Flume - 故障转移、负载均衡
- 故障转移
概述:
故障转移机制的工作方式是将失败的sink放到一个池中,并在池中为它们分配一段冷冻期,在重试之前随着连续的失败而增加。一个sink成功发送event后,将其恢复到活动池。sink有一个与它们相关联的优先级,数字越大表示优先级越高。如果一个sink在发送event时失败,则下一个具有最高优先级的sink将被尝试用于发送事件。
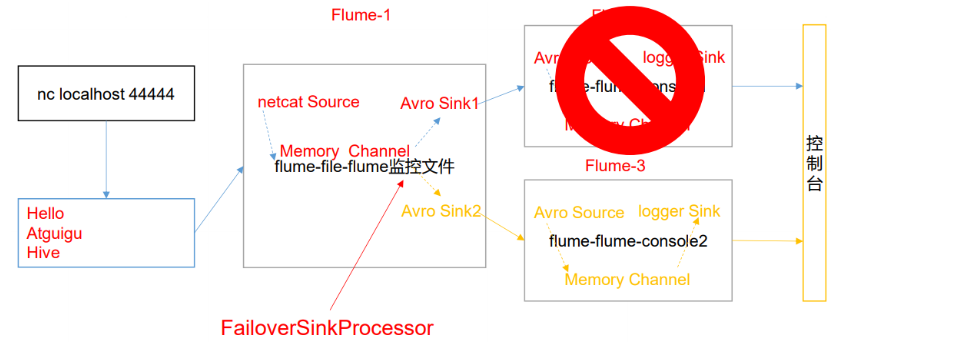
实例:
# hadoop105# Name the components on this agenta1.sources = r1a1.sinks = k1 k2a1.channels = c1a1.sinkgroups = g1# Describe/configure the sourcea1.sources.r1.type = netcata1.sources.r1.bind = localhosta1.sources.r1.port = 44444# Channela1.channels.c1.type = memorya1.channels.c1.capacity = 1000a1.channels.c1.transactionCapacity = 100# Sinka1.sinks.k1.type = avroa1.sinks.k1.hostname = hadoop106a1.sinks.k1.port = 4141a1.sinks.k2.type = avroa1.sinks.k2.hostname = hadoop107a1.sinks.k2.port = 4142#Sink Groupa1.sinkgroups.g1.sinks = k1 k2a1.sinkgroups.g1.processor.type = failovera1.sinkgroups.g1.processor.priority.k1 = 5a1.sinkgroups.g1.processor.priority.k2 = 10a1.sinkgroups.g1.processor.maxpenalty = 10000#Binda1.sources.r1.channels = c1a1.sinks.k1.channel = c1a1.sinks.k2.channel = c1----------------------------------------------------------------------# hadoop106#Namea2.sources = r1a2.channels = c1a2.sinks = k1#Sourcea2.sources.r1.type = avroa2.sources.r1.bind = hadoop106a2.sources.r1.port = 4141#Channela2.channels.c1.type = memorya2.channels.c1.capacity = 1000a2.channels.c1.transactionCapacity = 100#Sinka2.sinks.k1.type = logger#Binda2.sources.r1.channels = c1a2.sinks.k1.channel = c1----------------------------------------------------------------------# hadoop107#Namea3.sources = r1a3.channels = c1a3.sinks = k1#Sourcea3.sources.r1.type = avroa3.sources.r1.bind = hadoop107a3.sources.r1.port = 4142#Channela3.channels.c1.type = memorya3.channels.c1.capacity = 1000a3.channels.c1.transactionCapacity = 100#Sinka3.sinks.k1.type = logger#Binda3.sources.r1.channels = c1a3.sinks.k1.channel = c1
参考文章链接:
文章1:http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html
文章2:https://blog.51cto.com/jackwxh/1906893
- 负载均衡
概述:
source中的event流经channel,进入sink group,在sink group中根据负载算法(round_robin、random)选择sink,然后选择不同机器上的agent实现负载均衡。
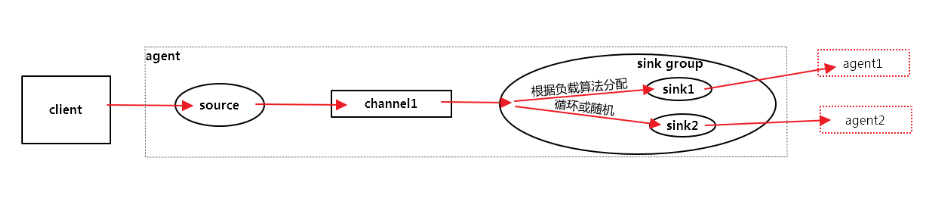
# hadoop105# Name the components on this agenta1.sources = r1a1.sinks = k1 k2a1.channels = c1a1.sinkgroups = g1# Describe/configure the sourcea1.sources.r1.type = netcata1.sources.r1.bind = localhosta1.sources.r1.port = 44444# Channela1.channels.c1.type = memorya1.channels.c1.capacity = 1000a1.channels.c1.transactionCapacity = 100# Sinka1.sinks.k1.type = avroa1.sinks.k1.hostname = hadoop106a1.sinks.k1.port = 4141a1.sinks.k2.type = avroa1.sinks.k2.hostname = hadoop107a1.sinks.k2.port = 4142#Sink Groupa1.sinkgroups.g1.sinks = k1 k2a1.sinkgroups.g1.processor.type = load_balancea1.sinkgroups.g1.processor.backoff = truea1.sinkgroups.g1.processor.selector = random#Binda1.sources.r1.channels = c1a1.sinks.k1.channel = c1a1.sinks.k2.channel = c1----------------------------------------------------------------------# hadoop106#Namea2.sources = r1a2.channels = c1a2.sinks = k1#Sourcea2.sources.r1.type = avroa2.sources.r1.bind = hadoop106a2.sources.r1.port = 4141#Channela2.channels.c1.type = memorya2.channels.c1.capacity = 1000a2.channels.c1.transactionCapacity = 100#Sinka2.sinks.k1.type = logger#Binda2.sources.r1.channels = c1a2.sinks.k1.channel = c1----------------------------------------------------------------------# hadoop107#Namea3.sources = r1a3.channels = c1a3.sinks = k1#Sourcea3.sources.r1.type = avroa3.sources.r1.bind = hadoop107a3.sources.r1.port = 4142#Channela3.channels.c1.type = memorya3.channels.c1.capacity = 1000a3.channels.c1.transactionCapacity = 100#Sinka3.sinks.k1.type = logger#Binda3.sources.r1.channels = c1a3.sinks.k1.channel = c1
参考文章地址:
文章1:http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html
文章2:https://blog.csdn.net/silentwolfyh/article/details/51165804




























——界面美化")




还没有评论,来说两句吧...