dubbo集群容错
为了避免单点故障,现在的应用通常至少会部署在两台服务器上。对于一些负载比较高的服务,会部署更多的服务器。这样, 在同一环境下的服务提供者数量会大于1。对于服务消费者来说,同一环境下出现了多个服务提供者。这时会出现一个问题, 服务消费者需要决定选择哪个服务提供者进行调用。另外服务调用失败时的处理措施也是需要考虑的,是重试呢,还是抛出异常,亦或是只打印异常等。为了处理这些问题,Dubbo 定义了集群接口 Cluster 以及 Cluster Invoker。集群 Cluster 用途是将 多个服务提供者合并为一个 Cluster Invoker,并将这个 Invoker 暴露给服务消费者。这样一来,服务消费者只需通过这个 Invoker 进行远程调用即可,至于具体调用哪个服务提供者,以及调用失败后如何处理等问题,现在都交给集群模块去处理。 集群模块是服务提供者和服务消费者的中间层,为服务消费者屏蔽了服务提供者的情况,这样服务消费者就可以专心处理远程调用相关事宜。比如发请求,接受服务提供者返回的数据等。这就是集群的作用。
Dubbo 提供了多种集群实现,包含但不限于 Failover Cluster、Failfast Cluster 和 Failsafe Cluster 等。每种集群实现类的用途不同,接下来会一一进行分析。
集群容错
在对集群相关代码进行分析之前,这里有必要先来介绍一下集群容错的所有组件。包含 Cluster、Cluster Invoker、Directory、 Router 和 LoadBalance 等。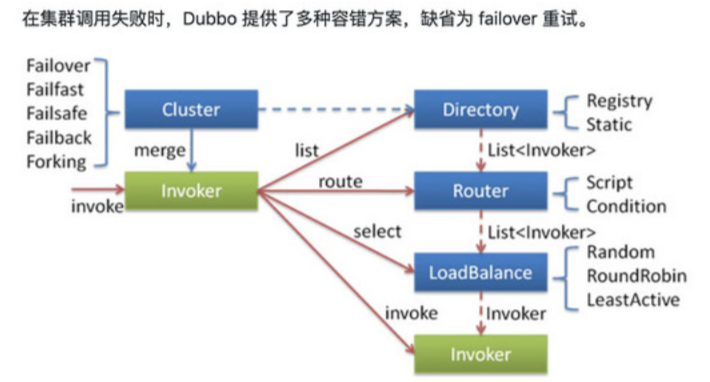
集群工作过程可分为两个阶段,第一个阶段是在服务消费者初始化期间,集群 Cluster 实现类为服务消费者创建 Cluster Invoker 实例,即上图中的 merge 操作。第二个阶段是在服务消费者进行远程调用时。以 FailoverClusterInvoker 为例,该类型 Cluster Invoker 首先会调用 Directory 的 list 方法列举 Invoker 列表(可将 Invoker 简单理解为服务提供者)。Directory 的 用途是保存 Invoker,可简单类比为 List。其实现类 RegistryDirectory 是一个动态服务目录,可感知注册中心配置的 变化,它所持有的 Invoker 列表会随着注册中心内容的变化而变化。每次变化后,RegistryDirectory 会动态增删 Invoker,并 调用 Router 的 route 方法进行路由,过滤掉不符合路由规则的 Invoker。当 FailoverClusterInvoker 拿到 Directory 返回的 Invoker 列表后,它会通过 LoadBalance 从 Invoker 列表中选择一个 Invoker。最后 FailoverClusterInvoker 会将参数传给 LoadBalance 选择出的 Invoker 实例的 invoker 方法,进行真正的远程调用。
以上就是集群工作的整个流程,这里并没介绍集群是如何容错的。Dubbo 主要提供了这样几种容错方式:
- Failover cluster
失败的时候自动切换并重试其他服务器。 通过retries=2。 来设置重试次数 - Failfast cluster
