MySQL数据库基础学习
数据库概述
一、常见的概念
数据库(DataBase):数据库是按照数据结构来组织、存储和管理数据的仓库。数据库管理系统(Database Management SystemDBMS):是专门用于管理数据库的计算机系统软件。数据库管理系统能够为数据库提供数据的定义、建立、维护、查询和统计等操作功能,并完成对数据完整性、安全性进行控制的功能。
二、发展历程
我们一般说的数据库,就是指的DBMS: 数据库服务器。数据库技术发展历程如下:
- 层次数据库和网状数据库技术阶段:使用指针来表示数据之间的联系。
- 关系数据库技术阶段:经典的里程碑阶段。代表DBMS有Oracle、DB2、MySQL、SQL Server等。
- 后关系数据库技术阶段:关系型数据库存在数据模型,性能,拓展伸缩性的缺点,出现了:
ORDBMS:面向对象数据库技术。
NoSQL :结构化数据库技术。
随着大数据的不断发展,非关系型的数据库现在成了一个极其热门的新领域,非关系数据库产品的发展非常迅速,产生了一系列出色的NoSQL数据库。
常见的NoSQL数据库分为四大类
- 键值存储数据库:Oracle BDB,Redis,BeansDB
- 列式储数数据库:HBase,Cassandra,Riak
- 文档型数据库:MongoDB,CouchDB
- 图形数据库:Neo4J,InfoGrid,Infinite Graph
常见的关系数据库:
| 数据库系 | 所属公司 |
|---|---|
| Oracle | Oracle |
| SQL Server | MS |
| DB2 | IBM |
| MySQL | AB–>SUN–>Oracle |
特点比较:
- Oracle:运行稳定,可移植性高,功能齐全,性能超群!适用于大型企业领域,但是价格昂贵。
- DB2:速度快、可靠性好,适于海量数据,恢复性极强。适用于大中型企业领域,但是价格昂贵。
- SQL Server:全面,效率高,界面友好,操作容易,但是不跨平台。适用于中小型企业领域。
- MySQL:开源,体积小,速度快。适用于中小型企业领域。
数据库基础
数据库和数据库对象
一般来说我们说的数据库(MySQL/Oracle等)指的都是数据库服务器(DBMS)
数据库:存储数据库对象的容器。
数据库对象:存储,管理和使用数据的不同结构形式,如:表、视图、存储过程、函数、触发器、事件等。
数据库分两种:
系统数据库(系统自带的数据库):不能修改
information_schema:存储数据库对象信息,如:用户表信息,列信息,权限,字符,分区等信息
performance_schema:存储数据库服务器性能参数信息。mysql:存储数据库用户权限信息。sys:系统配置信息。
用户数据库(用户自定义的数据库):一般的,一个项目一个用户数据库。
(一)数据库操作
1、创建数据库
create database 数据库名;create database runoob;
2、选择数据库
use 数据库名;use runoob;
3、删除数据库
drop database 数据库名;drop database runoob;
4、查看数据库
查看数据库服务器存在哪些数据库: SHOW DATABASES;查看指定的数据库中有哪些数据表: SHOW TABLES;
(二)数值类型

(三)数据表
1、创建数据表
表的约束:表的约束(针对于某一列):
- 非空约束:NOT NULL(NK),不允许某列的内容为空。
- 设置列的默认值:DEFAULT。
- 唯一约束:UNIQUE(UK),在该表中,该列的内容必须唯一。
- 主键约束:PRIMARY KEY(PK), 非空且唯一。
- 主键自增长:AUTO_INCREMENT,从1开始,步长为1。(MySQL特有)
- 外键约束:FOREIGN KEY(FK),A表中的外键列的值必须参照于B表中的某一列(B表主键)。
主键设计:
1:单列主键,单列作为主键,建议使用。复合主键,使用多列充当主键,不建议。2:主键分为两种:1)自然主键:使用有业务含义的列作为主键(不推荐使用);2)代理主键:使用没有业务含义的列作为主键(推荐使用);CREATE TABLE 数据表名 (字段名 字段类型);CREATE TABLE `runoob_tbl`(`runoob_id` INT UNSIGNED AUTO_INCREMENT,`runoob_title` VARCHAR(100) NOT NULL,`runoob_author` VARCHAR(40) NOT NULL,`submission_date` DATE,PRIMARY KEY ( `runoob_id` ))ENGINE=InnoDB DEFAULT CHARSET=utf8;
2、删除数据表
删除表:DROP TABLE table_name;
DROP TABLE 数据表名 ;DROP TABLE runoob_tbl ;
3、查看数据表
- 查看表目录:SHOW TABLES;
- 查看表结构: DESC table_name;
- 查看DDL语句:SHOW CREATE TABLE table_name;
(四)数据操作
1、增
INSERT INTO table_name ( field1, field2,...fieldN )VALUES( value1, value2,...valueN );INSERT INTO runoob_tbl (runoob_title, runoob_author, submission_date)VALUES("学习 PHP", "菜鸟教程", NOW());
2、删
DELETE FROM table_name [WHERE Clause];DELETE FROM runoob_tbl WHERE runoob_id=1;
