史上最全的C++/游戏开发面试问题总结(三)—— 操作系统上篇

最近有朋友问我这个系列为什么不更新了?
实不相瞒,一是自己没那么勤快,二是因为确实没整理好后面的内容。其实我在总结这些知识点的同时也在自己学习,想趁着这个机会好好补一下自己的理论基础。写操作系统这章的时候脑中经常闪过一些其他的之前没有理解透彻的问题,然后又开始添加新的问题,查阅、学习,不知不觉一篇文章就写了个一两万字(所以分了上下篇)。
有些问题确实挺不好理解的,记得有一天刷知乎,一个关于“同步、异步、阻塞、非阻塞”的问题我楞是看了一个小时都没完全搞懂,后来过了一阵重新学习(又咨询了几个大佬)才恍然大悟。如果你发现文章里有问题不理解或者有误,可以在公众号给我留言(微信不开放评论我真的很无奈),也可以关注我的知乎账号私信我。
下面的问题总的来说参考的书籍有:《Operating Systems: Internals and Design Principles》《操作系统的设计与实现》《现代操作系统》《深入理解计算机系统》《Windows核心编程》《深入理解Linux内核》
如果没有时间的话,没有必要都看,可以根据目录找你关注的问题,回复“操作系统”可以获取这些电子书。如果觉得文章有价值,希望能帮我分享一下~
问:谈谈对线程与进程的理解(提问概率:★★★★★)
首先说说基本概念,即进程是系统资源分配的基本单位,线程是CPU运算调度的基本单位。
进程:具体一点来讲,进程是装入内存运行的程序段,是许多可运行代码段以及系统资源的集合。再贴切一点,进程是程序对系统数据资源进行处理操作的一次活动,我们平时用Windows打开任务管理器展示的都是一个个进程,他们在运行时常驻在内存里面根据程序的设计来调用与操作系统的资源与数据。(每个进程对应一个内核空间与用户空间,这是虚拟内存。内核空间的地址是固定的,进程通过虚拟内存映射到上面,内核空间内容不受用户控制,但是会通过系统调用改变其内部状态。)之所以要用进程,是因为想要更好的实现多道程序设计技术(即多个相互独立的程序在内存中同时存放, 相互穿插运行, 宏观并行, 微观串行,现代PC操作系统都是采用这种技术,即分时操作系统),需要一个能对多个运行中的程序进行控制的实体,这个实体就是进程。进程在运行时会占用内存空间,一般分为内核空间与用户空间,内核空间包括进程的控制信.息、内核栈、内核代码等内容,用户空间则是常见的堆、栈、常量区数据等。用户对进程进行输入时进程都处于用户态,当进程执行某些系统调用的时候才会切换到内核态,才能操作内核空间,调用完成后进程又会切回到用户态。
线程:在进程刚出现时还没有线程的概念,那时候进程其实也是执行CPU运算调度的基本单位,但是由于进程的创建成本与通信成本太高,才有线程的诞生。线程必须被包含在进程中,一个进程可以有很多线程(至少有一个作为主线程),这些线程有自己的资源(如栈,寄存器)也共享进程的许多资源。我们通常写的Main函数可以简单理解为一个进程的代码段,但是进一步来讲,其实他是该进程中主线程的代码段,每一个线程被创建时都会自动的分配栈资源、寄存器数据,这些数据只有该线程能访问,其寄存器的数据是保存在内核空间当中的。如果从主线程调用malloc等函数来申请堆内的空间,这个空间就不是自己所有的了,其他线程也可以访问的,因为他们同属同一个进程,因此同一进程内的线程可以方便的进行数据通信。
参考资料:
https://my.oschina.net/cnyinlinux/blog/367910
https://www.cnblogs.com/wuchanming/p/4465188.html
http://blog.chinaunix.net/uid-20476365-id-1942504.html
http://www.blogjava.net/bacoo/archive/2008/11/20/241586.html
http://www.cnblogs.com/clover-toeic/p/3754433.html
https://www.zhihu.com/question/23561375/answer/136131995
问:谈谈多线程的意义(提问概率:★★★★)
简单总结就是两个词,并行与并发。所谓并发,就是多个任务流宏观上同时执行,实际微观上是顺序轮流执行,并发的概念产生的比较早,我们的分时操作系统就是基于这个原理。并行,是指多个任务真正的在多个处理器上面同时运行。
