Hystrix中文开发手册-Hystrix简介(Home)

- Hystrix 是什么 ?
- 为什么要使用Hystrix?
- Hystrix 可以解决什么问题?
- Hystrix 的设置原则是什么?
- Hystrix 如何实现这些设计目标?
Hystrix 是什么?
在分布式的环境中, 一些分布式服务会不可避免的出现的依赖项目发生错误的情况。 Hystrix 就是一个可以通过使用 延时策略 和 故障容错逻辑 帮助您管理控制这些__分布式服务之间交互__的一个库. Hystrix 通过 服务隔离,停止故障服务级联调用并提供应急(最常见的各种no fallback available异常出自这里)计划来改善系统的弹性.
Hystrix的历史
Hystrix源自Netflix API团队于2011年开始的弹性工程工作。2012年,Hystrix不断发展和成熟,Netflix内部的许多团队都采用了它。如今,每天在Netflix上通过Hystrix执行数百亿个线程隔离和数千亿个信号量隔离的调用。这极大地提高了正常运行时间和弹性。
为什么要使用Hystrix?
Hystrix 的设计宗旨 :
- 为第三方系统访问(通常是指通过网络) 中发送的延时和错误(例如:服务数据库异常)提供保护和控制.
- 终止复杂分布式系统中的级联故障 .
- 快速失败(熔断)和快速恢复.
- 回退(fallback) 并且在可能的情况下进行服务降级.
- 启用近乎实时的监视,警报和操作控制.
Hystrix解决了什么问题 ?
在复杂的分布式体系服务中,应用可能拥有数十种依赖程序,每种依赖程序都不可避免的会出现某个时刻的失败。如果主机应用程序未能与这些外部故障进行故障隔离,那么可能导致整个应用服务被宕机。
