SQL (九)分组数据(group by子句, having子句)
group by子句和having子句都是select子句
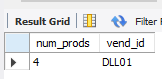
返回供应商DLL01的总产品数
select count(*) as num_prods, vend_idfrom productswhere vend_id = 'DLL01';
用分组把数据分为多个逻辑组,对每个组进行聚集计算
创建分组:select语句的group by子句

select vend_id, count(*) as num_prodsfrom productsgroup by vend_id;
group by指示DBMS按照vend_id分组数据,然后对每个组再聚集计算。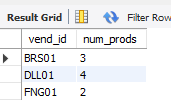
注意不用group by会报错:
select vend_id, count(*) as num_prodsfrom products;
过滤分组:having子句

厉害了,
- having子句非常类似于where子句,目前学过的所有类型的where子句都可以用having替代
- having也是过滤,但是过滤的是分组,而where过滤的是行


示例1
select cust_id, count(*) as ordersfrom ordersgroup by cust_idhaving count(*) >=2;
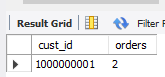
如果没有having子句,则输出如下,所以having子句确实过滤了3个分组。这里的过滤是基于分组聚集值,而不是特定行的值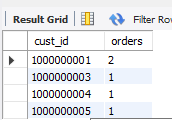
示例2:having和where一起用
select vend_id, count(*) as num_prodsfrom productswhere prod_price >= 4group by vend_idhaving count(*) >= 2;
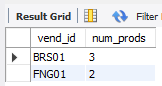
看看供应商和价格情况
select vend_id, prod_pricefrom products;
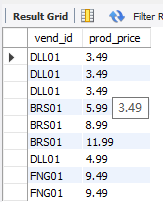
可以看到,where语句先过滤了价格小于4的,然后再根据行数大于2来聚集
分组的排序

使用group by应该也给出order by,不要只依赖group by
没有用order by
select order_num, count(*) as itemsfrom orderitemsgroup by order_numhaving count(*) >= 3;
出来的顺序不知道是什么顺序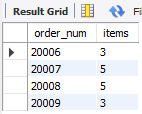
给出order by,按照items数量先排序,items相同的再按照订单号排序
select order_num, count(*) as itemsfrom orderitemsgroup by order_numhaving count(*) >= 3order by items, order_num;
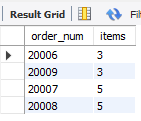

select子句的顺序
终于要总结他们的顺序了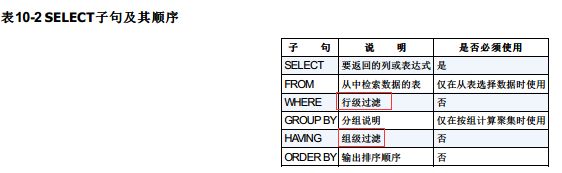
总结
- 虽然having和where很相似,但是要记住,having一定要和group by一起用,是用于过滤分组;而where是用于普通的行级过滤
- 掌握好where和having的差异
- 掌握好order by 和group by 的差异
- 掌握好设了select子句的顺序




























还没有评论,来说两句吧...