3、改
UPDATE table_name SET field1=new-value1, field2=new-value2[WHERE Clause];UPDATE runoob_tbl SET runoob_title='学习 C++' WHERE runoob_id=1;
4、查
SELECT field1, field2,...fieldN FROM table_name1, table_name2...[WHERE condition1 [AND [OR]] condition2.....SELECT * from runoob_tbl WHERE runoob_author='菜鸟教程';
(五)查询
1、WHERE 2、ORDER BY
2、ORDER BY
SELECT field1, field2,...fieldN table_name1, table_name2...ORDER BY field1, [field2...] [ASC [DESC]];SELECT * from runoob_tbl ORDER BY submission_date ASC;
3、GROUP BY
GROUP BY 语句根据一个或多个列对结果集进行分组。
在分组的列上我们可以使用 COUNT, SUM, AVG,等函数。
SELECT column_name, function(column_name)FROM table_nameWHERE column_name operator valueGROUP BY column_name;SELECT name, COUNT(*) FROM employee_tbl GROUP BY name;
4、HAVING
通过HAVING子句对分组结果进行二次筛选
5、LIMIT
LIMIT限制查询结果显示条数
LIMIT 显示条数
SELECT * FROM table LIMIT 5; // 检索记录前5行
LIMIT 偏移量 显示条数
SELECT * FROM table LIMIT 5,10; // 检索记录行 6-15
6、联合查询
UNION 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合中。多个 SELECT 语句会删除重复的数据。
SELECT expression1, expression2, ... expression_nFROM tables[WHERE conditions]UNION [ALL | DISTINCT]SELECT expression1, expression2, ... expression_nFROM tables[WHERE conditions];
参数
- expression1, expression2, … expression_n: 要检索的列。
- tables: 要检索的数据表。
- WHERE conditions: 可选, 检索条件。
- DISTINCT: 可选,删除结果集中重复的数据。默认情况下 UNION 操作符已经删除了重复数据,所以 DISTINCT 修饰符对结果没啥影响。
- ALL: 可选,返回所有结果集,包含重复数据。
7、子查询
子查询是将一个查询语句嵌套在另一个查询语句中,内查询语句查询的结果,可以作为外查询语句提供条件
使用【NOT】 IN 的子查询
employee 员工表
depId 员工表 中所属部门id
department 部门表
SELECT id,username FROM employee WHERE depId IN(SELECT id FROM department);
使用比较运算符的子查询 = 、> 、<、>=、<=、<>、!=、< >、<=>
使用【NOT】 EXISTS的子查询
使用ANY|SOME或者ALL的子查询
8、范围查询 BTEWEEN AND
使用BETWEEN运算符显示某一值域范围的记录,这个操作符最常见的使用在数字类型数据的范围上,但对于字符类型数据和日期类型数据同样可用。格式:SELECT <columnList> FROM table_nameWHERE 列名 BETWEEN minvalue AND maxvalue:闭区间。
9、空值查询 IS NULL
IS NULL:判断列的值是否为空。格式:WHERE 列名 IS NULL;
10、JOIN
JOIN 按照功能大致分为如下三类:
INNER JOIN(内连接,或等值连接):获取两个表中字段匹配关系的记录。
LEFT JOIN(左连接):获取左表所有记录,即使右表没有对应匹配的记录。
RIGHT JOIN(右连接): 与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录。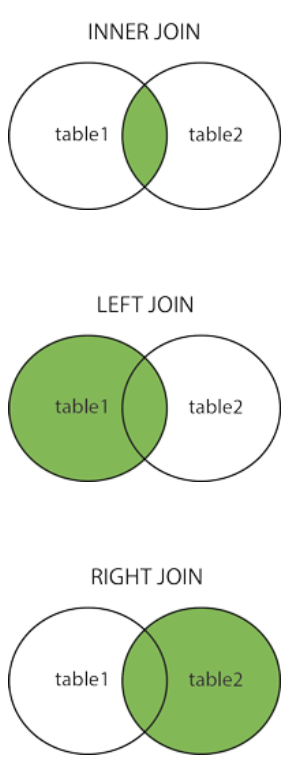
SELECT a.runoob_id, a.runoob_author, b.runoob_count FROM runoob_tbl aINNER JOIN tcount_tbl bON a.runoob_author = b.runoob_author
(六)正则表达式

查找name字段中以’st’为开头的所有数据:
SELECT name FROM person_tbl WHERE name REGEXP '^st';
(七)MySQL 事务
1、事务介绍
MySQL 事务主要用于处理操作量大,复杂度高的数据。比如说,在人员管理系统中,你删除一个人员,你即需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱,文章等等,这样,这些数据库操作语句就构成一个事务!