例如,一个应用程序依赖30个服务,每个服务99.99%的时间是运行正常的,那么可以推算出如下情况:
99.9930 = 99.7% 安全运行时间
如果服务有10亿的请求,那么 0.3% = 3,000,000 次故障
即使每个所有的依赖服务都有如此出色的正常运行时间,但是每个月依旧会有2个小时以上的宕机时间
在现在情况中恐怕会更糟糕(大部分应用都不具备99.99%正常运行时间)。即使每个服务都有着很好的表现,但是当依赖数增加,故障的几率就会被放大,以至于应用停机。
当一切都正常事,请求如下:
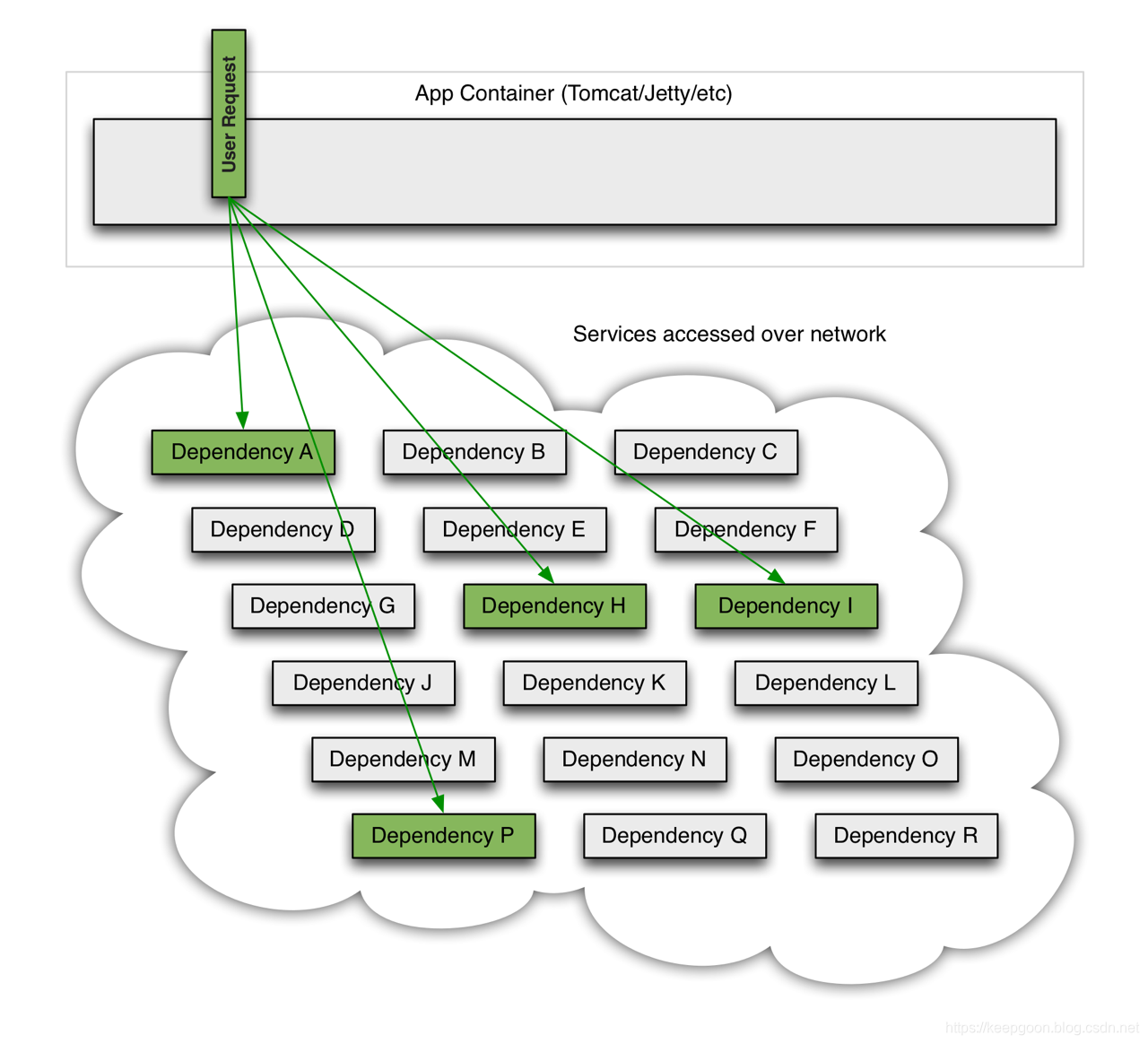
当众多依赖服务中有一个发送故障时,它可能会阻塞全部用户请求:
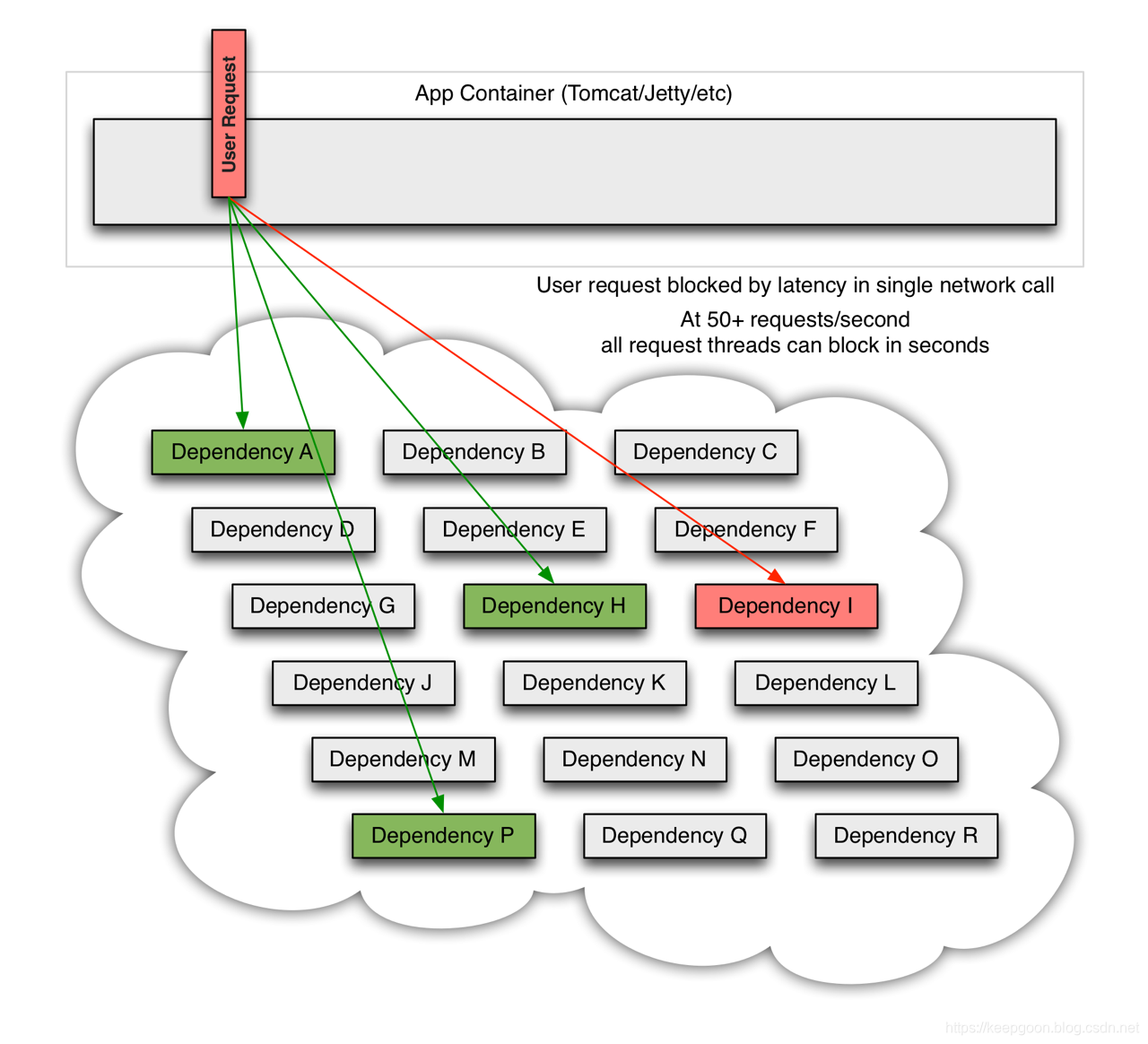
随着高流量访问,单个后端服务发生错误,这可能导致所有服务器上的资源在短短几秒钟内变的饱和(并不是一定会造成资源饱和。例如,该故障请求返回超时,则可能造成线程数急剧增加,若请求不能即使释放,造成网络阻塞)。
应用程序接受到请求,通过网络对每个依赖服务进行访问,这时每个服务都有可能存在潜在的错误。比起当个服务宕机,更可怕的是,这些服务可能导致服务之间的延迟增加,从而导致备份队列,线程和其他资源被占用,从而导致整个系统的级联故障(整个服务集群宕机,甚至造成服务器不可达)。
