数据结构零基础,Java语言实现从入门到进阶
数据结构目录
- 关于数据结构中的基础知识
- 总结的并不是很到位。
- 一、数组(Array)
- 1.1 创建自己的数组以及对数组操作的方法(添加、查询、修改、包含、搜索、删除)
- 1.2将之前的数组代码修改为泛型
- 1.3动态数组(自动扩容和自动缩容)
- 1.4简单的时间复杂度分析
- 二、栈(Stack)和队列(Queue)
- 2.1关于栈
- **2.2程序调用系统栈**
- 2.3栈的基本实现
- 2.4关于队列(Queue)
- 2.5数组队列的基本实现
- 2.6循环队列的实现
- 2.7测试数组队列和循环队列二者的性能
- 小结:动态数组、栈、队列底层依托静态数组,靠的是resize解决固定容量问题!
- 三、链表LinkedList(真正的动态数据结构、最简单的动态数据结构)
- 3.1关于链表
- 3.2链表的基本实现(增加、遍历、查询、修改、删除)
- 3.3使用链表实现栈(在Stack工程下实现)
- 3.4比较数组栈和链表栈之间的性能差距
- 3.5使用链表实现队列(从队首端删除元素,从队尾端插入元素)
- 3.6移除链表元素(测试自己的链表代码,在题库提交类似的题目时,需将main函数中的内容去掉!!)
- 3.61不使用虚拟头节点**
- 3.62使用虚拟头节点
- 四、递归(Recursion)
- 4.1使用递归实现求和
- 4.2运用递归解决链表中删除元素的问题
- 4.3递归算法的调试(使用打印输出的方式来了解递归调用的过程)
- 五、二分搜索树(Binary Search Tree)
- 5.1在了解二分搜索树之前,先了解一下二叉树
- 5.2二分搜索树的特点
- 5.3二分搜索树的实现
- 六、集合和映射(Set and Map)
- 6.1基于二分搜索树的集合实现
- 6.2基于链表的集合实现
- 6.3关于映射
- 6.4基于链表的映射实现
- 6.5基于二分搜索树的映射实现
- 七、优先队列(PriorityQueue)和堆(Heap)
- 7.1使用二叉树来表示堆,简称二叉堆
- 7.2利用数组实现最大堆
- 7.3基于堆的优先队列
- 八、线段树(Segment Tree)、区间树
- 8.1关于线段树
- 8.2实现线段树
- 九、字典树(Trie),也叫做前缀树
- 9.1字典树的实现
- 十、并查集(Union Find)
- 10.1数组模拟实现并查集
- 10.2用孩子指向树的结构实现并查集
- 10.3基于size的优化
- 10.4基于rank(指树的高度)的优化
- 10.5路径压缩
- 十一、AVL树、平衡二叉树
- 11.1AVL树的实现
- 11.2基于AVL树的映射实现
- 11.3基于AVL树的集合实现
- 十二、红黑树
- 12.1关于红黑树
- 12.2 2-3树
- 12.3 2-3树添加元素的过程
- 12.4红黑树的实现
- 12.5红黑树的性能总结
- 十三、哈希表
- 实现哈希表(增删改查等方法)
关于数据结构中的基础知识
总结的并不是很到位。
一、数组(Array)
以下代码首先实现了数组的创建,以及对其所创建的数组进行一次二次封装。接着,在Array类中提供了对数组的添加、查询、修改、包含、搜索和删除的方法,以及到后面的使用泛型,动态数组,简单的复杂度分析和均摊复杂度和防止复杂度的震荡。
1.1 创建自己的数组以及对数组操作的方法(添加、查询、修改、包含、搜索、删除)
public class Array {private int[] data;private int size; //data数组中元素的个数//构造函数,传入数组的容量为capacitypublic Array(int capacity){data = new int[capacity];size = 0;}//无参数的构造函数,默认数组的容量capacity=10public Array(){this(10);//通过一个构造方法区调用另一个构造方法,达到代码重用。}//获取数组中的元素个数public int getSize(){return size;}//获取数组的容量public int getCapacity(){return data.length;}//返回数组是否为空public boolean isEmpty(){return size==0;}//向所有元素后添加一个新元素public void addLast(int e){add(size,e);}//向所有元素前添加一个新元素public void addFirst(int e){add(0,e);}//在index位置插入一个新元素epublic void add(int index,int e) {if (size == data.length){throw new IllegalArgumentException("Add failed. Array is full");}if(index <0 || index >size) {throw new IllegalArgumentException("Add failed. Require index >=0 and index <= size");}for(int i=size-1;i>=index;i--) {data[i + 1] = data[i];}data[index]=e;size++;}//获取index索引位置的元素int get(int index){if(index<0 || index>=size){throw new IllegalArgumentException("Get failed. Index is illegal");}return data[index];}//修改index索引位置的元素evoid set(int index,int e){if(index<0 || index>=size){throw new IllegalArgumentException("Get failed. index is illegal");}data[index] = e;}//查找数组中是否有元素epublic boolean contains(int e){for(int i=0;i<size;i++){if(data[i]==e){return true;}}return false;}//查找数组中元素e所在的索引,如果不存在元素e,则返回-1public int find(int e){for(int i=0;i<size;i++){if(data[i]==e){return i;}}return -1;}//从数组中删除index位置的元素,返回删除的元素public int remove(int index){if(index<0 || index>=size){throw new IllegalArgumentException("Remove failed Index is illegal");}int ret = data[index];for(int i=index+1;i<size;i++){data[i-1] = data[i];}size--;return ret;}//从数组中删除第一个元素,返回删除的元素public int removeFirst(){return remove(0);}//从数组中删除最后一个元素,返回删除的元素public int removeLast(){return remove(size-1);}//从数组中删除元素epublic void removeElement(int e){int index = find(e);if(index != -1){remove(index);}}@Overridepublic String toString(){StringBuilder res = new StringBuilder();res.append(String.format("Array:size = %d , capacity = %d\n",size,data.length));res.append('[');for(int i=0;i<size;i++){res.append(data[i]);if(i!=size-1) {res.append(",");}}res.append(']');return res.toString();}}
测试代码如下
public class Main {public static void main(String[] args) {Array arr=new Array(20);for(int i=0 ; i<10 ;i++)arr.addLast(i);System.out.println(arr);arr.add(1,100);System.out.println(arr);arr.addFirst(-1);System.out.println(arr);arr.remove(2);System.out.println(arr);arr.removeElement(4);System.out.println(arr);arr.removeFirst();System.out.println(arr);}}
此处为运行结果
1.2将之前的数组代码修改为泛型
public class Array<E> {private E[] data;private int size; //data数组中元素的个数//构造函数,传入数组的容量为capacitypublic Array(int capacity){data = (E[]) new Object[capacity];size = 0;}//无参数的构造函数,默认数组的容量capacity=10public Array(){this(10);//通过一个构造方法区调用另一个构造方法,达到代码重用。}//获取数组中的元素个数public int getSize(){return size;}//获取数组的容量public int getCapacity(){return data.length;}//返回数组是否为空public boolean isEmpty(){return size==0;}//向所有元素后添加一个新元素public void addLast(E e){add(size,e);}//向所有元素前添加一个新元素public void addFirst(E e){add(0,e);}//在index位置插入一个新元素epublic void add(int index,E e) {if (size == data.length){throw new IllegalArgumentException("Add failed. Array is full");}if(index <0 || index >size) {throw new IllegalArgumentException("Add failed. Require index >=0 and index <= size");}for(int i=size-1;i>=index;i--) {data[i + 1] = data[i];}data[index]=e;size++;}//获取index索引位置的元素public E get(int index){if(index<0 || index>=size){throw new IllegalArgumentException("Get failed. Index is illegal");}return data[index];}//修改index索引位置的元素epublic void set(int index,E e){if(index<0 || index>=size){throw new