(八)Hbase的使用
目录
一、目的及要求:
目的:
要求:
二、环境要求:
集群规划:
三、具体步骤:
Hbase shell的使用
四、总结
一:HBase集群分析
二:HBase总结
一、目的及要求:
目的:
- 掌握完全分布模式的整合平台中HBase的高可用完全分布模式的安装完成Mysql集群的安装
- 完成Hbase的高可用完全分布模式的安装
要求:
- Hbase的相关服务进程能正常启动
- HBase控制台正常使用表创建,数据查询等数据库操作正常进行
二、环境要求:
操作系统:Linux
Hadoop**版本:1.2.1或以上**
JDK**版本:1.6及以上**
- 五台独立PC机或虚拟机
- 主机之间有有效的网络连接
- 已安装CentOS 7.4操作系统
- 所有主机已完成网络属性配置
- 所有主机已安装 JDK
- 所有主机已安装zookeeper的安装和部署
- 所有主机已完成Hadoop集群的安装和部署
集群规划:
HBase**有主节点和Region节点2类 服务节点,高可用完全分布模式中需要满足主节点有备用功能的基本要求,所以需要两台或者两台以上的主机作为主节点,而完全分布模式中需要满足Re.0.gion有备份和数据处理能够分布并行的基本需求,所以要两台或者两台以上的主机作为Region节点,具体规划如下:**
| 主机名 | IP地址 | 服务描述 |
| Cluster-01 | 192.168.10.111 | HBase主控节点 |
| Cluster-02 | 192.168.10.112 | HBase备用主控节点 |
| Cluster-03 | 192.168.10.113 | HBase Region服务 |
| Cluster-04 | 192.168.10.114 | HBase Region服务 |
| Cluster-05 | 192.168.10.115 | HBase Region服务 |
三、具体步骤:
Hbase shell**的使用**
★该项的所有操作步骤使用专门用于集群的用户admin进行。
★启动HBase集群之前首先确保Zookeeper集群已被开启状态。(实验5台 ) Zookeeper的启动 需要分别在每个计算机的节点上手动启动。如果家目录下执行启动报错,则需要进入zookeeper/bin目录执行启动命令。
★启动HBase集群之前首先确保Hadoop集群已被开启状态。(实验5台 ) Hadoop和Hbase只 需要在主节点执行启动命令。
1. 检查各个主机之间的服务是否启动
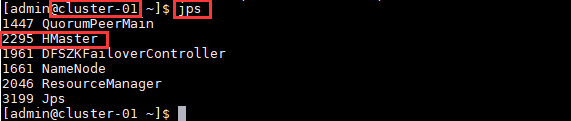




2. 进入hbase shell

3. 新建表空间



4. 新建一个表和列族(默认表空间)


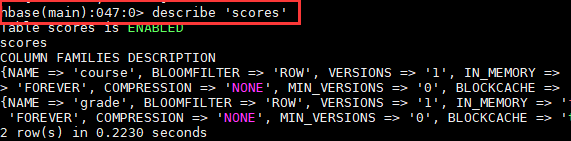
5. 将设计的表结构插入值






6. 根据键值查询数据


7. 扫描所有数据

8. 统计行数

9. 删除指定数据


10. 删除整行



11. 将整张表清空


12. 表的删除



新建表格
| name | grade | course | ||
| yingyu | shuxue | daolun | ||
| yeiwei | 1 | 99 | 92 | 98 |
| maxiao | 1 | 94 | 97 | 99 |
| zhaoying | 1 | 95 | 96 | 89 |
| yuanyang | 1 | 93 | 95 | 97 |
13. 插入语句脚本
create 'scores','grade','course'listput 'scores','yewei','grade:','1'put 'scores','yewei','course:yingyu','99'put 'scores','yewei','course:shuxue','92'put 'scores','yewei','course:dailong','98'put 'scores','maxiao','grade:','1'put 'scores','maxiao','course:yingyu','94'put 'scores','maxiao','course:shuxue','97'put 'scores','maxiao','course:dailong','99'put 'scores','zhaoying','grade:','1'put 'scores','zhaoying','course:yingyu','95'put 'scores','zhaoying','course:shuxue','96'put 'scores','zhaoying','course:dailong','89'put 'scores','yuanyang','grade:','1'put 'scores','yuanyang','course:yingyu','93'put 'scores','yuanyang','course:shuxue','95'put 'scores','yuanyang','course:dailong','97'
14. 验证

四、总结
所用及命令:

一:HBase集群分析

REGION**:是HBASE中对表进行切割的单元**
HMASTER**: HBASE的主节点,负责整个集群的状态感知,负载分配、负责用户表的元数据管理 (可以配置多个用来实现HA)**
为regionserver分配region,负责regionserver负载均衡
用户对表的增删改查
如果当前的regionserver宕机,会把region迁移
REGION-SERVER**: HBASE中真正负责管理region的服务器,也就是负责为客户端进行表数据读写的服务器**
维护master给它的region
当这个region过大的情况下,他还负责切分这个过大的region
(负责客户端的IO请求,去hdfs上进行读写数据)
ZOOKEEPER: 整个HBASE中的主从节点协调,主节点之间的选举,集群节点之间的
上下线感知……都是通过zookeeper来实现
Region 存储寻址入口
监控:REGION SERVER 上下线 把这个状态告诉master
存储hbase的schema(当前哪些表,表里有哪些列族)
二:HBase总结
(1)HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
(2)HBase**是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用 Chubby作为协同服务,HBase利用Zookeeper作为对应来源**
(3)HMaster**没有单点问题,HBase中可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master运行,HMaster在功能上主要负责Table和Region的管理工作:**
- 管理用户对Table的增、删、改、查操作
- 管理HRegionServer的负载均衡,调整Region分布
- 在Region Split后,负责新Region的分配
- 在HRegionServer停机后,负责失效HRegionServer 上的Regions迁移
(4)HRegionServer
HRegionServer**主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBase中最核心的模块。**
HRegionServer内部管理了一系列HRegion对象,每个HRegion对应了Table中的一个 Region,HRegion中由多个HStore组成。每个HStore对应了Table中的一个Column Family的存储,可以看出每个Column Family其实就是一个集中的存储单元,因此最好将具备共同IO特性的column放在一个Column Family中,这样最高效。




























还没有评论,来说两句吧...