java爬取商品评论,分词生成词云
需求
一般我们在购买一件商品的时候,都会习惯性的翻看评论,查看大家对这件商品的评价,但是有时候评论太多,而我们想快速了解一下消费者对这件商品的评价是什么样的。
这里就使用java实现一个简单爬虫,爬取某款内存条的评论,根据评论中的关键词生成词云,让我们对这款内存条有一个大致的了解。结果如下:
可见,大家对这款内存条的评价还是不错的。
具体实现
找到获取商品评论信息的api
打开一个购物网站的首页,搜索关键词“内存条”,我们以第一个为例,下拉找到“评价”。可见“商品介绍”、“商品评价”等是使用tab栏切换来实现的,于是我们猜测这里点击“商品评价”的时候前端会使用ajax向后端发送请求获取数据。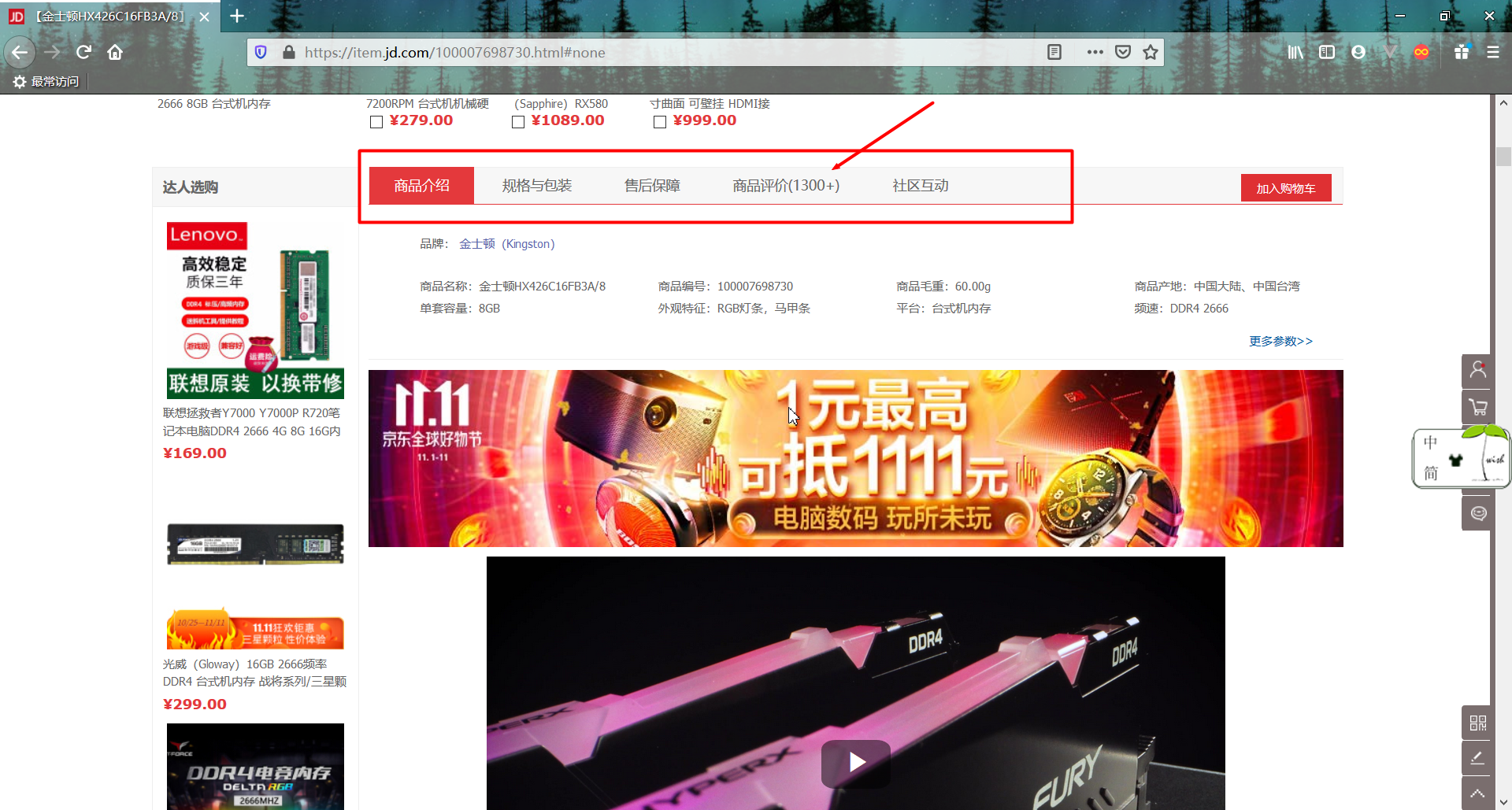
于是我们按F12打开控制台(这里以火狐浏览器为例),找到“网络”,再点击:“商品评价”,这个时候可以看到浏览器发出的所有请求以及服务器做出的响应(如果没有请求显示的话可能是浏览器有缓存,我们可以选择禁用缓存,再次刷新)。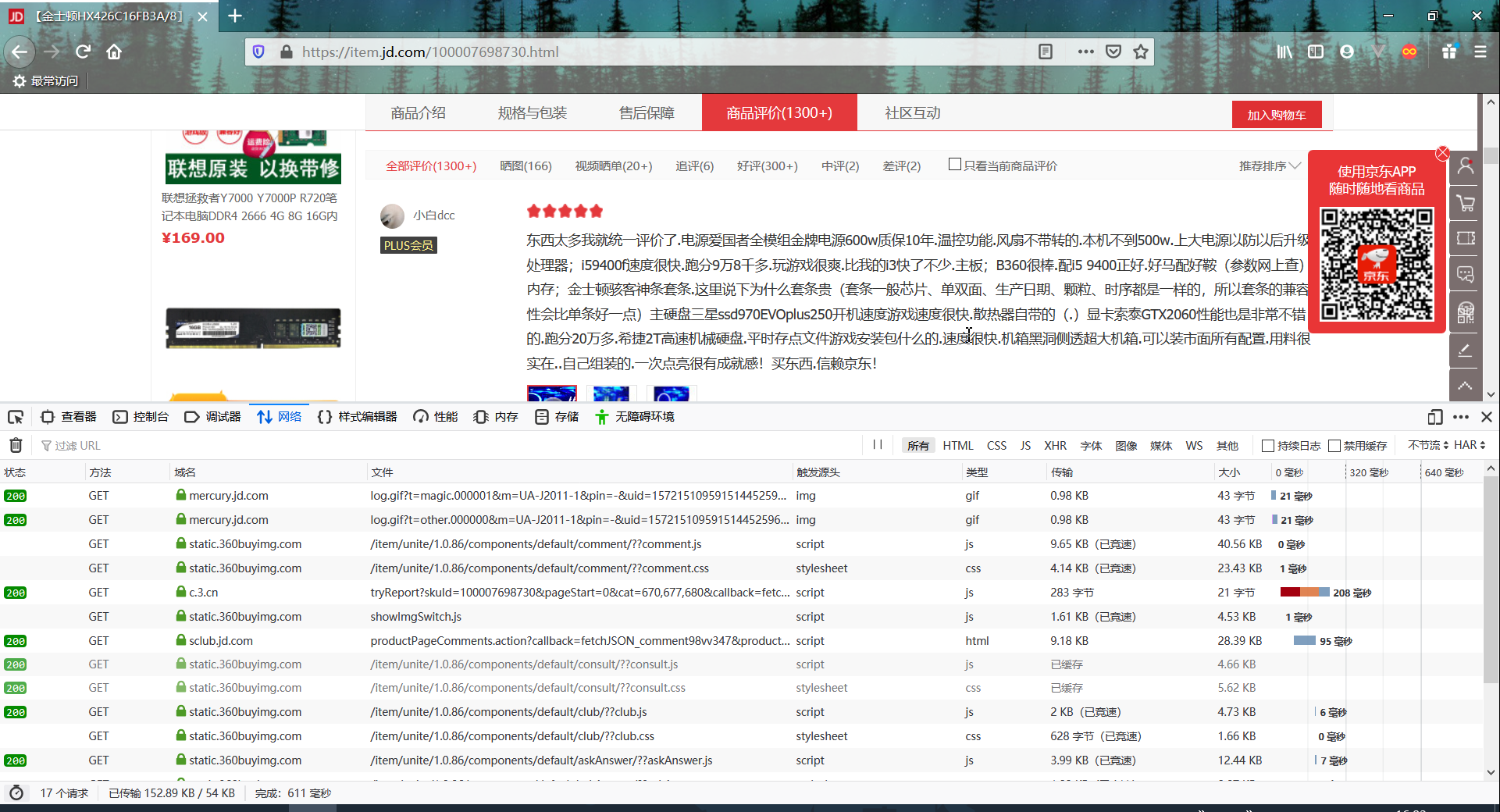
这个时候我们就开始寻找哪条请求是获取所有评论的请求了,在过滤条件我们选择HTML和其他,可以过滤出后端返回的数据类型为json或者html的请求。我们发现有两个返回数据比较大,初步猜测获取评论的api是其中一个。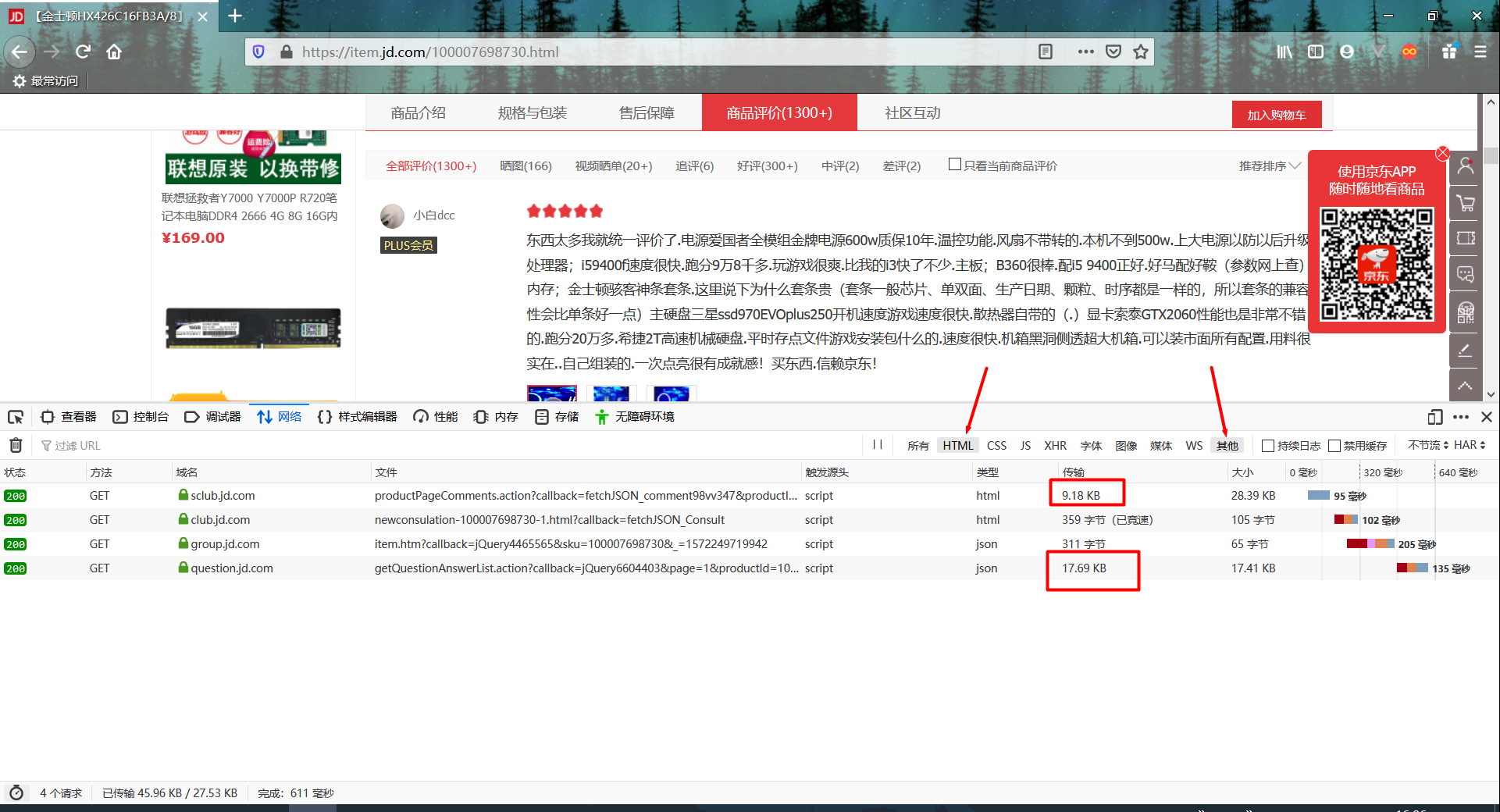
点开进行对比之后,我们可以找到获取评论对应的接口: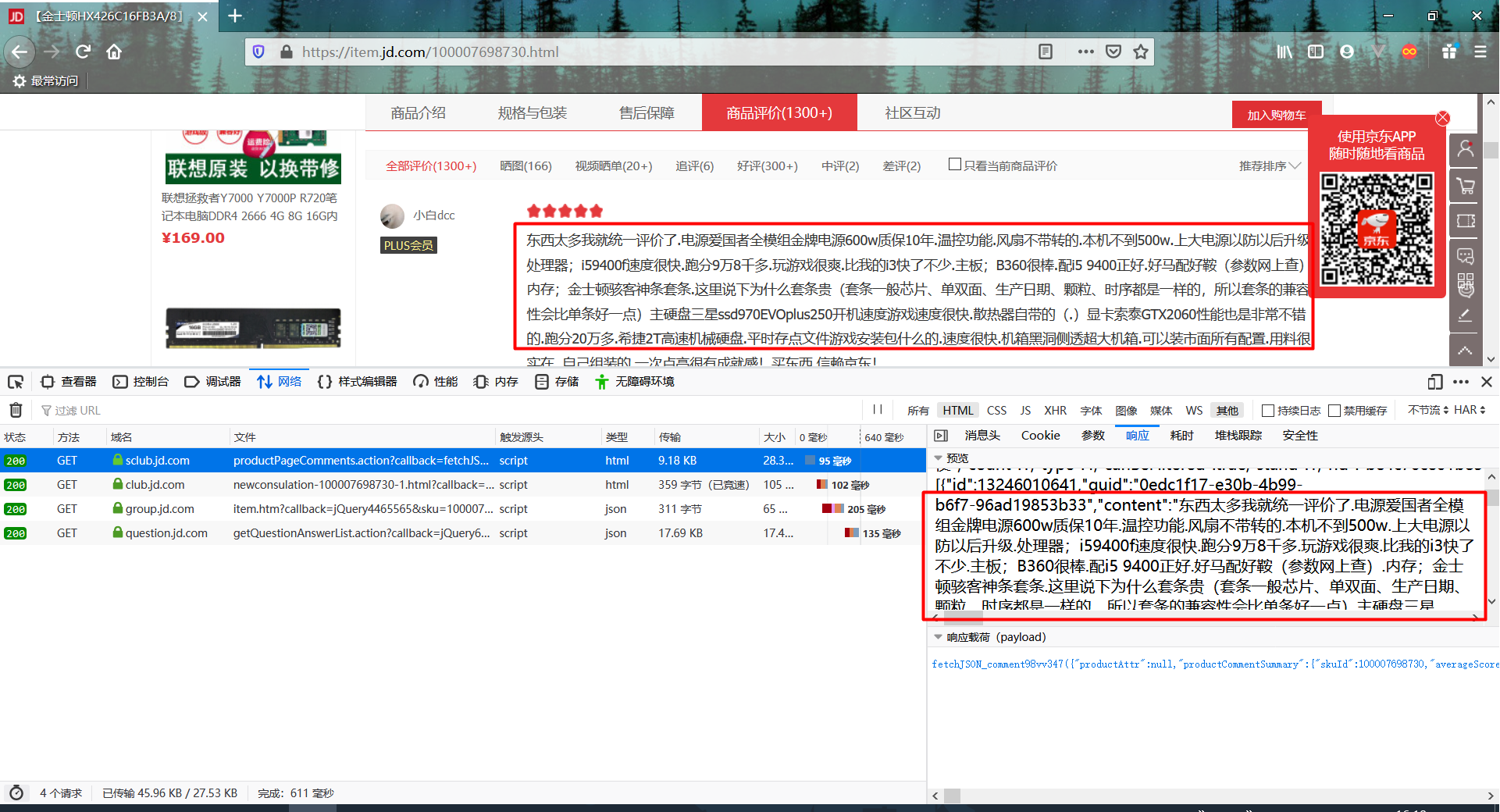
这个时候我们就拿到了获取评论的api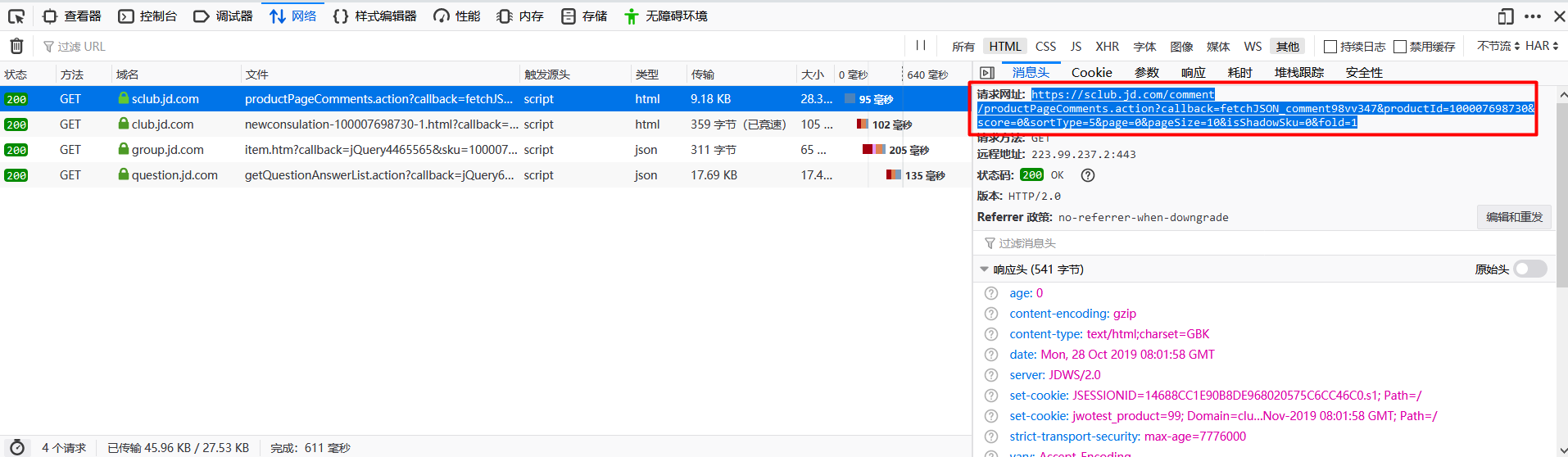
通过代码发送请求
新建一个maven项目,关于发送请求的工具类,这里使用的是Hutool,详细信息可以参考官方文档:https://www.hutool.cn/docs/\#/
<dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.0.3</version></dependency>
在发送请求之前我们需要先设置请求头信息:
其中字段User-Agent用于传达浏览器的种类,这里我们就伪装成火狐浏览器。字段Referer会告知服务器请求的原始资源的 URI,也就是说这个字段表示请求是从哪个页面发起的。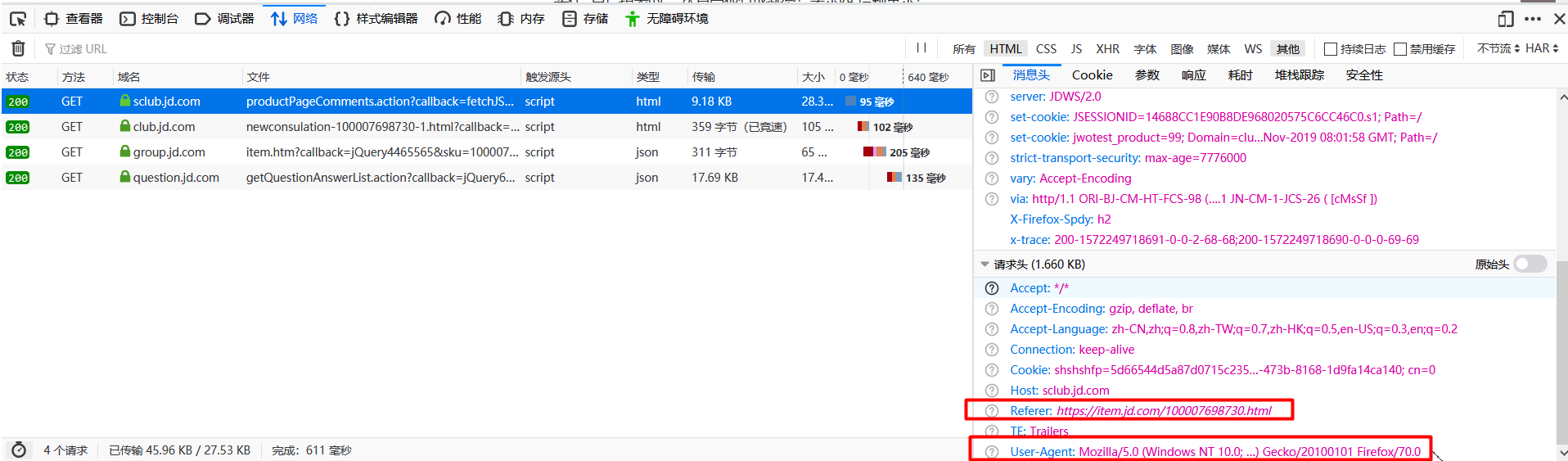