IllegalArgumentException("Get failed. index is illegal");}data[index] = e;}//查找数组中是否有元素epublic boolean contains(E e){for(int i=0;i<size;i++){if(data[i].equals(e)){return true;}}return false;}//查找数组中元素e所在的索引,如果不存在元素e,则返回-1public int find(E e){for(int i=0;i<size;i++){if(data[i].equals(e)){return i;}}return -1;}//从数组中删除index位置的元素,返回删除的元素public E remove(int index){if(index<0 || index>=size){throw new IllegalArgumentException("Remove failed Index is illegal");}E ret = data[index];for(int i=index+1;i<size;i++){data[i-1] = data[i];}size--;data[size]=null;return ret;}//从数组中删除第一个元素,返回删除的元素public E removeFirst(){return remove(0);}//从数组中删除最后一个元素,返回删除的元素public E removeLast(){return remove(size-1);}//从数组中删除元素epublic void removeElement(E e){int index = find(e);if(index != -1){remove(index);}}@Overridepublic String toString(){StringBuilder res = new StringBuilder();res.append(String.format("Array:size = %d , capacity = %d\n",size,data.length));res.append('[');for(int i=0;i<size;i++){res.append(data[i]);if(i!=size-1) {res.append(",");}}res.append(']');return res.toString();}}
测试
public class Main {public static void main(String[] args) {Array<Integer> arr=new Array<Integer>(20);//数组中存放的都是Integer类型for(int i=0 ; i<10 ;i++)arr.addLast(i);System.out.println(arr);arr.add(1,100);System.out.println(arr);arr.addFirst(-1);System.out.println(arr);arr.remove(2);System.out.println(arr);arr.removeElement(4);System.out.println(arr);arr.removeFirst();System.out.println(arr);}}
创建一个学生数组,泛型
public class Student {private String name;private int score;public Student(String studentName,int studentScore){name=studentName;score=studentScore;}@Overridepublic String toString(){return String.format("Student(name: %s, score: %d)",name,score);}public static void main(String[] args){Array<Student> arr = new Array<Student>();arr.addLast(new Student("Alice",100));arr.addLast(new Student("Bob",70));arr.addLast(new Student("Tracy",80));System.out.println(arr);}}
输出结果
1.3动态数组(自动扩容和自动缩容)
增加了扩容方法和缩容逻辑
public class Array<E> {private E[] data;private int size; //data数组中元素的个数//构造函数,传入数组的容量为capacitypublic Array(int capacity){data = (E[]) new Object[capacity];size = 0;}//无参数的构造函数,默认数组的容量capacity=10public Array(){this(10);//通过一个构造方法区调用另一个构造方法,达到代码重用。}public Array(E[] arr){data =(E[]) new Object[arr.length];for(int i=0;i<arr.length;i++){data[i] = arr[i];}size = arr.length;}//获取数组中的元素个数public int getSize(){return size;}//获取数组的容量public int getCapacity(){return data.length;}//返回数组是否为空public boolean isEmpty(){return size==0;}//向所有元素后添加一个新元素public void addLast(E e){add(size,e);}//向所有元素前添加一个新元素public void addFirst(E e){add(0,e);}//在第index位置插入一个新元素epublic void add(int index,E e) {if(index <0 || index >size) {throw new IllegalArgumentException("Add failed. Require index >=0 and index <= size");}if (size == data.length){resize(2 * data.length);}for(int i=size-1;i>=index;i--) {data[i + 1] = data[i];}data[index]=e;size++;}//获取index索引位置的元素public E get(int index){if(index<0 || index>=size){throw new IllegalArgumentException("Get failed. Index is illegal");}return data[index];}//修改index索引位置的元素epublic void set(int index,E e){if(index<0 || index>=size){throw new IllegalArgumentException("Get failed. index is illegal");}data[index] = e;}//查找数组中是否有元素epublic boolean contains(E e){for(int i=0;i<size;i++){if(data[i].equals(e)){return true;}}return false;}//查找数组中元素e所在的索引,如果不存在元素e,则返回-1public int find(E e){for(int i=0;i<size;i++){if(data[i].equals(e)){return i;}}return -1;}//从数组中删除index位置的元素,返回删除的元素public E remove(int index){if(index<0 || index>=size){throw new IllegalArgumentException("Remove failed Index is illegal");}E ret = data[index];for(int i=index+1;i<size;i++){data[i-1] = data[i];}size--;data[size]=null;//对数组缩容if(size==data.length / 2){resize(data.length / 2);}return ret;}//从数组中删除第一个元素,返回删除的元素public E removeFirst(){return remove(0);}//从数组中删除最后一个元素,返回删除的元素public E removeLast(){return remove(size-1);}//从数组中删除元素epublic void removeElement(E e){int index = find(e);if(index != -1){remove(index);}}public void swap(int i,int j){if(i<0 || i>=size || j<0 || j>=size){throw new IllegalArgumentException("index is illegal");}E t = data[i];data[i] = data[j];data[j] = t;}@Overridepublic String toString(){StringBuilder res = new StringBuilder();res.append(String.format("Array:size = %d , capacity = %d\n",size,data.length));res.append('[');for(int i=0;i<size;i++){res.append(data[i]);if(i!=size-1) {res.append(",");}}res.append(']');return res.toString();}//数组扩容private void resize(int newCapacity){E[] newData =(E[]) new Object[newCapacity];for(int i=0;i<size;i++){newData[i]=data[i];}data=newData;}}
测试
public class Main {public static void main(String[] args) {Array<Integer> arr=new Array<>();//数组中存放的都是Integer类型for(int i=0 ; i<10 ;i++)arr.addLast(i);System.out.println(arr);arr.add(1, 100);System.out.println(arr);arr.addFirst(-1);System.out.println(arr);arr.remove(2);System.out.println(arr);arr.removeElement(4);System.out.println(arr);arr.removeFirst();System.out.println(arr);}}
运行结果:当数组个数为原有容量的二分之一时,原数组容量也随之缩小二分之一;当数组个数超出原数组容量时,数组容量将会扩容为原来容量的二倍。
1.4简单的时间复杂度分析

为什么要用大O,叫做O(n)?