![(images/soa-3-640.png)\]](https://img-blog.csdnimg.cn/20200120113343571.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9rZWVwZ29vbi5ibG9nLmNzZG4ubmV0,size_16,color_FFFFFF,t_70)
Hystrix 的设计原则
Hystrix 的工作原理:
- 防止单个依赖服务耗尽整个容器(例如:tomcat,jboss等)用户线程
- 减少负载并快速失败,而不是排队(之间断路,而不是等待恢复)。
- 在允许的情况下提供备用机制,保护用户免受故障影响。
- 使用隔离技术 (例如隔离, 泳道, 断路) 去限制一个依赖服务故障带来的影响
- 通过近实时指标,监视和警报优化发现时间
- 通过在Hystrix的大多数方面中以低延迟传播配置更改来优化恢复时间,并支持动态属性更改,这使您可以通过低延迟反馈环路进行实时操作修改。
- 防止整个服务集群执行失败,而不仅仅是网络请求的失败(网络阻塞)。
Hystrix 如何实现其设计目标?
Hystrix 通过以下方式做到了这些:
- 将依赖服务(或者是依赖项)包装在一个单独线程执行的
HystrixCommand或HystrixObservableCommand对象中执行(命令模式)。 - 请求超时花费的时间超过定义的阈值(配置的超时时间)。Hystrix提供一个超时配置,这个配置比实际的请求时间要略高一些,这些请求若发生超时,会直接拒绝请求(这里也是返回 超时异常的主要原因)。
- Hystrix 会维护一个小的线程池(或者信号量);如果信号量或者线程池已满,请求会直接被拒绝而不是等待或排队。
- 计算成功或失败 (通过Hystrix客户端抛出的异常), 超时, 和线程拒绝.
