如何排查CPU占用过高的通用步骤
cpu占用过高是linux服务器常见的一种故障,对于这种问题其 实是有一些通用的步骤的,这里我将对于这种问题的排查方式做一下记录。
1、使用top命令找出linux服务器上运行cpu和内存最大的几个服务。
[root@localhost ~]# toptop - 03:01:38 up 11 days, 5:28, 3 users, load average: 1.56, 1.95, 2.03Tasks: 124 total, 1 running, 123 sleeping, 0 stopped, 0 zombie%Cpu(s): 24.5 us, 0.7 sy, 0.0 ni, 74.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 stKiB Mem : 997924 total, 67308 free, 752260 used, 178356 buff/cacheKiB Swap: 2097148 total, 1272032 free, 825116 used. 43900 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND32177 root 20 0 2153776 145292 1044 S 20.7 14.6 307:40.29 java57516 root 20 0 5022200 139800 2156 S 1.7 14.0 145:06.52 java49669 root 20 0 2375040 147820 3692 S 1.3 14.8 131:06.41 java9 root 20 0 0 0 0 S 0.3 0.0 5:05.53 rcu_sched47930 root 20 0 151464 2144 888 S 0.3 0.2 4:48.08 redis-server56884 root 20 0 950136 6156 1112 S 0.3 0.6 6:49.41 mongod118862 root 20 0 0 0 0 S 0.3 0.0 0:00.08 kworker/0:3
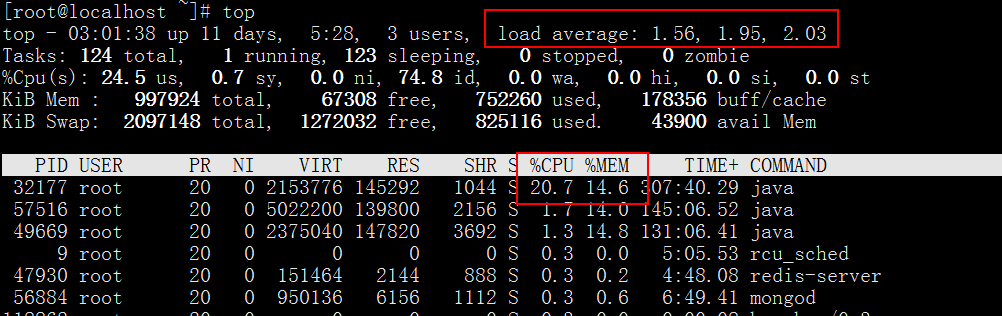
从图片上可以看到 load average 超过1都基本接近2了,但因为我虚拟机是单核的(单核处理器Load Average要小于1。同理,对于双核处理器来说,Load Average要小于2。以一个单核的机器为例,load=0.5表示CPU还有一半的资源可以处理其他的线程请求,load=1表示CPU所有的资源都在处理请求,没有剩余的资源可以利用了,而load=2则表示CPU已经超负荷运作,另外还有一倍的线程正在等待处理。),但我这个占用最大cpu和内存并不大,这是因为我使用的自己虚拟机装了很多其他应用,在正式环境的服务器,这种情况并不会出现,我们看到占用最高32177。
2、通过 ps -ef | grep 32177(pid) | grep -v grep 命令,查看运行的具体程序。
[root@localhost ~]# ps -ef | grep 32177 | grep -v greproot 32177 1 18 10月07 ? 05:07:53 /usr/local/jdk1.8.0_181/bin/java -server -Xms64m -Xmx64m -Xmn48m -Xss256K -XX:SurvivorRatio=4 -XX:+UseConcMarkSweepGC-XX:+UseCMSCompactAtFullCollection-XX:CMSInitiatingOccupancyFraction=60 -XX:+PrintGCDateStamps -XX:+PrintGCDetails -Xloggc:./gc.log -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=9998 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=192.168.25.128 -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=65532 -jar lib/database-project-0.0.1-SNAPSHOT.jar
3、通过 ps -mp 32177(pid) -o THREAD,tid,time,查看消耗资源
具体的线程ID
[root@localhost ~]# ps -mp 32177 -o THREAD,tid,timeUSER %CPU PRI SCNT WCHAN USER SYSTEM TID TIMEroot 18.6 - - - - - - 05:31:53root 0.0 19 - futex_ - - 32177 00:00:00root 0.0 19 - futex_ - - 32180 00:00:08root 0.0 19 - futex_ - - 32181 00:00:00root 17.4 19 - futex_ - - 32182 05:09:24