快速失败,只发起一次调用
写操作。比如新增记录的时候, 非幂(服务调用后端某一接口发起多次结果不变)等请求 insert 唯一的key,影响行数只会影响一行 - Failsafe cluster
失败安全 。 出现异常时,直接忽略异常
写日志,不一定要日志保存成功,失败了不能影响主程序的运行 - Failback cluster
失败自动恢复 。 后台记录失败请求,定时重发
比如说消息通知,失败了一直发送 - Forking cluster
并行调用多个服务器,只要一个成功就返回。
只能应用在读请求,会浪费服务器的资源。 - Broadcast cluster
广播调用所有提供者,逐个调用。其中一台报错就会返回异常。
修改集群容错方式
<dubbo:service cluster="failsafe" />
配置的优先级
如果消费端和服务端都设置了超时时间,那么谁的优先级最大
消费端优先级别最高
服务端 Reference method>service method>reference>service>consumer>provider
负载均衡
负载均衡,它的职责是将网络请求,或者其他形式的负载“均摊”到不同的机器上。避免集群中部分服务器压力过大,而另一些服务器比较空闲的情况。通过负载均衡,可以让每台服务器获取到适合自己处理能力的负载。在为高负载服务器分流的同时, 还可以避免资源浪费,一举两得。负载均衡可分为软件负载均衡和硬件负载均衡。在我们日常开发中,一般很难接触到硬件负 载均衡。但软件负载均衡还是可以接触到的,比如 Nginx。
在 Dubbo 中,也有负载均衡的概念和相应的实现。Dubbo 需要对服务消费者的调用请求进行分配,避免少数服务提供者负载 过大。服务提供者负载过大,会导致部分请求超时。
因此将请求负载均衡到每个服务提供者上,是非常必要的。Dubbo 提供了4种负载均衡实现,分别是基于权重随机算法的 RandomLoadBalance、基于最少活跃调用数算法的 LeastActiveLoadBalance、基于 hash 一致性的 ConsistentHashLoadBalance,以及基于加权轮询算法的 RoundRobinLoadBalance。
缺省为random随机调用。
Random LoadBalance
随机,按权重设置随机概率。
RandomLoadBalance 是加权随机算法的具体实现,它的算法思想很简单。假设我们有一组服务器 servers = [A, B, C],他们 对应的权重为 weights = [5, 3, 2],权重总和为10。现在把这些权重值平铺在一维坐标值上,[0, 5) 区间属于服务器 A,[5, 8) 区间属于服务器 B,[8, 10) 区间属于服务器 C。接下来通过随机数生成器生成一个范围在 [0, 10) 之间的随机数,然后计算这个随机数会落到哪个区间上。比如数字3会落到服务器 A 对应的区间上,此时返回服务器 A 即可。权重越大的机器,在坐标轴上对应的区间范围就越大,因此随机数生成器生成的数字就会有更大的概率落到此区间内。只要随机数生成器产生的随机数分布性很好,在经过多次选择后,每个服务器被选中的次数比例接近其权重比例。比如,经过一万次选择后,服务器 A 被选中的 次数大约为5000次,服务器 B 被选中的次数约为3000次,服务器 C 被选中的次数约为2000次。