public class App {public static final String GET_COMMENTS_URL = "https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv347&productId=100007698730&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1";public static void main(String[] args) {HttpRequest req = HttpUtil.createGet(GET_COMMENTS_URL);req.header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0");req.header("Referer", "https://item.jd.com/45194954688.html");System.out.println(req.execute().body());}}
运行结果如下,我们会发现这是一段jsonp格式的内容,去掉头尾多余部分就是我们需要的json字符串: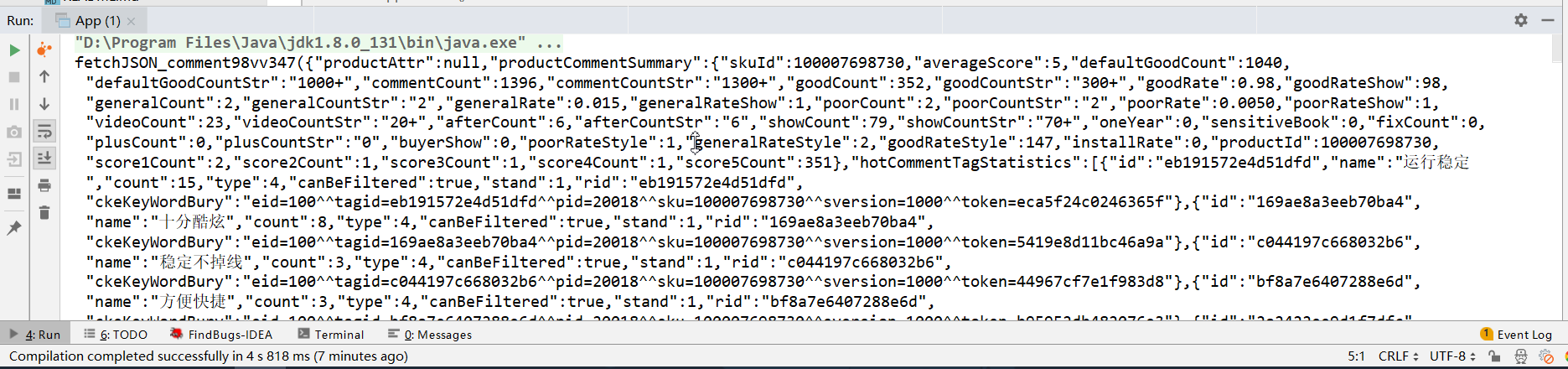
这个时候我们可以复制json信息,在百度搜索“json格式化”,会有许多在线格式化json的工具。
个人推荐这个网站:https://www.json.cn/

这个时候我们就可以看到comments数组是评论信息,其中content字段就是评论的内容。知道了评论内容的具体位置之后下面就是解析json了,这里使用alibaba的fastjson,爬取到评论内容之后我们先将其存入List中。
fastjson依赖
com.alibaba
fastjson
1.2.62 public static void main(String[] args) {
HttpRequest req = HttpUtil.createGet(GET_COMMENTS_URL);req.header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0");req.header("Referer", "https://item.jd.com/45194954688.html");String respJson = StrUtil.sub(req.execute().body(), 25, -2);JSONObject jsonObject = JSON.parseObject(respJson);JSONArray comments = jsonObject.getJSONArray("comments");ArrayList<String> list = new ArrayList<>();comments.forEach(comment -> list.add(((JSONObject) comment).get("content").toString()));list.forEach(System.out::println);