忽略常数。实际时间T=c1*n+c2
线性时间的算法:
T=2n+2 — O(n)
T=2000n+10000 — O(n)
O的表示实际上叫做渐进复杂度。渐进(描述n趋近于无穷的情况)
T=1nn+0 — O(n^2)
n越大,O(n)级别的算法远远快于O(n^2)级别的算法
T=2nn+300n+10 — O(n^2) 300n这个低阶项会被忽略掉
分析动态数组的时间复杂度
添加操作:最坏情况,三者均为O(n)操作,因为有resize 为O(n)操作
addLast(e) O(1)操作
addFirst(e) O(n)操作
add(index,e) O(n/2)=O(n) 操作
删除操作:最坏情况,三者均为O(n)操作,因为有resize 为O(n)操作
removeLast(e) O(1)
removeFirst(e) O(n)
remove(index,e) O(n/2)=O(n)
修改操作:
set(index,e) O(1)操作
查找操作:
get(index) O(1)操作
contains(e) O(n)操作
find(e) O(n)操作

resize复杂度分析
resize O(n) 操作
9次addLast操作,触发resize,总共进行了17次基本操作,平均,每次addLast操作,进行2次基本操作。
假设capacity = n,n+1次addLast,触发resize,总共进行2n+1次基本操作,平均,每次addLast操作,进行2次基本操作。这样均摊计算,时间复杂度是O(1)的!这种思想为均摊复杂度(amortized time complexity)其思想是一个相对比较耗时的操作,如果我们能够保证它不会每次都触发,这个耗时的操作相应的时间可以分摊到其他操作上。
addLast的均摊复杂度为O(1),同理,removeLast操作,均摊复杂度也为O(1).
当同时看addLast和removeLast操作的时候,出现了复杂度震荡(在调用addLast方法时,出现了capacity的扩容;当调用removeLast方法时,又出现了capacity的缩容,其都是O(n)操作)
出现复杂度震荡的原因:removeLast时resize过于着急
解决方案:当size==capacity/4时,才将capacity缩容减半
解决方案运用到代码中:修改缩容部分的代码,修改后如下:
二、栈(Stack)和队列(Queue)
2.1关于栈
1.栈也是一种线性结构
2.相比数组,栈对应的操作时数组的子集
3.只能从一端添加元素,也只能从一端取出元素
4.这一端称为栈顶
5.栈是一种先进后出的数据结构
以下图示展示压栈,弹栈,以及先进后出
 弹栈也可以叫做出栈
弹栈也可以叫做出栈
2.2程序调用系统栈

2.3栈的基本实现
首先创建一个接口
public interface Stack<E> {int getSize();boolean isEmpty();void push(E e);//入栈E pop();//出栈E peek();//栈顶}
接着将之前的动态数组粘贴到当前的包中,并增加以下两个新的方法
接着创建一个ArrayStack类
public class ArrayStack<E> implements Stack<E> {Array<E> array;public ArrayStack(int capacity){array = new Array<>(capacity);}public ArrayStack(){array = new Array<>();}@Overridepublic int getSize(){return array.getSize();}@Overridepublic boolean isEmpty(){return array.isEmpty();}public int getCapacity(){return array.getCapacity();}@Overridepublic void push(E e){ //压栈array.addLast(e);}@Overridepublic E pop(){ //弹栈return array.removeLast();}@Overridepublic E peek(){return array.getLast();}@Overridepublic String toString(){StringBuilder res = new StringBuilder();res.append("Stack: ");res.append('[');for(int i=0;i<array.getSize();i++){res.append(array.get(i));if(i != array.getSize()-1){res.append(", ");}}res.append("] top");//显示栈顶元素return res.toString();}}
测试类
public class Main {public static void main(String[] args) {ArrayStack<Integer> stack = new ArrayStack<>();for(int i=0;i<5;i++){stack.push(i); //入栈操作System.out.println(stack);}stack.pop(); //出栈操作System.out.println(stack);}}
运行结果
最右边的是栈顶元素
2.4关于队列(Queue)
1.队列也是一种线性结构
2.相比数组,队列对应的操作是数组的子集
3.只能从一端(队尾)添加元素,只能从另一端(队首)取出元素
4.队列是一种先进先出的数据结构
以下图示展现队列以及先进先出:

2.5数组队列的基本实现
首先创建一个Queue接口
public interface Queue<E> {int getSize();boolean isEmpty();void enqueue(E e); //入队E dequeue(); //出队E getFront(); //队首}
接着将上面栈中的Array类复制到Queue包中
然后再创建一个ArrayQueue类并进行测试
public class ArrayQueue<E> implements Queue<E> {private Array<E> array;public ArrayQueue(int capacity){array = new Array<>(capacity);}public ArrayQueue(){array = new Array<>();}@Overridepublic int getSize(){return array.getSize();}@Overridepublic boolean isEmpty(){return array.isEmpty();}public int getCapacity(){return array.getCapacity();}@Overridepublic void enqueue(E e){array.addLast(e);}@Overridepublic E dequeue(){return array.removeFirst();}@Overridepublic E getFront(){return array.getFirst();}@Overridepublic String toString(){StringBuilder res = new StringBuilder();res.append("Queue: ");res.append("front ["); //显示队首for(int i=0;i<array.getSize();i++){res.append(array.get(i));if(i != array.getSize()-1){res.append(", ");}}res.append("] tail");//显示队尾return res.toString();}public static void main(String[] args){ArrayQueue<Integer> queue = new ArrayQueue<>();for(int i=0;i<10;i++){queue.enqueue(i);System.out.println(queue);if(i % 3 == 2){queue.dequeue();System.out.println(queue);}}}}
运行结果如下(每添加3个元素后从队首往出拿一个)
2.6循环队列的实现
public class LoopQueue<E> implements Queue<E> {private E[] data;private int front,tail; //队首,队尾private int size;public LoopQueue(int capacity){data =(E[]) new Object[capacity + 1];front = 0;tail = 0;size = 0;}public LoopQueue(){this(10);}public int getCapacity(){return data.length-1;}@Overridepublic boolean isEmpty(){return front == tail;}@Overridepublic int getSize(){return size;}//循环队列的入队过程@Overridepublic void enqueue(E e){if((tail+1) % data.length == front){resize(getCapacity() * 2);}data[tail]=e;tail = (tail+1)% data.length;size++;}//循环队列出队过程@Overridepublic E dequeue(){if(isEmpty()){throw new IllegalArgumentException("Cannot dequeue from an empty queue");}E ret = data[front];data[front]=null;front = (front + 1) % data.length;size--;//缩容操作if(size==getCapacity()/4 && getCapacity()/2 !=0){resize(getCapacity()/2);}return ret;}@Overridepublic E getFront(){if(isEmpty()){throw new IllegalArgumentException("Queue is empty");}return data[front];}//数组扩容private void resize(int newCapacity){E[] newData =(E[]) new Object[newCapacity + 1];for(int i=0;i<size;i++){newData[i] = data[(i+front) % data.length];}data=newData;front=0;tail=size;}@Overridepublic String toString(){StringBuilder res = new StringBuilder();res.append(String.format("Queue: size = %d , capacity = %d\n", size, getCapacity()));res.append("front [");for(int i = front; i!=tail;i=(i+1)%data.length){res.append(data[i]);if((i+1)%data.length != tail){res.append(", ");}}res.append("] tail");return res.toString();}public static void main(String[] args){LoopQueue<Integer> queue = new LoopQueue<>();for(int i=0;i<10;i++){queue.enqueue(i);System.out.println(queue);if(i%3 == 2){queue.dequeue();System.out.println(queue);}}}}
运行结果:
每次入队3个元素后都会进行一次出队操作,相应的,若数组中的元素比原容量的二分之一还要小,则进行一次缩容操作;若数组中的元素个数大于容量个数,则进行一次扩容操作!