RoundRobin LoadBalance
轮循,按公约后的权重设置轮循比率。
我们先来了解一下什么是加权轮询。这里从最简单的轮询开始讲起,所谓轮询是指将请求轮流分配给每台服务器。举个例子, 我们有三台服务器 A、B、C。我们将第一个请求分配给服务器 A,第二个请求分配给服务器 B,第三个请求分配给服务器 C, 第四个请求再次分配给服务器 A。这个过程就叫做轮询。轮询是一种无状态负载均衡算法,实现简单,适用于每台服务器性能 相近的场景下。但现实情况下,我们并不能保证每台服务器性能均相近。如果我们将等量的请求分配给性能较差的服务器,这 显然是不合理的。因此,这个时候我们需要对轮询过程进行加权,以调控每台服务器的负载。经过加权后,每台服务器能够得到的请求数比例,接近或等于他们的权重比。比如服务器 A、B、C 权重比为 5 1。那么在8次请求中,服务器 A 将收到其中的5次请求,服务器 B 会收到其中的2次请求,服务器 C 则收到其中的1次请求。
1。那么在8次请求中,服务器 A 将收到其中的5次请求,服务器 B 会收到其中的2次请求,服务器 C 则收到其中的1次请求。
LeastActive LoadBalance
最小活跃数负载均衡。
活跃调用数越小,表明该服务提供者效率越高,单位时间内可处理更多的请求。此时应优先将请求分配给该服务提供者。在具体实现中,每个服务提供者对应一个活跃数 active。初始情况下,所有服务提供者活跃数均 为0。每收到一个请求,活跃数加1,完成请求后则将活跃数减1。在服务运行一段时间后,性能好的服务提供者处理请求的速 度更快,因此活跃数下降的也越快,此时这样的服务提供者能够优先获取到新的服务请求、这就是最小活跃数负载均衡算法的基本思想。除了最小活跃数,LeastActiveLoadBalance 在实现上还引入了权重值。所以准确的来说, LeastActiveLoadBalance 是基于加权最小活跃数算法实现的。举个例子说明一下,在一个服务提供者集群中,有两个性能优异的服务提供者。某一时刻它们的活跃数相同,此时 Dubbo 会根据它们的权重去分配请求,权重越大,获取到新请求的概率就越大。如果两个服务提供者权重相同,此时随机选择一个即可。
ConsistentHash LoadBalance
该类是负载均衡基于 hash 一致性的逻辑实现。首先根据 ip 或其他的信息为缓存节点生成一个 hash,在 dubbo中使用参数进行计算hash。并将这个 hash 投射到 [0, 232 - 1] 的圆环上,当有查询或写入请求时,则生成一个 hash 值。然后查找第一个大于或等于该 hash 值的缓存节点,并到这个节点中查询或写入缓存项。如果当前节点挂了,则在下一次 查询或写入缓存时,为缓存项查找另一个大于其 hash 值的缓存节点即可。大致效果如下图所示(引用一下官网的图)
每个缓存节点在圆环上占据一个位置。如果缓存项的 key 的 hash 值小于缓存节点 hash 值,则到该缓存节点中存储或读取缓存项,这里有两个概念不要弄混,缓存节点就好比dubbo中的服务提供者,会有很多的服务提供者,而缓存项就好比是服务引 用的消费者。比如下面绿色点对应的缓存项也就是服务消费者将会被存储到 cache-2 节点中。由于 cache-3 挂了,原本应该存 到该节点中的缓存项也就是服务消费者最终会存储到 cache-4 节点中,也就是调用cache-4 这个服务提供者。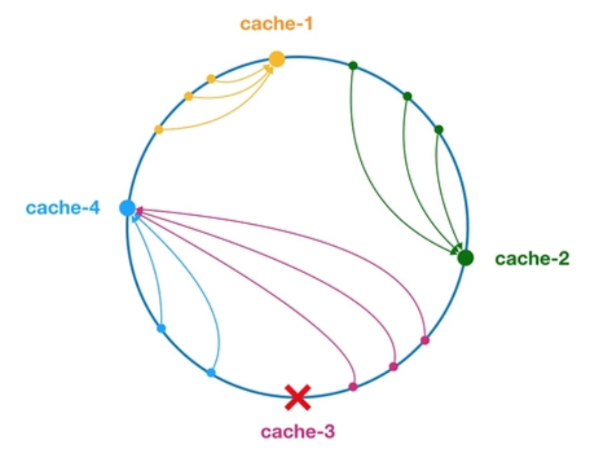