}
其中StrUtil.sub为Hutool工具类中的方法,用于分割字符串,这里用于提取出json字符串
运行结果如下: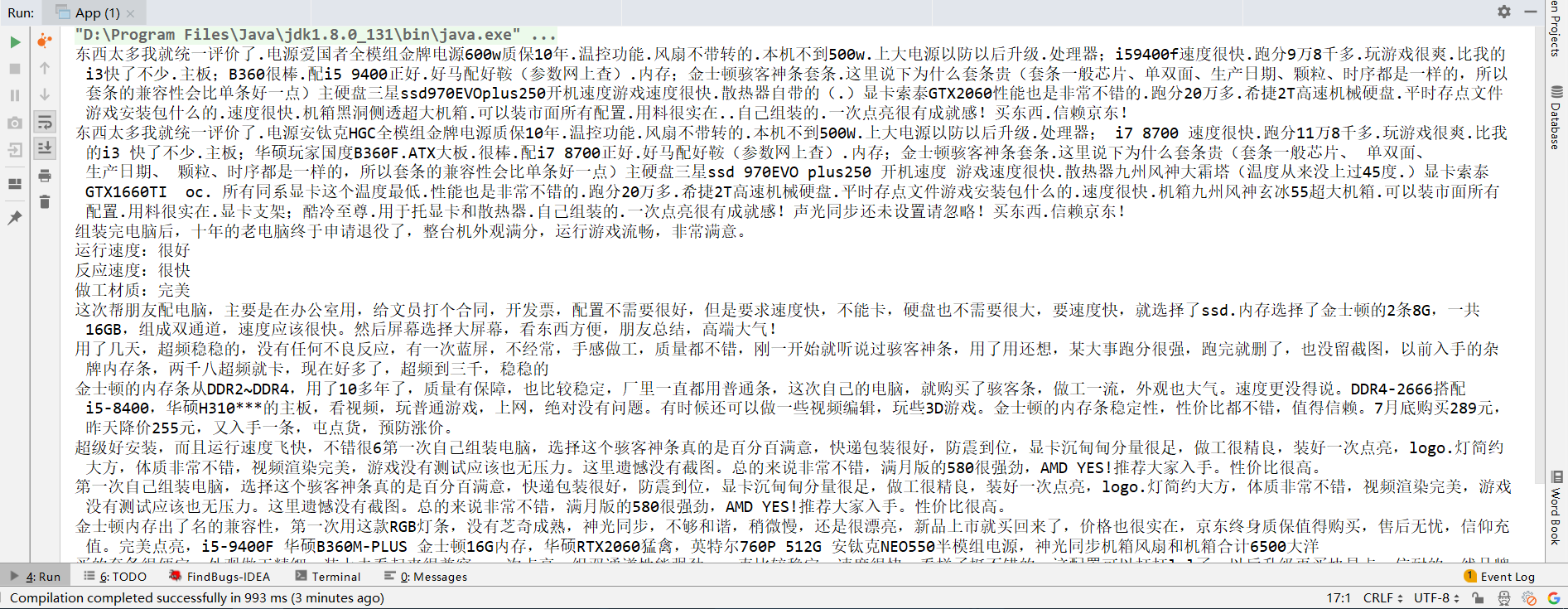
分页获取数据,以及代码的封装
观察url的参数,发现出现了名字为page的参数,猜测这里的page表示页码。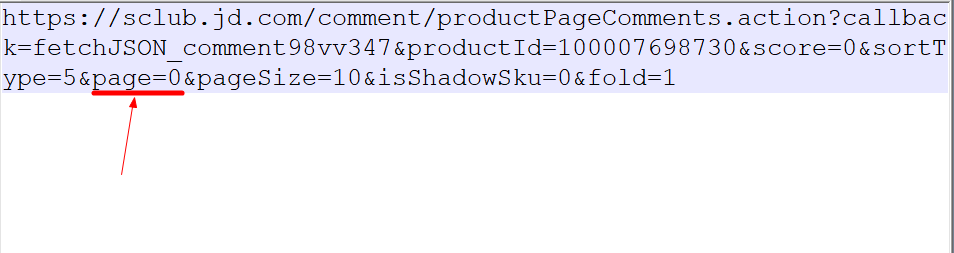
当我们点击第二页的时候,再次查看控制台,找到请求的url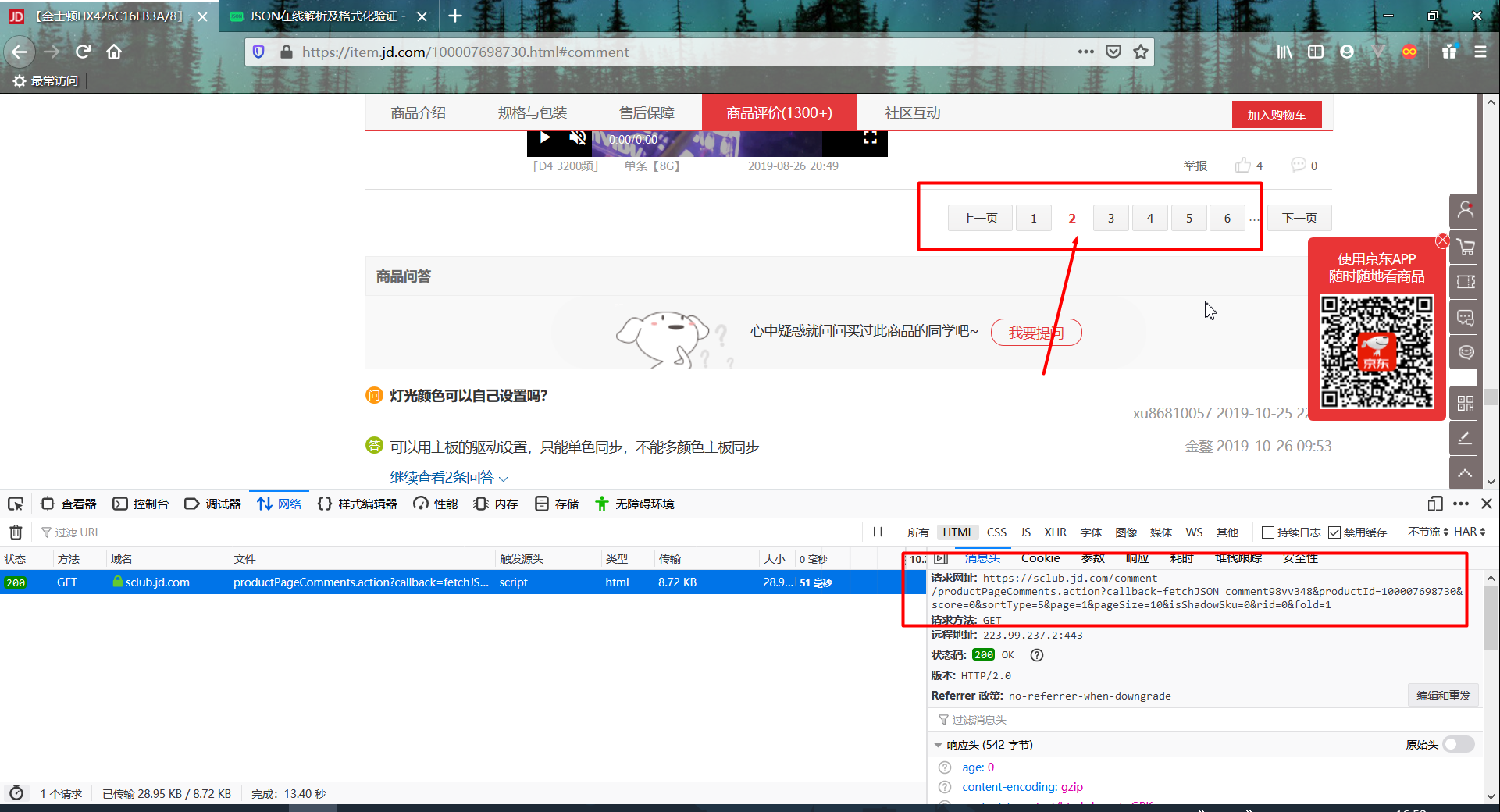
对比两个url,发现page由0变为1
这里我们就可以封装一个方法用于获取所有评论,并将数据储存到文件中(这个过程可能会很慢):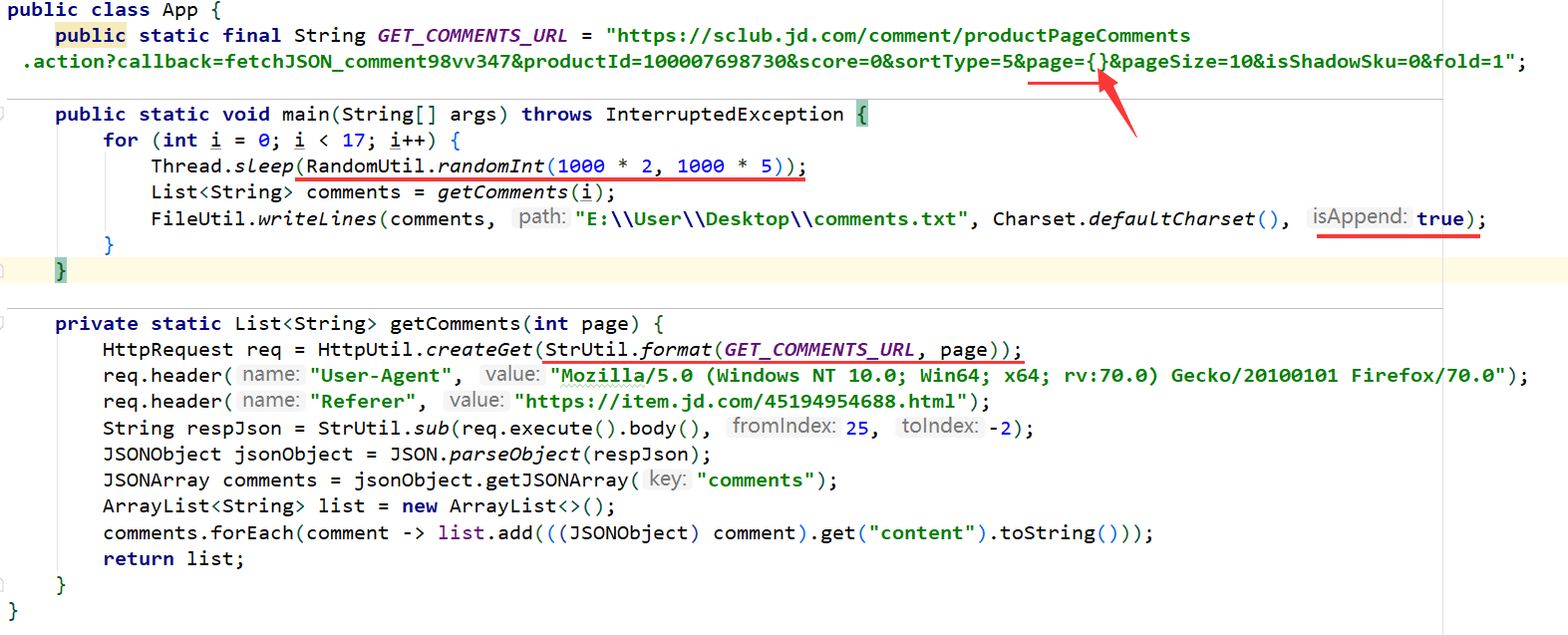
StrUtil.format用于格式化字符串
RandomUtil.randomInt用户产生2秒到5秒之间的随机时间,防止ip被封
FileUtil.write用于将字符串写入文件,并采用追加模式
详情可以参考Hutool的官网。
运行程序之后发现评论已写入文件: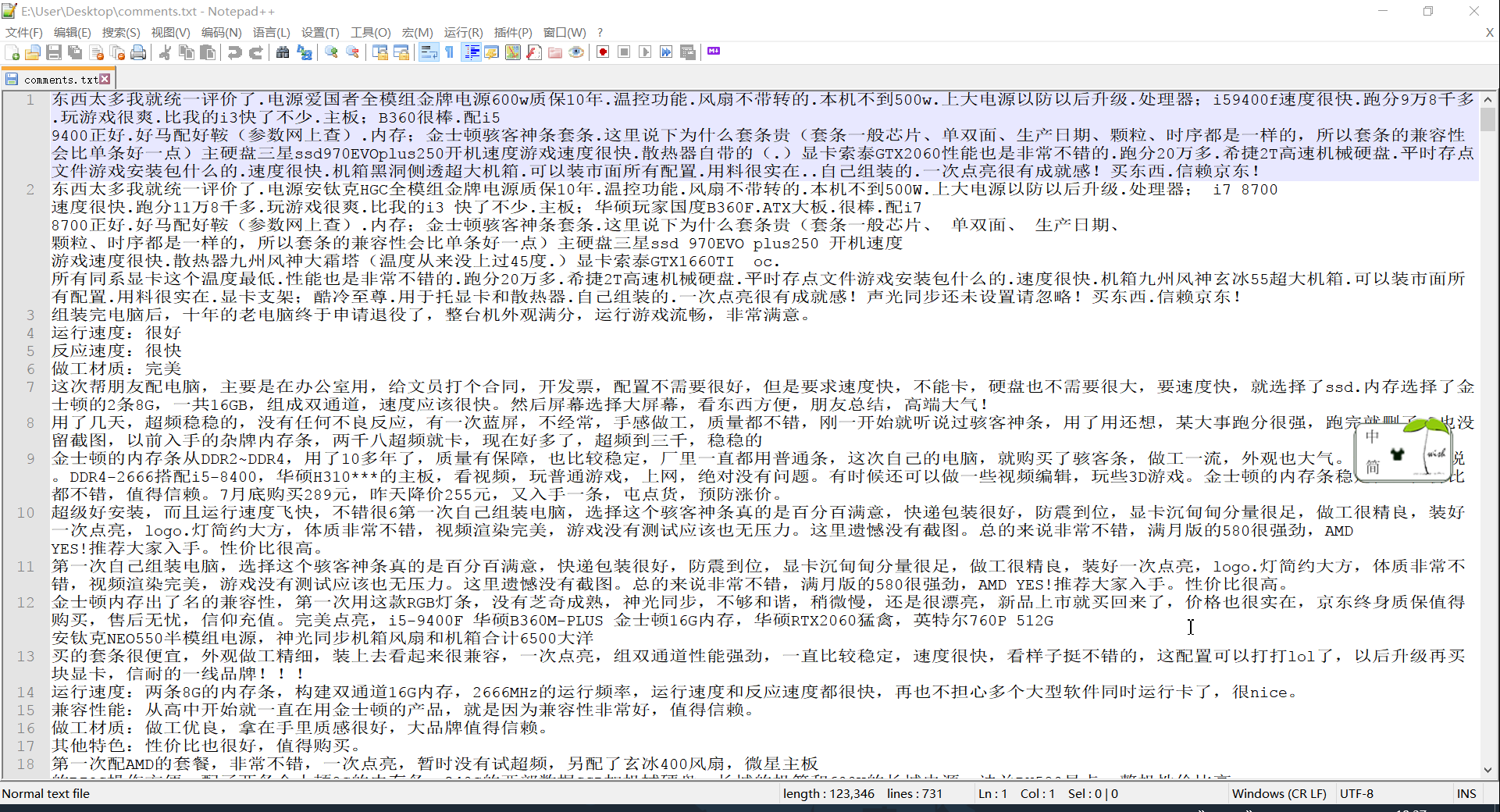
分词
分词这里使用hanLP,官方网站:http://hanlp.com/。官方文档:https://github.com/hankcs/HanLP/blob/master/README.md
引入依赖:
<dependency><groupId>com.hankcs</groupId><artifactId>hanlp</artifactId><version>portable-1.7.5</version></dependency>
这里我们不仅需要分词,还要筛选出所有的形容词和副词,因为一般根据形容词和副词可以看出消费者对这件商品的看法。查阅hanLP官方文档发现,我们可以使用NLP分词: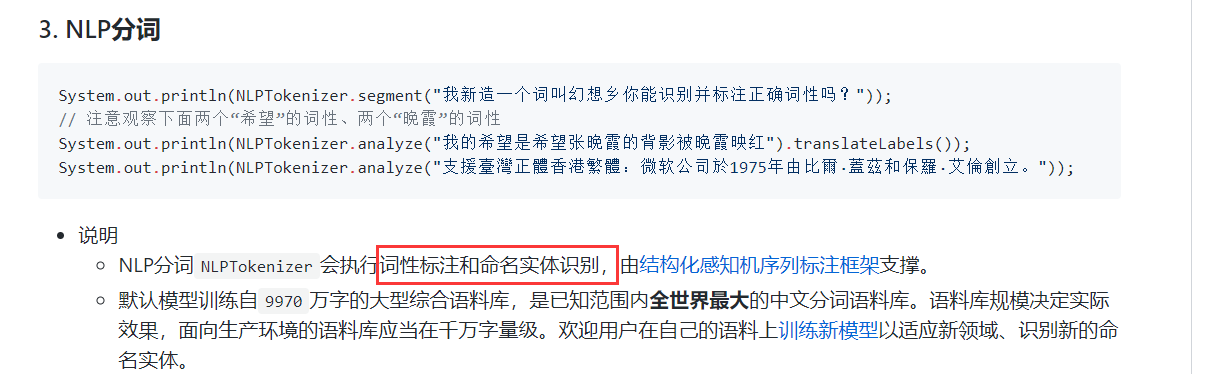
使用NLP分词之前我们需要先下载data,如下: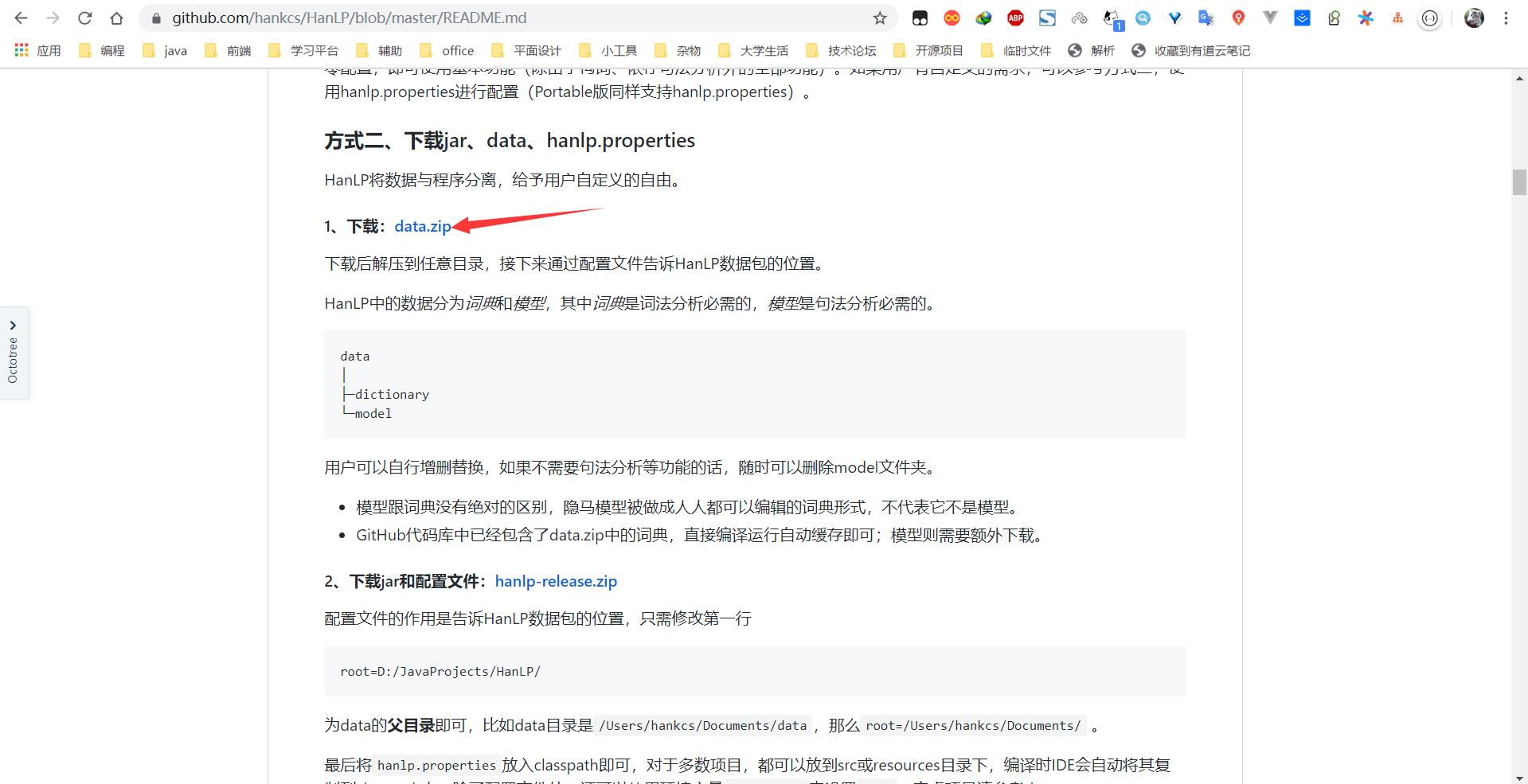
并且在resources下面新建hanlp.properties配置data所在目录,新建log4j.properties用于配置日志(可自行百度)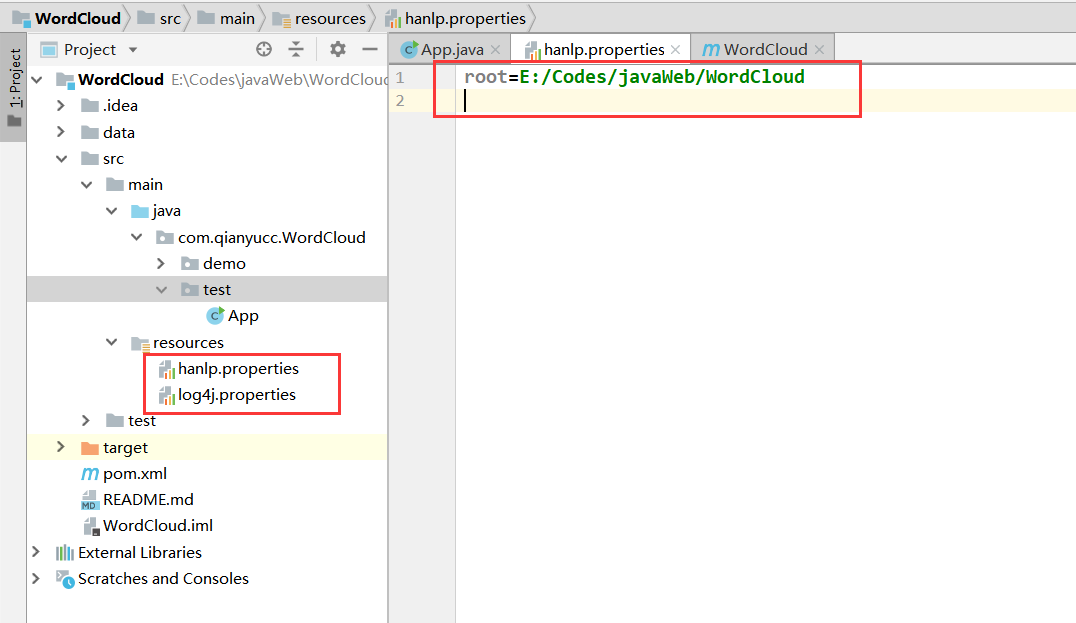