2.7测试数组队列和循环队列二者的性能
import java.util.Random;public class Main {//测试使用q运行opCount个enqueue和dequeue操作所需要的时间,单位秒private static double testQueue(Queue<Integer> q,int opCount){long startTime = System.nanoTime();Random random = new Random();for(int i=0;i<opCount;i++){q.enqueue(random.nextInt(Integer.MAX_VALUE));}for(int i=0;i<opCount;i++){q.dequeue();}long endTime = System.nanoTime();return (endTime-startTime)/1000000000.0;}public static void main(String[] args){int opCount = 100000;ArrayQueue<Integer> arrayQueue = new ArrayQueue<>();double time1 = testQueue(arrayQueue,opCount);System.out.println("ArrayQueue,time: "+time1+"s");LoopQueue<Integer> loopQueue = new LoopQueue<>();double time2 = testQueue(loopQueue,opCount);System.out.println("LoopQueue,time: "+time2+"s");}}
运行结果如下:
注:不同的计算机性能不同,所测试出的结果也不相同,但肯定的是,循环队列的性能要比数组队列的要好很多!
小结:动态数组、栈、队列底层依托静态数组,靠的是resize解决固定容量问题!
三、链表LinkedList(真正的动态数据结构、最简单的动态数据结构)
3.1关于链表
1.数据存储在”节点(Node)“中
2.优点:真正的动态,不需要处理固定容量的问题
3.缺点:丧失了随机访问能力

3.2链表的基本实现(增加、遍历、查询、修改、删除)
public class LinkedList<E> {private class Node{public E e;public Node next;public Node(E e,Node next){this.e=e;this.next=next;}public Node(E e){this(e,null);}public Node(){this(null,null);}@Overridepublic String toString(){return e.toString();}}private Node dummyHead;//虚拟头节点private int size;//个数public LinkedList(){dummyHead=new Node(null,null);size=0;}//获取链表中的元素个数public int getSize(){return size;}//返回链表是否为空public boolean isEmpty(){return size==0;}//在链表的index(从0开始)位置添加新的元素e//在链表中不是一个常用的操作,练习用public void add(int index, E e){if(index<0 || index>size){throw new IllegalArgumentException("Add failed Illegal index");}Node prev = dummyHead;for(int i=0;i<index;i++){prev=prev.next;}// Node node = new Node(e);// node.next = prev.next;// prev.next = node;//以上三行代码可以用以下一行代码表示prev.next = new Node(e,prev.next);size++;}//在链表头添加新的元素epublic void addFirst(E e){add(0,e);}//在链表末尾添加新的元素epublic void addLast(E e){add(size,e);}//获得链表的第index(从0开始)个位置的元素//在链表中不是一个常用操作,练习用public E get(int index){if(index < 0 || index >=size){throw new IllegalArgumentException("Get failed Illegal index");}Node cur = dummyHead.next;for(int i = 0;i<index;i++){cur = cur.next;}return cur.e;}//获得链表的第一个元素public E getFirst(){return get(0);}//获得链表的最后一个元素public E getLast(){return get(size-1);}//修改链表的第index(从0开始)个位置的元素e//在链表中不是一个常用操作,练习用public void set(int index,E e){if(index<0 || index>= size){throw new IllegalArgumentException("Set failed Illegal index");}Node cur = dummyHead.next;for(int i=0;i<index;i++){cur=cur.next;}cur.e=e;}//查找链表中是否含有元素epublic boolean contains(E e){Node cur = dummyHead.next;while(cur!=null){if(cur.e.equals(e)){return true;}cur=cur.next;}return false;}//从链表中删除index(从0开始)位置的元素,返回删除的元素//在链表中不是一个常用的操作,练习用public E remove(int index){if(index<0 || index>=size){throw new IllegalArgumentException("Remove failed Index is illegal");}Node prev = dummyHead;for(int i=0;i<index;i++){prev = prev.next;}Node retNode=prev.next;prev.next = retNode.next;retNode.next=null;size--;return retNode.e;}//从链表中删除最后一个元素,返回删除元素public E removeFirst(){return remove(0);}//从链表中删除最后一个元素,返回删除元素public E removeLast(){return remove(size-1);}//从链表中删除元素epublic void removeElement(E e){Node prev = dummyHead;while(prev.next != null){if(prev.next.e.equals(e)){break;}prev=prev.next;}if(prev.next != null){Node delNode = prev.next;prev.next = delNode.next;delNode.next = null;}}@Overridepublic String toString(){StringBuilder res = new StringBuilder();Node cur = dummyHead.next;while(cur!=null){res.append(cur+"->");cur=cur.next;}res.append("NULL");return res.toString();}}
测试
public class Main {public static void main(String[] args){LinkedList<Integer> linkedList = new LinkedList<>();for(int i=0;i<5;i++){//从头添加元素linkedList.addFirst(i);System.out.println(linkedList);}//从索引为2的地方添加一个666元素linkedList.add(2,666);System.out.println(linkedList);System.out.println("==========");//删除元素linkedList.remove(2);System.out.println(linkedList);linkedList.removeFirst();System.out.println(linkedList);linkedList.removeLast();System.out.println(linkedList);}}
运行结果如下
3.3使用链表实现栈(在Stack工程下实现)
public class LinkedListStack<E> implements Stack<E>{private LinkedList<E> list;public LinkedListStack(){list = new LinkedList<>();}@Overridepublic int getSize(){return list.getSize();}@Overridepublic boolean isEmpty(){return list.isEmpty();}@Overridepublic void push(E e){list.addFirst(e);}@Overridepublic E pop(){return list.removeFirst();}@Overridepublic E peek(){return list.getFirst();}@Overridepublic String toString(){StringBuilder res=new StringBuilder();res.append("Stack: top ");res.append(list);return res.toString();}public static void main(String[] args) {LinkedListStack<Integer> stack = new LinkedListStack<>();for(int i=0;i<5;i++){stack.push(i); //入栈操作System.out.println(stack);}stack.pop(); //出栈操作System.out.println(stack);}}
运行结果
3.4比较数组栈和链表栈之间的性能差距