但是在hash一致性算法并不能够保证hash算法的平衡性,就拿上面的例子来看,cache-3挂掉了,那该节点下的所有缓存项都 要存储到 cache-4 节点中,这就导致hash值低的一直往高的存储,会面临一个不平衡的现象,见下图: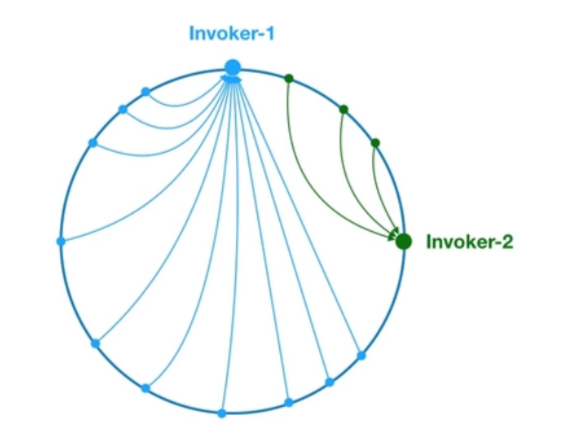
可以看到最后会变成类似不平衡的现象,那我们应该怎么避免这样的事情,做到平衡性,那就需要引入虚拟节点,虚拟节点是 实际节点在 hash 空间的复制品,“虚拟节点”在 hash 空间中以hash值排列。比如下图: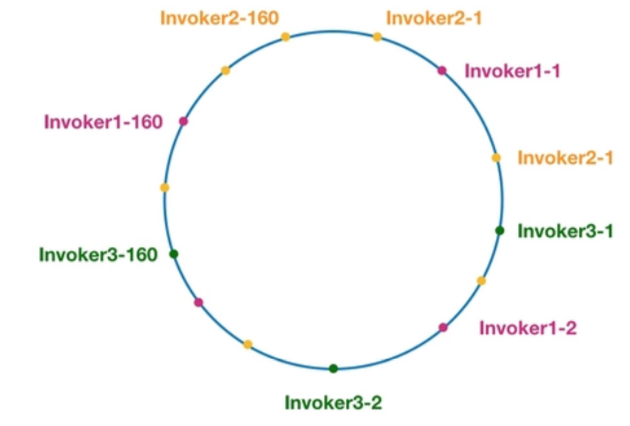
可以看到各个节点都被均匀分布在圆环上,而某一个服务提供者居然有多个节点存在,分别跟其他节点交错排列,这样做的目的就是避免数据倾斜问题,也就是由于节点不够分散,导致大量请求落到了同一个节点上,而其他节点只会接收到了少量请求的情况。类似第二张图的情况。
在 Provider 端尽量多配置 Consumer 端属性
原因如下:
- 作服务的提供方,比服务消费方更清楚服务的性能参数,如调用的超时时间、合理的重试次数等。
- 在 Provider 端配置后,Consumer 端不配置则会使用 Provider 端的配置,即 Provider 端的配置可以作为 Consumer 的缺省值 。
否则,Consumer 会使用 Consumer 端的全局设置,这对于 Provider 是不可控的,并且往往是不合理的 Provider 端尽量多配 置 Consumer 端的属性,让 Provider 的实现者一开始就思考 Provider 端的服务特点和服务质量等问题。
建议在 Provider 端配置的 Consumer 端属性
- timeout:方法调用的超时时间
- retries:失败重试次数,缺省是 2
- loadbalance:负载均衡算法,缺省是随机 random + 权重。还可以配置轮询 roundrobin、最不活跃优先 leastactive 和一 致性哈希 consistenthash 等
actives:消费者端的最大并发调用限制,即当 Consumer 对一个服务的并发调用到上限后,新调用会阻塞直到超时,
- 在方法上配置 dubbo:method 则针对该方法进行并发限制,
- 在接口上配置 dubbo:service,则针对该服务进行并发限制
- executes服务提供方可以使用的最大线程数
- 在 Provider 端配置合理的 Provider 端属性
建议在 Provider 端配置的 Provider 端属性有:
- threads:服务线程池大小
executes:一个服务提供者并行执行请求上限,即当 Provider 对一个服务的并发调用达到上限后,新调用会阻塞,此时 Consumer 可能会超时。
- 在方法上配置 dubbo:method 则针对该方法进行并发限制,
- 在接口上配置 dubbo:service,则针对该服务进行并发限制 项目中多个模块间公共依赖的版本号、scope的控制




























")





还没有评论,来说两句吧...