单核:对于单核来说,多线程的执行就是并发,这时候开启多线程也是有意义的。首先大部分任务都不可能是完全CPU密集的,中间肯定穿插着很多IO操作,IO阻塞会造成整个程序被阻塞。比如,一个简单的单线程网络游戏程序,当我们接收Socket数据的时候由于阻塞问题可能导致我们的游戏的其他逻辑都被影响,效果就是没有响应。如果另开一个线程处理socket,如果他阻塞了就会切换到游戏主线程,不影响游戏逻辑。第二,执行时间长的任务会影响带有GUI程序的用户体验。比如,我们写一个GUI程序,并在里面放了一个压缩数据的任务,如果压缩数据执行的时间比较长,GUI界面就会被阻塞而无响应。如果开一个线程单独处理压缩,就会解决这个问题。第三点,有时候有的逻辑与程序的主要逻辑没什么必要关系,单独开一个线程执行代码写起来比较方便。(不过这个不算重点)
多核:对于多核来说,更在意并行,就是为了充分利用多个CPU的计算能力。前面提到了GUI与压缩任务,如果是单核机器,那么其实是GUI线程与压缩任务线程按时间片轮流执行,本质上并没有提高程序的运算效率(特别是对于压缩任务),反而由于多线程的频繁切换还可能增加了一定开销。如果这时候有多个CPU,就可能出现CPU1执行GUI逻辑的时候,CPU2处理压缩任务,达到了真正的并行(属于一个进程下的多个线程在多个核心上跑,也可以单开一个压缩任务进程,该进程有一个压缩任务主线程),很明显这样的效率比单核要高。另外,单核多线程里面的优点对于多核一样有意义。
关于多线程、多核、多进程的关系还需要大家多查查资料,多思考一下。
参考资料:
https://www.zhihu.com/question/19901763/answer/13299543
https://www.zhihu.com/question/31683094
https://bbs.csdn.net/wap/topics/270083226
https://bbs.csdn.net/topics/280070774/
问:谈谈对操作系统的理解,简单说说Windows与Linux有什么异同(提问概率:★★★★★)
目的是管理计算机的硬件与软件资源,一般都包括进程管理,文件系统,内存管理系统,I/O管理几个大模块
相同:以文件系统来组织操作系统(但具体来说差别也不小),所有操作都交给进程去处理,操作的切换核心是中断
不同:使用上看,windows代码不公开针对大众以图形化为特点,安全性差一些,系统资源占有比较高;linux开源兼容性好,稳定性相当高,针对开发人员可以多个用户同时操作操作系统,广泛用于服务器与嵌入式,以命令行为主。Windows创建进程用createProcess,Linux创建进程用Fork(fork快速复制父进程创建子进程,想要单独开辟空间用exevc)。Linux内核没有明确的线程概念在内核是通过轻量级进程来关联用户态的“线程”,这些进程可以像线程一样共享一些资源,Windows上进程与线程有明确的区分以及对应的数据结构。因为开源,Linux可以根据你的选择编译不同的内核,Linux系统也因此有很多拓展的操作系统,如Ubuntu,CentOS
参考资料:
https://www.zhihu.com/question/21135526
https://zh.wikibooks.org/zh-hans/Ubuntu/Linux%E4%B8%8EWindows%E7%9A%84%E5%8C%BA%E5%88%AB
https://www.zhihu.com/question/20438885
http://mtoou.info/linux-windows-duibi/index.html
https://zh.wikipedia.org/wiki/%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F
https://blog.csdn.net/gatieme/article/details/51481863
问:如何理解内核态与用户态(提问概率:★★★★)
在现在操作系统中,内存分为内核空间与用户空间,内核功能模块运行在内核空间,而应用程序运行在用户空间。现代的CPU都具有不同的操作模式,代表不同的级别,不同的级别具有不同的功能,其所拥有的资源也不同,在较低的级别中将禁止使用某些处理器的资源。很多操作系统设计时都利用了这种硬件特性,使用了两个级别,最高级别和最低级别,内核运行在最高级别(内核态),这个级别几乎可以使用处理器的所有资源,而应用程序运行在较低级别(用户态),在这个级别的用户不能对硬件进行直接访问以及对内存的非授权访问。内核态和用户态有自己的内存映射,即自己的地址空间。
当工作在用户态的进程想访问某些内核才能访问的资源时,必须通过系统调用或者中断切换到内核态,由内核代替其执行。进程上下文和中断上下文就是完成这两种状态切换所进行的操作总称。我将其理解为保存用户空间状态是上文,切换后在内核态执行的程序是下文。
参考资料:
https://www.zhihu.com/question/46540636
https://www.zhihu.com/question/23561375
https://www.cnblogs.com/bakari/p/5520860.html