import java.util.Random;public class Main {//测试使用stack运行opCount个push和pop操作所需要的时间,单位秒private static double testStack(Stack<Integer> stack,int opCount){long startTime = System.nanoTime();Random random = new Random();for(int i=0;i<opCount;i++){stack.push(random.nextInt(Integer.MAX_VALUE));}for(int i=0;i<opCount;i++){stack.pop();}long endTime=System.nanoTime();return (endTime-startTime)/1000000000.0;}public static void main(String[] args){int opCpunt=100000;ArrayStack<Integer> arrayStack=new ArrayStack<>();double time1=testStack(arrayStack,opCpunt);System.out.println("ArrayStack,time: "+time1+"s");LinkedListStack<Integer> linkedListStack = new LinkedListStack<>();double time2 = testStack(linkedListStack,opCpunt);System.out.println("LinkedListStack,time: "+time2+"s");}}
运行结果:
实际上,无论是链表栈还是数组栈,他们的各项操作中都属于同一时间复杂度的,所以在不同情况下谁比谁耗时长一些或短一些都是很正常的,而且与JVM的版本号和电脑的操作系统有一定的关系。二者在复杂度上面没有巨大的差异。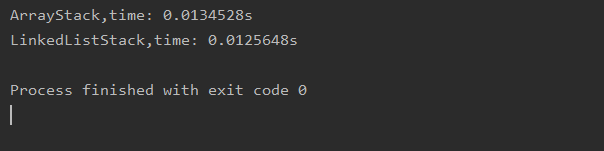
3.5使用链表实现队列(从队首端删除元素,从队尾端插入元素)
public class LinkedListQueue<E> implements Queue<E> {private class Node{public E e;public Node next;public Node(E e,Node next){this.e=e;this.next=next;}public Node(E e){this(e,null);}public Node(){this(null,null);}@Overridepublic String toString(){return e.toString();}}private Node head,tail;private int size;public LinkedListQueue(){head = null;tail = null;size = 0;}@Overridepublic int getSize(){return size;}@Overridepublic boolean isEmpty(){return size==0;}//入队操作@Overridepublic void enqueue(E e){if(tail==null){tail=new Node(e);head=tail;}else{tail.next=new Node(e);tail=tail.next;}size++;}//出队操作@Overridepublic E dequeue(){if(isEmpty()){throw new IllegalArgumentException("Cannot dequeue from an empty queue");}Node retNode=head;head=head.next;retNode.next=null;if(head==null){tail=null;}size--;return retNode.e;}//查看队首@Overridepublic E getFront(){if(isEmpty()){throw new IllegalArgumentException("Queue is Empty");}return head.e;}@Overridepublic String toString(){StringBuilder res = new StringBuilder();res.append("Queue: front ");Node cur = head;while(cur!=null){res.append(cur+"->");cur=cur.next;}res.append("NULL tail");return res.toString();}public static void main(String[] args){LinkedListQueue<Integer> queue = new LinkedListQueue<>();for(int i=0;i<10;i++){queue.enqueue(i);System.out.println(queue);//每次入队3个元素就出队一个元素if(i%3==2){queue.dequeue();System.out.println(queue);}}}}
运行结果:
每次入队三个元素将会出队一个
3.6移除链表元素(测试自己的链表代码,在题库提交类似的题目时,需将main函数中的内容去掉!!)
删除链表中等于给定值 val 的所有节点。
示例:
输入: 1->2->6->3->4->5->6, val = 6
输出: 1->2->3->4->5
3.61不使用虚拟头节点**
首先创建一个ListNode类
public class ListNode {public int val;public ListNode next;public ListNode(int x){val = x;}//链表节点的构造函数//使用arr为参数,创建一个链表,当前的ListNode为链表头节点public ListNode(int[] arr){if(arr == null || arr.length == 0){throw new IllegalArgumentException("arr cannot be empty");}this.val=arr[0];ListNode cur = this;for(int i=1;i<arr.length;i++){cur.next = new ListNode(arr[i]);cur = cur.next;}}//以当前节点为头节点的链表信息字符串@Overridepublic String toString(){StringBuilder res = new StringBuilder();ListNode cur = this;while(cur != null){res.append(cur.val + "->");cur = cur.next;}res.append("NULL");return res.toString();}}
再创建Solution类
import java.util.List;public class Solution {public ListNode removeElements(ListNode head,int val){while(head != null && head.val == val){head = head.next;}if(head==null){return null;}ListNode prev = head;while(prev.next != null){if(prev.next.val == val){prev.next = prev.next.next;}else{prev = prev.next;}}return head;}//测试public static void main(String[] args){int[] nums = { 1,2,6,3,4,5,6,};ListNode head = new ListNode(nums);System.out.println(head);ListNode res = (new Solution()).removeElements(head,6);System.out.println(res);}}
运行结果如下
3.62使用虚拟头节点
public class Solution2 {public ListNode removeElements(ListNode head,int val){ListNode dummyHead = new ListNode(-1);dummyHead.next = head;ListNode prev = dummyHead;while(prev.next != null){if(prev.next.val == val){prev.next = prev.next.next;}else{prev = prev.next;}}return dummyHead.next;}//测试public static void main(String[] args){int[] nums = { 1,2,6,3,4,5,6,};ListNode head = new ListNode(nums);System.out.println(head);ListNode res = (new Solution2()).removeElements(head,6);System.out.println(res);}}
运行结果如下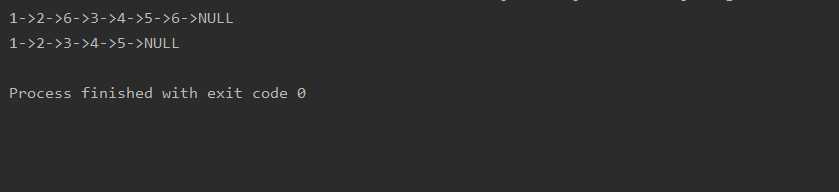
四、递归(Recursion)
编程语言中,函数直接或间接调用函数本身,则该函数称为递归函数。
近乎和链表相关的所有操作都可以用递归来完成。
4.1使用递归实现求和
public class Sum {public static int sum(int[] arr){return sum(arr,0);}//计算arr[l...n)这个区间内所有数字的和private static int sum(int[] arr,int l){if(l==arr.length){return 0;}else{return arr[l] + sum(arr,l+1);}}public static void main(String[] args){int[] nums={ 1,2,3,4,5,6,7,8};System.out.println(sum(nums));}}
4.2运用递归解决链表中删除元素的问题
我们可以将最原始的链表理解成:头节点后边接着一个更短的链表,然后运用递归删除这个更短链表中相应的元素。如果头节点不需要删除的话,那么结果就是,头节点接上后面的删除元素后的那个更短的链表,如果头节点需要删除的话,那么对应的结果就是,删除元素后得道德那个更短的链表。
测试
public class Solution3 {//使用递归public ListNode removeElements(ListNode head,int val){if(head == null){return null;}head.next = removeElements(head.next,val);return head.val == val ? head.next : head;}//测试public static void main(String[] args){int[] nums = { 1,2,6,3,4,5,6,};ListNode head = new ListNode(nums);System.out.println(head);ListNode res = (new Solution3()).removeElements(head,6);System.out.println(res);}}
结果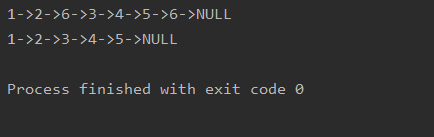
4.3递归算法的调试(使用打印输出的方式来了解递归调用的过程)
运用递归深度(每一个函数在它内部再次调用自身,则递归深度就多了1)来表示。