在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务。
事务处理可以用来维护数据库的完整性,保证成批的 SQL 语句要么全部执行,要么全部不执行。
事务用来管理 insert,update,delete 语句
2、事务控制语句
BEGIN或START TRANSACTION;显式地开启一个事务;
COMMIT;也可以使用COMMIT WORK,不过二者是等价的。COMMIT会提交事务,并使已对数据库进行的所有修改成为永久性的;
ROLLBACK;有可以使用ROLLBACK WORK,不过二者是等价的。回滚会结束用户的事务,并撤销正在进行的所有未提交的修改;
(八)字段操作
1、增
ALTER TABLE 数据表名 ADD 新增字段 字段类型;ALTER TABLE runoob_tbl ADD status tinyint(1) NOT NULL DEFAULT '0' COMMENT '状态 0正常 1删除';
2、删
ALTER TABLE 数据表名 DROP 字段名;ALTER TABLE runoob_tbl DROP status;
3、改
#例如,把字段 c 的类型从 CHAR(1) 改为 CHAR(10),可以执行以下命令:ALTER TABLE testalter_tbl MODIFY c CHAR(10);ALTER TABLE testalter_tbl CHANGE c c CHAR(10);#修改字段类型及名称#在 CHANGE 关键字之后,紧跟着的是你要修改的字段名,然后指定新字段名及类型。尝试如下实例:#例如,把字段 c 改成 字段 j ,类型从 CHAR(1) 改为 CHAR(10),可以执行以下命令:ALTER TABLE testalter_tbl CHANGE c j CHAR(10);#ALTER TABLE 对 Null 值和默认值的影响ALTER TABLE testalter_tbl MODIFY j BIGINT NOT NULL DEFAULT 100;#修改字段默认值ALTER TABLE testalter_tbl ALTER i SET DEFAULT 1000;#修改表名ALTER TABLE testalter_tbl RENAME TO alter_tbl;
(九)索引
1、创建普通索引
#这是最基本的索引,它没有任何限制。它有以下几种创建方式:#(1)创建索引CREATE INDEX indexName ON mytable(username(length));#如果是CHAR,VARCHAR类型,length可以小于字段实际长度;如果是BLOB和TEXT类型,必须指定 length。#(2)创建表的时候直接指定CREATE TABLE mytable(ID INT NOT NULL,username VARCHAR(16) NOT NULL,INDEX [indexName] (username(length)));
2、创建唯一索引
#它与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。它#有以下几种创建方式:#(1)创建索引CREATE UNIQUE INDEX indexName ON mytable(username(length)) ;#(2)创建表的时候直接指定CREATE TABLE mytable(ID INT NOT NULL,username VARCHAR(16) NOT NULL,UNIQUE [indexName] (username(length)));
3、删除索引
DROP INDEX [indexName] ON mytable;
4、使用ALTER 命令添加和删除索引
有四种方式来添加数据表的索引:#(1)该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL。ALTER TABLE tbl_name ADD PRIMARY KEY (column_list);#(2)这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)。ALTER TABLE tbl_name ADD UNIQUE index_name (column_list);#(3)添加普通索引,索引值可出现多次。ALTER TABLE tbl_name ADD INDEX index_name (column_list);#(4)该语句指定了索引为 FULLTEXT ,用于全文索引。ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list);#添加索引实例ALTER TABLE testalter_tbl ADD INDEX (c);#删除索引实例ALTER TABLE testalter_tbl DROP INDEX c;
MySQL数据库思维导图


























盒子模型,边框,内外边距,盒子模型布局,ps基本操作,列表样式,圆角边框,盒子阴影")








还没有评论,来说两句吧...