- 若是对于我们手机而言,最多只能支持同时三个软件在后台和前台运行,我们再度打开一个浏览器,就会将最开始的CSDN给挤出后台的运行,如下图所示:

以上不知道大家能不能更加深刻的理解对于这个算法的原理,下面我借鉴了大佬们的回答,来具体说一下这个代码的实现。
实现
- 首先我们需要思考的是对于这个题目而言需要使用到什么技术栈,就是我们利用之前所学习过的一些基础知识进行设计我们需要的数据结构,首先是需要接受一个capacity作为一个参数传入进来作为一个最大的容量,然后就是get与put操作。
- 我们一方面想要实现既然是让我们设计一个数据结构,就一定要有她的有点和特色,对于存储进来的元素是键值对方式,就要考虑到使用HashMap是必然的,然后就是对于记录哪些有了变化,对于任何操作有了变化,我们就需要像手机一样提到最前面,就肯定要做的是实现有序吧,弄一个基础的数据结构,对我们加入进来的进行一个排序处理,有任何的操作(put和get)都会影响到排序,于是就想到了对于有序的就是数组,链表,队列,栈等。这里我们使用到队列和链表。
LinkedList+HashMap
思路:
- 对于LinkedList来说,我们维持大小为capacity大小的队列。依次放入到里面,这个时候最久未被使用到的就是在队头中,最近使用到的是在队尾里面。
- 进行put时候,首先利用到了HashMap的特性,进行键值对的查询,若是键与值都不存在,且小于阈值,进行插入,若是键相等,但是值不等,进行更新处理,若是插入过程中,键值都不存在,且队列元素已满,这个时候就移除掉队头的元素,进行新元素的插入。
- 进行get时候,同样是进行判断存在与否
- 存在时候进行取出(从map集合中),并且将在对应的队列中的值移动到队尾中。
- 若是不存在时候,就直接返回flase即可。
实现:
代码实现起来不是很复杂就不进行一一的讲解。
import java.util.HashMap;import java.util.LinkedList;public class LRU {int capacity;LinkedList<Integer> linkedList=new LinkedList<>();HashMap<Integer,Integer> map=new HashMap<>();public LRU(int capacity){this.capacity=capacity;}private int get(int getKey){if(!map.containsKey(getKey))return -1;linkedList.remove(new Integer(getKey)); linkedList.offer(getKey);return map.get(getKey);}private void put(int key,int value){// 包含时候将其移除,因为就算是一个重复的插入过程,键相同,值不同时候,也是一个更改过程,移除以后,再度进行一个插入。if(map.containsKey(key)){linkedList.remove(new Integer(key));}else {// 既然不包含就要插入,但是插入时候需要做到的就是 判断长度的大小。if(linkedList.size()==capacity){map.remove(linkedList.poll());}}linkedList.offer(key);map.put(key,value);}}
双向链表+HashMap
对于链表的解决方法我们可以使用到双向链表+HashMap实现,具体的分析如下(先来看一张网上记不得很久前记录时候留下的图片):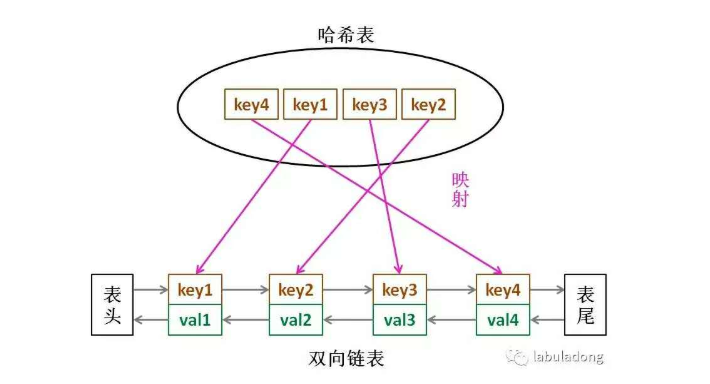
节点的定义:
class Node{int key;int value;Node next,pre;Node(int key,int value){this.key=key;this.value=value;}}
因为是双向链表,所以就前驱指针和后继。
双向链表API
class DoubleList {private Node head,tail;private int size;// 实现双向链表,无参构造函数DoubleList(){head=new Node(0,0);tail=new Node(0,0);head.next=tail;tail.pre=head;size=0;}// 进行节点的添加,对于每一次若是空间大小还够,并且key值不相等时候,进行添加操作。public void add(Node p){p.next=head.next;p.pre=head;head.next.pre=p;head.next=p;size++;}// 在进入到这个函数时候,该节点一定是存在的public void remove(Node p){p.pre.next=p.next;p.next.pre=p.pre;size--;}// 意味着,新的节点的到来,我们这里删除的是最不常用的节点。删除链表的最后一个节点 并返回该节点public Node removeLast(){if(tail.next==head)return null;Node q=tail.pre;remove(q);return q;}// 返回当前链表的长度值。public int size(){return size;}}
具体执行过程
在执行开始前,还是先进行分析处理
- 对于get操作: 有以下的两种情况。
- 若是在map中不存在,表示链表中也不存在,我们就要进行返回-1.
- 若是存在,我们要取出key所对应的value,然后这个时候,就是相当于对其进行了操作,就需要再度将其放入到链表中。并返回我们取到的value值。
对于put操作: 也分为以下的情况。
- 对于判断key值时候发现原来这个key值对应的有value,就对之前的链表中删除掉,然后再度加入到链表的后面。对于map也进行put操作即可。
- 对于当前key值不存在,表示是新的值,这个时候就是要有以下的情况。
- 对于当前的链表值已经满员,就是说,就要执行LRU,删除最后面的那个节点,然后新节点的加入。
- 对于没有满员时候,就是进行正常的操作,map加入其中,链表也是加入到头部。
public class LRU{
private HashMapprivate DoubleList doubleList;private int capacity;public LRU(int capacity){this.capacity=capacity;map=new HashMap<>();doubleList=new DoubleList();}public int get(int key){// 表示不存在该key,返回-1;if(!map.containsKey(key)){return -1;}//既然存在了,我们需要获取到对应的值,然后加入到尾部,同时返回我们要的值
int value=map.get(key).value;
put(key,value);return value;}public void put(int key,int value){Node x=new Node(key,value);// 已经存在对应的key值时候,map对应更新,链表先删除,然后加入头部。if(map.containsKey(key)){doubleList.remove(x);doubleList.add(x);map.put(key,x);}// 不存在key值时候, 判断空间大小能够再度进行插入操作。else{if(capacity==doubleList.size()){Node q=doubleList.removeLast();map.remove(key,q);}}doubleList.add(x);map.put(key,x);}
}
后记
以上就是基础的记录过程,个人感觉LRU算法还是蛮重要的,面试时候也是常常问道,可以去LeetCode上查看更多的答案,学习大佬的思想和思维方式。




























还没有评论,来说两句吧...