这个时候我们就可以分词并且进行统计了:
public static void main(String[] args) throws InterruptedException {List<String> comments = FileUtil.readLines("E:\\User\\Desktop\\comments.txt", Charset.defaultCharset());Map<String, Long> map = participle(comments);System.out.println(map);}private static Map<String, Long> participle(List<String> list) {Map<String, Long> map = list.stream().flatMap(string -> {Sentence analyze = NLPTokenizer.analyze(string);List<IWord> wordList = analyze.wordList;return wordList.stream().filter(word -> word.getLabel().contains("a")).map(word -> word.getValue());}).collect(Collectors.groupingBy(String::toString, Collectors.counting()));return map;}
代码中的
word.getLabel().contains("a")是找出所有词性中包含a的,分词之后,形容词的标签为a,副词为ad,这里实际上是找出所有的形容词和副词。
最后在collect操作中按照分词进行分组,并统计出分词出现的频率
运行结果:
生成词云
生成词云使用的是kumo,项目地址:https://github.com/kennycason/kumo
引入依赖
<dependency><groupId>com.kennycason</groupId><artifactId>kumo-core</artifactId><version>1.17</version></dependency><!-- 汉语支持 --><dependency><groupId>com.kennycason</groupId><artifactId>kumo-tokenizers</artifactId><version>1.17</version></dependency>
参考官方文档,如果分词和词频都是已知的,我们就可以自己构造List<WordFrequency>,上面我们已经进行了分词和词频的计算,所以这里采用这种方法。