import java.util.List;public class Test {//使用递归public ListNode removeElements(ListNode head,int val,int depth){ //depth代表递归深度String depthString = generateDepthString(depth);System.out.print(depthString);//打印深度字符串System.out.println("Call: remove" + val + "in" + head); //在head这个节点删去val这个元素if(head == null){System.out.print(depthString);System.out.println("Return: " + head);return head;}ListNode res = removeElements(head.next,val,depth+1);System.out.print(depthString);System.out.println("After remove" + val + ":" + res);ListNode ret;if(head.val == val){ret = res;}else{head.next = res;ret = head;}System.out.print(depthString);System.out.println("Return: " + ret);return ret;}private String generateDepthString(int depth){StringBuilder res = new StringBuilder();for(int i=0;i<depth;i++){res.append("-");//深度越深,“-”越多}return res.toString();}//测试public static void main(String[] args){int[] nums = { 1,2,6,3,4,5,6,};ListNode head = new ListNode(nums);System.out.println(head);ListNode res = (new Test()).removeElements(head,6,0);System.out.println(res);}}
运行结果如下:
-代表深度字符串,-越多代表递归调用深度越高,-的长度相同,代表在同一深度的递归调用。要在1->2->6->3->4->5->6->null这个链表中删除6,就必须递归调用对2->6->3->4->5->6->null这个链表递归调用删除6的结果,再次递归调用在6->3->4->5->6->null这个链表中删除6的结果,以此类推,当到达空列表删除6这一过程时,返回的依然为null,此时就回到了6->null这一层的结果调用,6是被删除的元素,所以此时返回的依然是null,再回到了5->6->null这一链表中删除6,返回5->null这个链表,依次返回,最终得到了最后的结果,返回1->2->3->4->5->null这一链表。
五、二分搜索树(Binary Search Tree)
5.1在了解二分搜索树之前,先了解一下二叉树
1.二叉树具有根节点
2.二叉树每个节点最多分成两个节点,分为左节点和右节点
3.二叉树具有天然递归结构
4.二叉树不一定是“满的”,有的节点可能只分成一个节点


5.2二分搜索树的特点
1.首先,二分搜索树是一个二叉树
2.二分搜索树,每个节点的值,大于其左子树的所有节点的值;小于其右子树的所有节点的值
3.每一颗子树也是二分搜索树
4.存储的元素必须右可比性
5.3二分搜索树的实现
以下程序包含了二分搜索树的增删改查等各种方法,与前面的数据结构相比
,代码量偏多,而且也相对难理解!!!不过,总体上方法都能够被调用,就是写的较乱了一些。
import java.util.LinkedList;import java.util.Queue;import java.util.Stack;public class BST<E extends Comparable<E>> {private class Node{public E e;public Node left,right;public Node(E e){this.e = e;left = null;right = null;}}private Node root;private int size;public BST(){root = null;size = 0;}public int size(){return size;}public boolean isEmpty(){return size==0;}//向二分搜索树中添加新的元素public void add(E e){root = add(root,e);}//向以node为根的二分搜索树中插入元素E,递归算法//返回插入新节点后二分搜索树的根private Node add(Node node,E e){if(node == null){size++;return new Node(e);}if(e.compareTo(node.e) < 0){node.left = add(node.left,e);}else if(e.compareTo(node.e) > 0){node.right = add(node.right,e);}return node;}//查询操作//看二分搜索树中是否包含元素epublic boolean contains(E e){return contains(root,e);}//看以node为根的二分搜索书中是否包含元素e,递归算法private boolean contains(Node node,E e){if(node == null){return false;}if(e.compareTo(node.e) == 0){return true;}else if(e.compareTo(node.e) < 0){return contains(node.left,e);}else{return contains(node.right,e);}}//二分搜索树的前序遍历public void preOrder(){preOrder(root);}//前序遍历以node为根的二分搜索树,递归算法private void preOrder(Node node){if(node == null){return;}System.out.println(node.e);preOrder(node.left);preOrder(node.right);}//二分搜索树的非递归前序遍历public void preOrderNR(){Stack<Node> stack = new Stack<>();stack.push(root);while(!stack.isEmpty()){Node cur = stack.pop();System.out.println(cur.e);if(cur.right!=null){stack.push(cur.right);}if(cur.left!=null){stack.push(cur.left);}}}//二分搜索树的中序遍历(中序遍历的结果是顺序的)public void inOrder(){inOrder(root);}//中序遍历以node为根的二分搜索树,递归算法private void inOrder(Node node){if(node == null){return;}inOrder(node.left);System.out.println(node.e);inOrder(node.right);}//二分搜索树的后序遍历public void postOrder(){postOrder(root);}//后续遍历以node为根的二分搜索树,递归算法private void postOrder(Node node){if(node == null){return;}postOrder(node.left);postOrder(node.right);System.out.println(node.e);}//二分搜索树的层序遍历,运用队列public void levelOrder(){Queue<Node> q = new LinkedList<>();q.add(root);while(!q.isEmpty()){Node cur = q.remove();System.out.println(cur.e);if(cur.left != null){q.add(cur.left);}if(cur.right != null){q.add(cur.right);}}}//寻找二分搜索树的最小元素public E minimum(){if(size == 0){throw new IllegalArgumentException("BST is empty");}return minimum(root).e;}//返回以node为根的二分搜索树的最小值所在的节点private Node minimum(Node node){if(node.left == null){return node;}return minimum(node.left);}//寻找二分搜索树的最大元素public E maximum(){if(size == 0){throw new IllegalArgumentException("BST is empty");}return maximum(root).e;}//返回以node为根的二分搜索树的最大值所在的节点private Node maximum(Node node){if(node.right == null){return node;}return maximum(node.right);}//从二分搜索树中删除最小值所在节点,返回最小值public E removeMin(){E ret = minimum();removeMin(root);return ret;}//删除掉以node为根的二分搜索树中的最小节点//返回删除节点后的新的二分搜索树的根private Node removeMin(Node node){if(node.left == null){Node rightNode = node.right;node.right = null;size--;return rightNode;}node.left = removeMin(node.left);return node;}//从二分搜索树中删除最大值所在的节点public E removeMax(){E ret = maximum();root = removeMax(root);return ret;}//删除掉以node为根的二分搜索树中的最大节点//返回删除节点后新的二分搜索树的根private Node removeMax(Node node){if(node.right == null){Node leftNode = node.left;node.left = null;size--;return leftNode;}node.right = removeMax(node.right);return node;}//从二分搜索树中删除元素为e的节点public void remove(E e){root = remove(root,e);}//删除以node为根的二分搜索树中值为e的节点,递归算法//返回节点后的新的二分搜索树的根private Node remove(Node node,E e){if(node==null){return null;}if(e.compareTo(node.e)<0){node.left = remove(node.left,e);return node;}else