https://www.cnblogs.com/vampirem/p/3157612.html
https://blog.csdn.net/gatieme/article/details/50779184
问:什么是进程上下文,中断上下文(提问概率:★★★)
进程上下文:是指进程由用户态切换到内核态是需要保存用户态时cpu寄存器中的值,进程状态以及堆栈上的内容,以便再次执行该进程时,能够恢复切换时的状态,继续执行,进程上下文的信息保存在PCB里面。一般来说,进程上下文主要是异常处理程序和内核线程。内核之所以进入进程上下文是因为进程自身的一些工作需要在内核中做。例如,系统调用是为当前进程服务的,异常通常是处理进程导致的错误状态等。
中断上下文:硬件通过中断触发信号,导致内核调用中断处理程序,进入内核空间。这个过程中,硬件的一些变量和参数也要传递给内核,内核通过这些参数进行中断处理。中断上文可以看作就是硬件传递过来的这些参数和内核需要保存的一些其他环境(主要是当前被中断的进程环境。
问:并行与并发(提问概率:★★★★)
并行是多个任务在严格同时运行,即在多个CPU核上面运行。
并发是多个任务宏观同时运行,微观顺序串行运行,即在一个核上面分时间片轮流执行。
问:协程coroutines、纤程Fiber(提问概率:★★★)
提到协程,我们最常见的描述就是,协程是用户态下的轻量级线程。不过这句话不足以阐述他的特性,我从下面几个方面来描述一下。
1.我们知道线程的出现是为了减小进程的切换开销,提高多核的利用率。当程序运行到某个IO发送阻塞的时候,可以切换到其他线程去执行,这样不会浪费CPU时间。而线程的切换完全是通过操作系统去完成的,切换的时候一般会通过系统点用从用户态切换到内核态。这段话的重点是,线程是内核态的。
2.我们常见的代码逻辑都是被封装在一个个函数块里面。每次传递一个参数,这个函数就会从头到尾执行一遍,有对应的输出。如果在执行的过程中,发生了线程的抢占切换,那么当前线程就会保存函数当前的上下文信息(放到寄存器里面),去执行其他线程的逻辑。当这个线程重新执行时会根据之前保存的上下文信息继续执行。这段话的重点是,线程的切换需要保存函数的上下文信息。
3.而且现代操作系统一般都是抢占式的,所以多个线程在执行的时候在什么时候切换我们是无法控制的。所以,多线程编程时为了保证数据的准确性与安全性,我们经常需要加锁。这段话的重点是,线程的执行顺序我们无法控制,什么时候切换我们也几乎无法控制。
4.由于线程在运行时经常会由于IO阻塞(或者时钟阻塞)而放弃CPU,会导致我们的逻辑不能流畅的执行下去。所以,我们一般采用异步+回调的方式去执行代码。当线程与到阻塞时直接返回,继续执行下面的逻辑。同时注册一个回调函数,当内核数据准备好了之后再通知我们。这种写代码的方式其实不够直观,因为我们一般都习惯顺序执行的逻辑,一段代码能从头跑到尾那是再理想不过了。这段话的重点是,涉及到IO阻塞的多线程编程时,我们一般用异步+回调的方式来解决问题。
了解了上面的内容,我们就可以开始继续学习协程了。
1.协程是用户态的,他是包含在线程里面的,简答来说你可以认为一个线程可以按照你的规则把自己的时间片分给多个协程去执行。
2.因为一个线程里面可能有多个协程,所以协程的执行需要切换,切换就需要保存当前的上下文信息(一组寄存器和调用堆栈,保存在自身的用户空间内),这样才能在再次执行的时候继续前面的工作。相比线程,协程要保存的东西都很少。
3.相比线程,协程的切换时机是可以控制的。我们可以告诉协程,代码执行到哪句的时候切换到哪个协程,这样就可以避免线程执行不确定性带来的安全问题,避免了各种锁机制带来的相关问题。
4.协程的代码看起来是同步的,不需要回调。比如说有两个协程,A协程执行到第3句就一定会切换到B协程的第4句,假如A与B里面都有循环,那展开来看其实就是A与B函数不断的顺序执行。这种感觉有点像并发,同样在一个线程上的A与B不断的切换去执行逻辑。
5.协程不过是一种用户级别的实现手段,他并不像线程那样有明确的概念与实体,更像是一个语言技巧。他的切换开销小。
这里再拿一个网上廖雪峰老师的例子,
简单来说就是生产者消费者问题:通过无限循环生产者不断生成数据,消费者不断取数据。如果是线程,我们要保证消费者取数据的时候有生产者产生的数据,所以要通过信号量等方式去保证这一点(需要加锁)。而协程不需要,一定是等到生产者生产数据后,再通过某些关键字(yield)通知消费者取数据,这样就避免了线程同步问题。