可以查看到线程为32182 占用比例比较高。
4、这里看tid是10进制,如果通过jstack去查看具体线程需要16进制,可以通过linux命令直接转化,同样可以使用计算器。这里用printf “%x\n” 32182 ,查看32182的16进制为 7db6
[root@localhost ~]# printf "%x\n" 321827db6
5、通过jstack命令,查看具体线程运行情况。(我这里由于不止安装了一个jdk,故指定使用jstack的具体位置使用)
/usr/local/jdk1.8.0_181/bin/jstack 32177(pid) | grep 7db6(转化为16进制的tid) -A60
[root@localhost ~]# /usr/local/jdk1.8.0_181/bin/jstack 32177 | grep 7db6 -A60"Concurrent Mark-Sweep GC Thread" os_prio=0 tid=0x00007fdeec040800 nid=0x7db6 runnable"VM Periodic Task Thread" os_prio=0 tid=0x00007fdeec26e000 nid=0x7dc6 waiting on conditionJNI global references: 8528
从上面可以 运行主要成效是gc回收占用cpu(这里是因为我将程序运行的堆设置比较小),如果有其他问题也能通过查看不同tid找到造成程序运行占用内存大具体线程。
6、这里通过jstat 命令查看各个内存的使用情况
jstat -gc 32177(pid) 2000(2s一次) 10(共计10次),这个命令可以将各个区使用内存大小展示出来
jstat -gc 32177 2000 10S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT8192.0 8192.0 0.0 3876.8 32768.0 24340.5 16384.0 12837.4 51096.0 48839.8 6552.0 6069.7 25 1.093 32126 1736.406 1737.4998192.0 8192.0 0.0 3876.8 32768.0 24340.5 16384.0 12837.4 51096.0 48839.8 6552.0 6069.7 25 1.093 32127 1736.438 1737.5308192.0 8192.0 0.0 3876.8 32768.0 24340.5 16384.0 12837.4 51096.0 48839.8 6552.0 6069.7 25 1.093 32127 1736.438 1737.530
jstat -gcutil 32177(pid) 2000(2s一次) 10(共计10次),这个命令将各个区使用占比展示,能够更好分析
jstat -gcutil 32177 2000 10S0 S1 E O M CCS YGC YGCT FGC FGCT GCT0.00 47.32 74.72 78.35 95.58 92.64 25 1.093 32193 1739.631 1740.7240.00 47.32 74.72 78.35 95.58 92.64 25 1.093 32194 1739.686 1740.7790.00 47.32 74.72 78.35 95.58 92.64 25 1.093 32195 1739.686 1740.779

年轻代回收次数远远小于Full回收的次数,在加上jstat -gc 32177 2000 10 这个命令查看老年代与年轻代之间比例,并没有不太合理。那就两种情况,第一种程序中有代码一直加载着数据不能够释放,要么就是整个堆内存设置空间大小太小。我这里是第二种情况,如果是第一种情况ps -mp 32177 -o THREAD,tid,time 查看运行空间的时候,不会只有一个线程占用内存较大。
我们也可以通过jstack 32177 >>jstack.out这个命令查看将所有线程放到jstack.out查看正在运行的线程,是否有不合理地方。
[root@localhost ~]# jstack 32177 >>jstack.out[root@localhost ~]# lsanaconda-ks2.cfg anaconda-ks.cfg jstack.out logs store target




























")





还没有评论,来说两句吧...