kumo自带有中文分词分析器,如果使用kumo自带的分词的话可以不必使用hanLP,具体可以参考kumo的文档。这里使用hanLP主要有以下好处:1. 可以根据词性筛选出词语。2. 可以自定义筛选条件。3. 分词更加准确
public static void toImage(Map<String, Long> words, String filePath) {final List<WordFrequency> wordFrequencies = new ArrayList<>();// 构造List<WordFrequency>words.forEach((k, v) -> wordFrequencies.add(new WordFrequency(k, Math.toIntExact(v))));// 设置图片大小final Dimension dimension = new Dimension(600, 600);// 生成词云对象,设置图片大小,图像形状final WordCloud wordCloud = new WordCloud(dimension, CollisionMode.RECTANGLE);// 每个词语的边界wordCloud.setPadding(0);// 设置图片背景色wordCloud.setBackgroundColor(Color.WHITE);// 设置背景形状为方形wordCloud.setBackground(new RectangleBackground(dimension));// 设置词云显示的三种颜色,越靠前设置表示词频越高的词语的颜色wordCloud.setColorPalette(new ColorPalette(Color.RED, Color.GREEN, Color.YELLOW, Color.BLUE));// 字体标量:第一个参数为字体的最小值,第二个参数为字体的最大值wordCloud.setFontScalar(new LinearFontScalar(20, 100));// 设置一款中文字体wordCloud.setKumoFont(new KumoFont(new Font("华文新魏", 2, 20)));// 生成词云wordCloud.build(wordFrequencies);wordCloud.writeToFile(filePath);}
在main函数里面调用,即可生成词云:
public static void main(String[] args) throws InterruptedException {List<String> comments = FileUtil.readLines("E:\\User\\Desktop\\comments.txt", Charset.defaultCharset());Map<String, Long> map = participle(comments);toImage(map,"E:\\User\\Desktop\\WordCloud.png");}
生成的图片如下,我们可以看出大部分用户对其的评价都很不错:
完整代码
package com.qianyucc.WordCloud.test;import cn.hutool.core.io.*;import cn.hutool.core.util.*;import cn.hutool.http.*;import com.alibaba.fastjson.*;import com.hankcs.hanlp.corpus.document.sentence.*;import com.hankcs.hanlp.corpus.document.sentence.word.*;import com.hankcs.hanlp.tokenizer.*;import com.kennycason.kumo.*;import com.kennycason.kumo.bg.*;import com.kennycason.kumo.font.*;import com.kennycason.kumo.font.scale.*;import com.kennycason.kumo.palette.*;import java.awt.*;import java.nio.charset.*;import java.util.*;import java.util.List;import java.util.stream.*;/** * @author lijing * @date 2019-10-28 16:18 * @description 爬取评论,分词生成词云 */public class App {public static final String GET_COMMENTS_URL = "https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv347&productId=100007698730&score=0&sortType=5&page={}&pageSize=10&isShadowSku=0&fold=1";public static void main(String[] args) throws InterruptedException {for (int i = 0; i < 