- 如果某个服务的发生错误的百分比超过阈值,则会触发断路器断路(跳闸)。在接线来的一段时间里会自动或者手动的停止特定请求(被执行断路的请求)。
- 对发生请求失败,请求拒绝,请求超时,或断路的请求执行 回退(Fallback)策略。
- 实时的监控和动态配置。
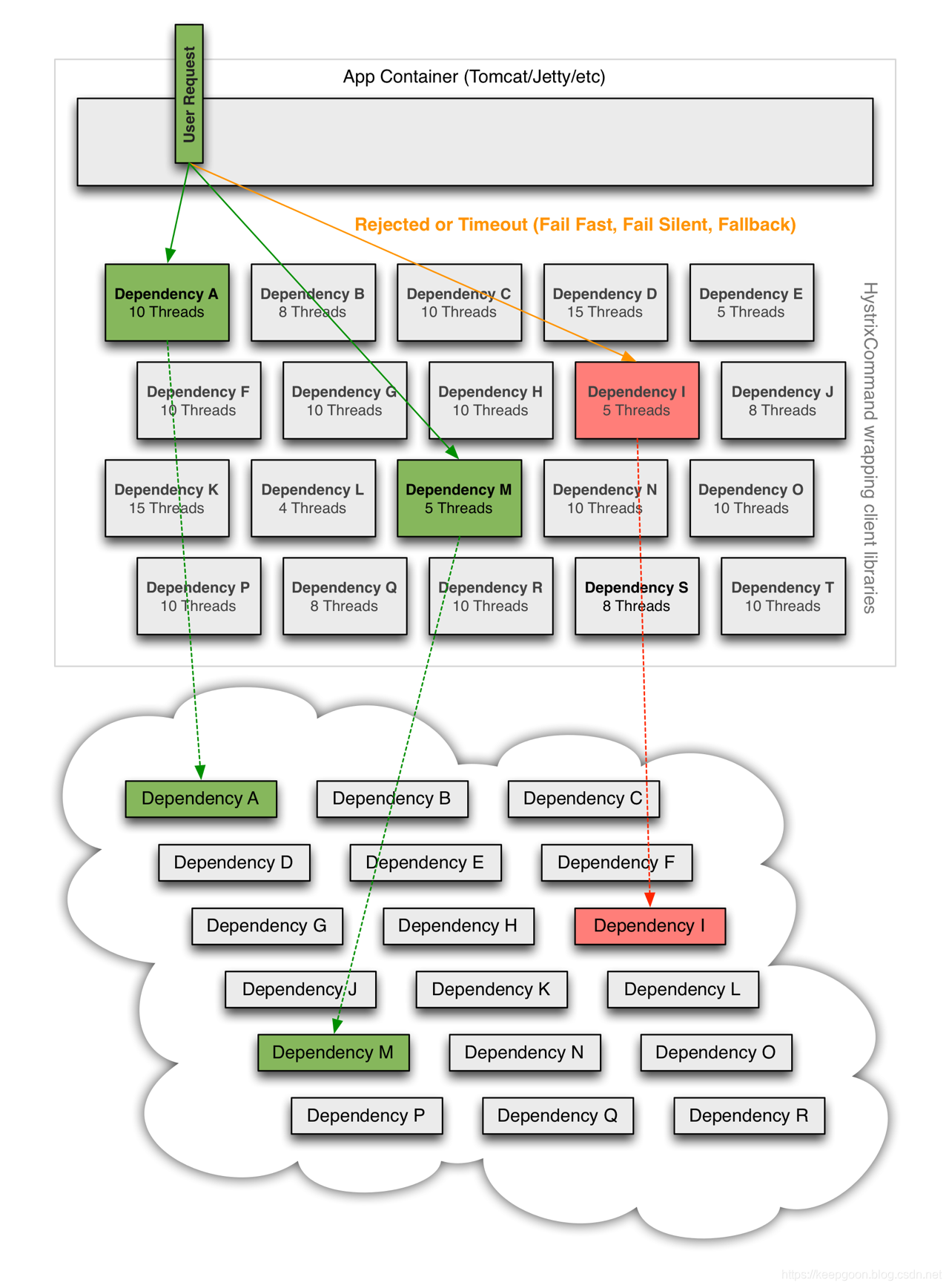
当你使用Hystrix 封装依赖服务时,上图所示的情况的体系结构将会变为类似于下图的情况。每个依赖项彼此隔离(通过HystrixCommand 或 HystrixObservableCommand进行的隔离),当依赖项发生错误,超时,资源(线程,信号量)限制,或者拒绝都会执行回退逻辑。回退逻辑在依赖项发送任何类型的故障时都会做出相应。


























")


——LinearLayout、FrameLayout和AbsoulteLayout")
")



还没有评论,来说两句吧...