import timedef consumer():r = ''while True:n = yield rif not n:returnprint('\[CONSUMER\] Consuming %s...' % n)time.sleep(1)r = '200 OK'def produce(c):c.next()n = 0while n < 5:n = n + 1print('\[PRODUCER\] Producing %s...' % n)r = c.send(n)print('\[PRODUCER\] Consumer return: %s' % r)c.close()if \_\_name\_\_=='\_\_main\_\_':c = consumer()produce(c)执行结果:\[PRODUCER\] Producing 1...\[CONSUMER\] Consuming 1...\[PRODUCER\] Consumer return: 200 OK\[PRODUCER\] Producing 2...\[CONSUMER\] Consuming 2...\[PRODUCER\] Consumer return: 200 OK\[PRODUCER\] Producing 3...\[CONSUMER\] Consuming 3...\[PRODUCER\] Consumer return: 200 OK\[PRODUCER\] Producing 4...\[CONSUMER\] Consuming 4...\[PRODUCER\] Consumer return: 200 OK\[PRODUCER\] Producing 5...\[CONSUMER\] Consuming 5...\[PRODUCER\] Consumer return: 200 OK
纤程可以认为是协程在Windows上的实现,不同语言对协程与纤程的叫法也不同,不过大体上是一个东西。
另外,现在很多语言里面的协程可能包含一些与异步、事件、IO多路复用相关的驱动机制,所以会有一些新的特性,这里讨论的不是这种“包装”过的协程。
参考资料与链接:
《深入理解计算机系统》《Windows 核心编程》《计算机操作系统》《操作系统概念》《计算机程序设计艺术(第1卷)》
https://zh.wikipedia.org/wiki/%E5%8D%8F%E7%A8%8B
https://www.zhihu.com/question/20511233/answer/347651080 协程的好处有哪些? - Jakit的回答 - 知乎
https://www.zhihu.com/question/20511233
https://zhuanlan.zhihu.com/p/27519705
https://www.sohu.com/a/237171690\_465221
https://www.zhihu.com/question/32218874
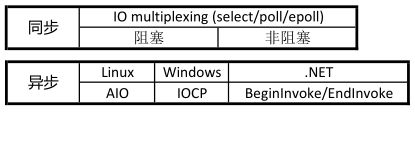
问:同步与异步,阻塞与非阻塞(提问概率:★★★★★)
同步与异步
主要指消息通信的机制。
同步:一个函数在调用的时候,没有得到结果的情况下就不会返回。(如IO多路复用的Select、Poll、epoll,后面说)
异步:一个函数在调用的时候,都会立刻返回,没有返回结果,被调用者通过状态、通知、回调函数处理这个调用(如AIO、IOCP后面说)
阻塞非阻塞
主要是针对线程(或者说进程)的状态。(先给出一个简单但不完全准确的理解)
阻塞就是线程(进程)停止执行,保存上下文,把cpu让出去,等待回调唤醒,但是后续逻辑不会执行。
非阻塞就是线程在遇到不能立刻返回结果的情况(如发送缓冲区满了、临界区)时就立刻返回,让该线程可以继续执行其他任务,不会把CPU让出去,不会影响后面的执行逻辑。
关于阻塞的进一步理解:
阻塞的原因往往不是线程本身的原因,而且他想获取CPU以外的资源(如内存)时,发现这个资源目前获取不到(如内核迟迟不给他想要的信息),只能自己休息,等待资源到来再去执行。
从用户的角度来看,阻塞确实就是把cpu让出去,等待回调唤醒。但是从操作系统来看,比如当我们执行某些系统调用的时候(如select),该线程只是表现是阻塞的,其实select会继续执行这个系统调用的相关工作(做一些与内核数据相关的内容等),CPU也并没有让出去。
关于Socket编程中的阻塞与非阻塞
Socket的发送与接收可以在编码时手动设置阻塞或者非阻塞。当我们用默认的阻塞方式发送socket数据时,操作系统里面会有一个内核缓冲区(属于内核区),当缓冲区满的时候你想要通过socket发送,当前的线程就会阻塞,因为你要等待他缓存区有位置才能添加到缓存区里面(如果这个sendto是在主线程调用,那么主线程就会阻塞,表现效果就是界面无响应),直到缓冲区发送出去清空后才会恢复。
对于这个问题一般有3种解决方案:
1.多线程 socket发送单独开放一个或多个线程,这样即使线程阻塞也不会影响主线程逻辑。