if(e.compareTo(node.e)>0){node.right = remove(node.right,e);return node;}else {//待删除节点左子树为空的情况if(node.left == null){Node rightNode = node.right;node.right = null;size--;return rightNode;}//待删除节点右子树为空的情况if(node.right == null){Node leftNode = node.left;node.left = null;size--;return leftNode;}//待删除节点左右子树均不为空的情况//找到比待删除节点大的最小节点,即待删除节点右子树的最小节点//用这个节点顶替待删除节点的位置Node successor = minimum(node.right);successor.right = removeMin(node.right);successor.left = node.left;node.left = node.right = null;return successor;}}@Overridepublic String toString(){StringBuilder res = new StringBuilder();generateBSTString(root,0,res);return res.toString();}//生成以node为根节点,深度为depth的描述二叉树的字符串private void generateBSTString(Node node,int depth,StringBuilder res){if(node == null){res.append(generateDepthString(depth) + "null\n");return;}res.append(generateDepthString(depth) + node.e + "\n");generateBSTString(node.left,depth+1,res);generateBSTString(node.right,depth+1,res);}private String generateDepthString(int depth){StringBuilder res = new StringBuilder();for(int i=0;i<depth;i++){res.append("-");}return res.toString();}}
测试遍历
public class Main {public static void main(String[] args){BST<Integer> bst = new BST<>();int[] nums = { 5,3,6,8,4,2};for(int num:nums){bst.add(num);}//前序遍历// bst.preOrder();// System.out.println();//// bst.preOrderNR();//中序遍历//bst.inOrder();//System.out.println();//后序遍历//bst.postOrder();//System.out.println();//层序遍历bst.levelOrder();}}
测试删除
import java.util.ArrayList;import java.util.Random;public class Main {public static void main(String[] args) {BST<Integer> bst = new BST<>();Random random = new Random();int n = 100;//test removeMinfor(int i=0;i<n;i++){bst.add(random.nextInt(100));}ArrayList<Integer> nums = new ArrayList<>();while(!bst.isEmpty()){nums.add(bst.removeMin());}System.out.println(nums);for(int i=1;i<nums.size();i++){if(nums.get(i-1)>nums.get(i)){throw new IllegalArgumentException("error");}}System.out.println("removeMin test completed");//test removeMaxfor(int i=0;i<n;i++){bst.add(random.nextInt(100));}nums=new ArrayList<>();while(!bst.isEmpty()){nums.add(bst.removeMax());}System.out.println(nums);for(int i=1;i<nums.size();i++){if(nums.get(i-1)<nums.get(i)){throw new IllegalArgumentException("error");}}System.out.println("removeMax test completed");}}
六、集合和映射(Set and Map)
6.1基于二分搜索树的集合实现
首先,要定义一个Set接口
public interface Set<E> {void add(E e);void remove(E e);boolean contains(E e);int getSize();boolean isEmpty();}public class BSTSet<E extends Comparable<E>> implements Set<E>{private BST<E> bst;public BSTSet(){bst = new BST<>();}@Overridepublic int getSize(){return bst.size();}@Overridepublic boolean isEmpty(){return bst.isEmpty();}@Overridepublic void add(E e){bst.add(e);}@Overridepublic boolean contains(E e){return bst.contains(e);}@Overridepublic void remove(E e){bst.remove(e);}}
6.2基于链表的集合实现
public class LinkedListSet<E> implements Set<E> {private LinkedList<E> list;public LinkedListSet(){list = new LinkedList<>();}@Overridepublic int getSize(){return list.getSize();}@Overridepublic boolean isEmpty(){return list.isEmpty();}@Overridepublic boolean contains(E e){return list.contains(e);}@Overridepublic void add(E e){if(!list.contains(e)){list.addFirst(e);}}@Overridepublic void remove(E e){list.removeElement(e);}}
6.3关于映射
可以将映射简单的理解为:
字典—>单词对应相应的释意
点名册—>身份证号对应人
车辆管理—>车牌号对应车
映射特点:
1.存储键值对的数据结构(键(key),值(value))
2.根据键(key),寻找值(value)
6.4基于链表的映射实现
首先定义一个Map接口
public interface Map<K,V> {void add(K key,V value);V remove(K key);boolean contains(K key);V get(K key);void set(K key, V newValue);int getSize();boolean isEmpty();}
创建一个LinkedListMap类
public class LinkedListMap<K,V> implements Map<K,V> {private class Node{public K key;public V value;public Node next;public Node(K key,V value,Node next){this.key = key;this.value = value;this.next = next;}public Node(K key){this(key,null,null);}public Node(){this(null,null,null);}@Overridepublic String toString(){return key.toString() + ":" + value.toString();}}private Node dummyHead;private int size;public LinkedListMap(){dummyHead = new Node();size = 0;}@Overridepublic int getSize(){return size;}@Overridepublic boolean isEmpty(){return size==0;}private Node getNode(K key){Node cur = dummyHead.next;while(cur!=null){if(cur.key.equals(key)){return cur;}cur = cur.next;}return null;}@Overridepublic boolean contains(K key){return getNode(key) != null;}@Overridepublic V get(K key){Node node = getNode(key);return node == null ? null : node.value;}//添加操作@Overridepublic void add(K key, V value){Node node = getNode(key);if(node == null){dummyHead.next = new Node(key,value,dummyHead.next);size++;}else{node.value = value;}}@Overridepublic void set(K key, V newValue){Node node = getNode(key);if(node == null){throw new IllegalArgumentException(key + "doesn't exist ");}node.value = newValue;}@Overridepublic V remove(K key){Node prev = dummyHead;while(prev.next != null){if(prev.next != null){break;}prev = prev.next;}if(prev.next != null){Node delNode = prev.next;prev.next = delNode.next;delNode.next = null;size--;return delNode.value;}return null;}}
6.5基于二分搜索树的映射实现