17; i++) {Thread.sleep(RandomUtil.randomInt(1000 * 2, 1000 * 5));List<String> comments = getComments(i);FileUtil.writeLines(comments, "E:\\User\\Desktop\\comments.txt", Charset.defaultCharset(), true);}List<String> comments = FileUtil.readLines("E:\\User\\Desktop\\comments.txt", Charset.defaultCharset());Map<String, Long> map = participle(comments);toImage(map, "E:\\User\\Desktop\\WordCloud.png");}public static void toImage(Map<String, Long> words, String filePath) {final List<WordFrequency> wordFrequencies = new ArrayList<>();// 构造List<WordFrequency>words.forEach((k, v) -> wordFrequencies.add(new WordFrequency(k, Math.toIntExact(v))));// 设置图片大小final Dimension dimension = new Dimension(600, 600);// 生成词云对象,设置图片大小,图像形状final WordCloud wordCloud = new WordCloud(dimension, CollisionMode.RECTANGLE);// 每个词语的边界wordCloud.setPadding(0);// 设置图片背景色wordCloud.setBackgroundColor(Color.WHITE);// 设置背景形状为方形wordCloud.setBackground(new RectangleBackground(dimension));// 设置词云显示的三种颜色,越靠前设置表示词频越高的词语的颜色wordCloud.setColorPalette(new ColorPalette(Color.RED, Color.GREEN, Color.YELLOW, Color.BLUE));// 字体标量:第一个参数为字体的最小值,第二个参数为字体的最大值wordCloud.setFontScalar(new LinearFontScalar(20, 100));// 设置一款中文字体wordCloud.setKumoFont(new KumoFont(new Font("华文新魏", 2, 20)));// 生成词云wordCloud.build(wordFrequencies);wordCloud.writeToFile(filePath);}private static Map<String, Long> participle(List<String> list) {Map<String, Long> map = list.stream().flatMap(string -> {Sentence analyze = NLPTokenizer.analyze(string);List<IWord> wordList = analyze.wordList;return wordList.stream().filter(word -> word.getLabel().contains("a")).map(word -> word.getValue());}).collect(Collectors.groupingBy(String::toString, Collectors.counting()));return map;}private static List<String> getComments(int page) {HttpRequest req = HttpUtil.createGet(StrUtil.format(GET_COMMENTS_URL, page));req.header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0");req.header("Referer", "https://item.jd.com/45194954688.html");String respJson = StrUtil.sub(req.execute().body(), 25, -2);JSONObject jsonObject = JSON.parseObject(respJson);JSONArray comments = jsonObject.getJSONArray("comments");ArrayList<String> list = new ArrayList<>();comments.forEach(comment -> list.add(((JSONObject) comment).get("content").toString()));return list;}}


































还没有评论,来说两句吧...