2.I/O多路复用 (select,poll,epoll) 虽然也可能会阻塞,但是由于可以监控多个socket,可以很大程度缓解这个问题
3.异步I/O 如Windows上的IOCP,发出调用立刻返回,等待事件回调,不会出现阻塞问题
参考资料与链接:
https://segmentfault.com/a/1190000003063859
(强烈建议先阅读这个,然后看后面两个解答)
https://www.zhihu.com/question/19732473/answer/20851256 怎样理解阻塞非阻塞与同步异步的区别? - 严肃的回答 - 知乎https://www.zhihu.com/question/19732473/answer/88599695 怎样理解阻塞非阻塞与同步异步的区别? - 银月游侠的回答 - 知乎
问:select poll epoll了解么,简单谈谈(提问概率:★★★★★)
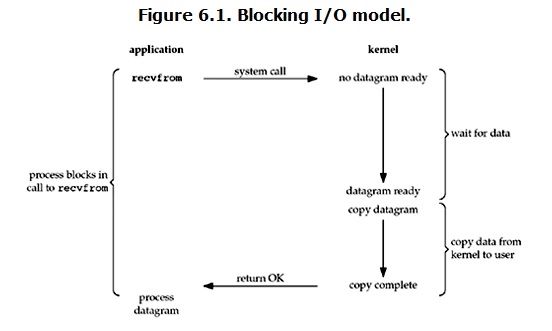
对于一次IO(输入输出,操作系统数据交换以及人机交互)访问(以read举例),数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的缓冲区,最后交给进程。
这个过程中,由于操作系统需要做一些准备与处理的工作,所以需要对于的解决方案,因此诞生了5中IO模型,
-- 阻塞 I/O(blocking IO)
-- 非阻塞 I/O(nonblocking IO)
-- I/O 多路复用( IO multiplexing)
-- 信号驱动 I/O( signal driven IO)
-- 异步 I/O(asynchronous IO)
阻塞非阻塞前面大概有了解,具体参考下面给出链接的讲解。这里要简单说一下IO多路复用,I/O多路复用就通过一种机制,可以监视多个描述符,一旦某个描述符(即fd)就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作,他可以比较好的解决I/O的阻塞问题。select,poll,epoll都是IO多路复用的机制,他们本质上都是同步I/O。
select:
select本质上是通过设置或者检查存放fd标志位的数据结构来进行下一步处理。主要的问题有每次调用都需要将fd数组从用户态拷贝到内核态;它仅仅知道有I/O事件发生了,却并不知道是哪那几个流,只能无差别轮询所有流,找出能读出数据,或者写入数据的流,对他们进行操作;而且,Select支持的文件描述符太少,一般32位系统为1024个,虽然可以通过FDSET宏修改,但是fd太多效率会明显降低。优势就是良好的跨平台性,几乎所有的平台都支持select,对于链接数量较少的情况表现还是不错的。
poll:
poll本质上和select没有区别,它也是将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态,如果设备就绪则在设备等待队列中加入一项并继续遍历,如果遍历完所有fd后没有发现就绪设备,则挂起当前进程,直到设备就绪或者主动超时,被唤醒后它又要再次遍历fd。相比Select他没有它没有最大连接数的限制(它是基于链表来存储的),不过大量的fd的数组被整体复制于用户态和内核地址空间之间,很多复制是没意义的。
epoll:
(epoll_create;epoll_ctl;epoll_wait)
epoll的API有三个,可以良好的解决select与Poll的缺点。由于他可以在内核里面通过红黑树记录所有的socket,所以不需要每次调用都从头复制一遍(一般情况下,并发量远远小于实际链接数,从内核拷贝到用户的缓冲数据也并不是很多)。同时由于给socket句柄注册一个中断回调函数,所以不需要主动遍历。另外,epoll没有fd数量限制,它所支持的FD上限是最大可以打开文件的数目。
epoll有EPOLLLT和EPOLLET两种触发模式,LT是默认的模式,ET是“高速”模式,只支持非阻塞Socket。LT模式下,只要这个fd还有数据可读,每次 epoll_wait都会返回它的事件,提醒用户程序去操作,而在ET(边缘触发)模式中,它只会提示一次,直到下次再有数据流入之前都不会再提示了,无 论fd中是否还有数据可读。所以在ET模式下,read一个fd的时候一定要把它的buffer读光,也就是说一直读到read的返回值小于请求值,或者 遇到EAGAIN错误。epoll链接上限非常大(10万左右),不会随着fd的增加而降低效率,内存复制上开销也比较小
表面上看epoll的性能最好,但是在连接数少并且连接都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调。
看到这里大家可能还有疑问:IO多路复用到底是不是阻塞的?
你可以认为他是阻塞,也可以认为是非阻塞,这个是根据Socket的设置来说的。当Select等调用返回时,他会通知你哪个Socket已经就绪,随后你还要自己去执行读取操作,这个过程中会将内核缓冲区的数据拷贝到用户区,所以仍然可能有阻塞(假如你Socket设置的是阻塞模式)的情况。
另外,当你调用Select的时候,其实是一个系统调用。调用的过程会通过中断进入到内核状态,然后内核进行相关处理,所以从用户的角度来看你的当前线程也是阻塞的(虽然这个线程在内核状态中工作),你只能等调用结束。
总的来说,并不能直接下定论说I/O多路复用是不是阻塞的,他们并不是一个层级的概念。
参考资料与链接:
https://www.ibm.com/developerworks/cn/linux/l-cn-edntwk/index.html?ca=drs-
https://blog.csdn.net/jiange\_zh/article/details/50811553
https://www.cnblogs.com/skyfsm/p/7079458.html
https://www.cnblogs.com/zingp/p/6863170.html
http://www.cnblogs.com/Anker/p/3265058.html
https://www.cnblogs.com/zhaodahai/p/6831456.html
问:挂起(Suspend),睡眠(sleep、Wait),阻塞(Block)(提问概率:★★★)
挂起是一种主动行为,因此恢复也应该要主动完成。
睡眠也是一个主动行为,不过因为有设置睡眠时间,所以不需要主动恢复。
而阻塞是一种被动行为(或者说是一个状态),是在等待事件或者资源任务的表现,你不知道它什么时候被阻塞,也不清楚它什么时候会恢复阻塞。
挂起不释放CPU,如果任务优先级高,就永远轮不到其他任务运行。一般挂起用于程序调试中的条件中断,当出现某个条件的情况下挂起,然后进行单步调试。
睡眠中的Sleep也不释放CPU与锁,而Wait会释放CPU与锁。
阻塞就是会释放CPU,其他任务可以运行,一般在等待某种资源或者信号量的时候出现。
问:AIO,IOCP有了解么?(提问概率:★)
假如面试官前面的问题里提到了同步I/O,那么很有可能继续问一下异步I/O。对于大部分应届生而言,异步I/O没有用过也没关系,能说多少就说多少。如果你有相关的经验,那理解的肯定会比我深刻,这里就简单说说。
IOCP:是仅存在Windows上的真正的异步通信模型,他会在内核中帮我们监听那些我们关注的IO事件。假如我们希望接收客户端数据,我们向完成端口发起一个读IO的事件,调用会立刻返回,我们可以继续做其他的事情。而完成端口在监测有读事件到来的时候会主动地去帮我们把数据从内核区复制到用户区,然后通知我们过来取数据。可以看出,IOCP可以说是目前最完美的I/O模型,他连数据的复制都帮我们做了。
简单总结来说,IOCP本质上就是把用户的投递事件放到一个IO消息队列里面,等待系统处理。同时,创建一个线程池开N个线程去接收处理IO完成对应的回调。
AIO:属于Linux上的异步IO,有多个实现版本。Glibc AIO采用多线程模拟,但存在一些bug和设计上的不合理。Kernel AIO是真正的内核异步,目前nginx有添加AIO,但它同样有一些问题。libev的作者后来也写了一个libeio,优化了前两个IO的部分问题。总的来说,Linux 上目前没有像 IOCP 这样的成熟异步 IO 实现。
参考资料与链接:
https://www.cnblogs.com/persistentsnail/p/3862433.html
https://blog.csdn.net/analogous\_love/article/details/74531514
http://gamebabyrocksun.blog.163.com/blog/static/57153463201036104134250/

游戏开发那些事
回复”gamebook”,获取游戏开发书籍
回复”C++面试”,获取C++/游戏面试经验
回复”游戏开发入门”,获取游戏开发入门文章
回复”操作系统”,获取操作系统相关书籍
长按二维码关注我


























. fatal: Could not read from remote repository")







还没有评论,来说两句吧...