public class BSTMap<K extends Comparable<K>,V> implements Map<K,V>{private class Node{public K key;public V value;public Node left,right;public Node(K key,V value){this.key=key;this.value=value;left=null;right=null;}}private Node root;private int size;public BSTMap(){root=null;size=0;}@Overridepublic int getSize(){return size;}@Overridepublic boolean isEmpty(){return size==0;}//向二分搜索树中添加新的元素(key ,value)@Overridepublic void add(K key,V value){root = add(root,key,value);}//向node为根的二分搜索树中插入元素(key,value),递归算法//返回插入新节点后二分搜索树的根private Node add(Node node,K key,V value){if(node == null){size++;return new Node(key,value);}if(key.compareTo(node.key)<0){node.left = add(node.left,key,value);}else if(key.compareTo(node.key)>0){node.right = add(node.right,key,value);}else if(key.compareTo(node.key)==0){node.value=value;}return node;}//返回以node为节点的二分搜索树中,key所在的节点private Node getNode(Node node,K key){if(node==null){return null;}if(key.compareTo(node.key)==0){return node;}else if(key.compareTo(node.key)<0){return getNode(node.left,key);}elsereturn getNode(node.right,key);}@Overridepublic boolean contains(K key){return getNode(root,key) != null;}@Overridepublic V get(K key){Node node=getNode(root,key);return node == null? null : node.value;}@Overridepublic void set(K key,V newValue){Node node = getNode(root,key);if(node == null){throw new IllegalArgumentException(key + "doesn't exist");}node.value = newValue;}//返回以node为根的二分搜索树的最小值所在的节点private Node minimum(Node node){if(node.left==null){return node;}return minimum(node.left);}//删除掉以node为根的二分搜索树中的最小节点//返回删除节点后新的二分搜索树的根private Node removeMin(Node node){if(node.left == null){Node rightNode = node.right;node.right=null;size--;return rightNode;}node.left = removeMin(node.left);return node;}//从二分搜索树中删除键为key的节点@Overridepublic V remove(K key){Node node = getNode(root,key);if(node != null){root = remove(root,key);return node.value;}return null;}//删除掉以node为根的二分搜索树中键为key的节点,递归算法//返回删除节点后新的二分搜索树的根private Node remove(Node node,K key){if(node==null){return null;}if(key.compareTo(node.key)<0){node.left = remove(node.left,key);return node;}else if(key.compareTo(node.key)>0){node.right = remove(node.right,key);return node;}else{ //key.compareTo(node.key)==0//删除节点左子树为空的情况if(node.left == null){Node rightNode = node.right;node.right = null;size--;return rightNode;}//删除节点右子树为空的情况if(node.right == null){Node leftNode = node.left;node.left = null;size--;return leftNode;}//待删除节点左右子树均不为空的情况//找到比待删除节点大的最小节点,即待删除节点右子树的最小节点//用这个节点顶替待删除节点的位置Node successor = minimum(node.right);successor.right = removeMin(node.right);successor.left = node.left;node.left = node.right = null;return successor;}}}
七、优先队列(PriorityQueue)和堆(Heap)
优先队列:出队顺序和入队顺序无关;和优先级相关。可以简单的理解为,医院中,医生会根据患者生病的程度大小来进行手术,较为严重的患者,相对来说,优先级更高一些,所以医生会对他先进行手术。
7.1使用二叉树来表示堆,简称二叉堆
1.二叉堆是一棵完全二叉树(将元素按一层一层的顺序排列成树的形状)
2.二叉堆中某个节点的值总是不大于其父亲节点的值,称其为最大堆
3.满二叉树就是除了叶子节点,左右孩子都不为空
4.完全二叉树不一定是一个满的二叉树,缺失节点的那一部分一定是整棵树的右下侧

7.2利用数组实现最大堆
import java.util.IllformedLocaleException;public class MaxHeap<E extends Comparable<E>> {private Array<E> data;public MaxHeap(int capacity){data = new Array<>(capacity);}public MaxHeap(){data = new Array<>();}//将任意数组整理成堆的形状public MaxHeap(E[] arr){data = new Array<>(arr);for(int i = parent(arr.length-1);i>=0;i--){siftDown(i);}}//返回堆中的元素个数public int size(){return data.getSize();}//返回一个布尔值,表示堆中是否为空public boolean isEmpty(){return data.isEmpty();}//返回完全二叉树的数组表示中,一个索引所表示的元素的父亲节点的索引private int parent(int index){if(index==0){throw new IllegalArgumentException("index-0 doesn't have parent");}return (index-1)/2;}//返回完全二叉树的数组表示中,一个索引所表示的元素的左孩子节点的索引private int leftChild(int index){return index*2+1;}//返回完全二叉树的数组表示中,一个索引所表示的元素的右孩子节点的索引private int rightChild(int index){return index*2+2;}//向堆中添加元素public void add(E e){data.addLast(e);siftUp(data.getSize()-1);}//上移元素private void siftUp(int k){while(k>0 && data.get(parent(k)).compareTo(data.get(k))<0){data.swap(k,parent(k));k=parent(k);}}//看堆中的最大元素public E findMax(){if(data.getSize() == 0){throw new IllformedLocaleException("heap is empty");}return data.get(0);}//取出堆中最大元素public E extractMax(){E ret = findMax();data.swap(0,data.getSize()-1);data.removeLast();siftDown(0);return ret;}//向下移动private void siftDown(int k){while(leftChild(k)<data.getSize()){int j = leftChild(k);if(j+1 < data.getSize() && data.get(j+1).compareTo(data.get(j))>0){j = rightChild(k);//data[j]是leftChild和rightChild中的最大值}if(data.get(k).compareTo(data.get(j))>=0){break;}data.swap(k,j);k=j;}}//取出堆中的最大元素,并且替换成元素epublic E replace(E e){E ret = findMax();data.set(0,e);return ret;}}
测试用Heapify与不用Heapify的性能差别
import java.util.Random;public class Main {private static double testHeap(Integer[] testData,boolean isHeapify){long startTime = System.nanoTime();MaxHeap<Integer> maxHeap;if(isHeapify){maxHeap = new MaxHeap<>(testData);}else{maxHeap = new MaxHeap<>();for(int num: testData){maxHeap.add(num);}}int[] arr = new int[testData.length];for(int i=0;i<testData.length;i++){arr[i] = maxHeap.extractMax();}for(int i=1;i<testData.length;i++){if(arr[i-1]<arr[i]){throw new IllegalArgumentException("Error");}}System.out.println("Test MaxHeap completed");long endTime = System.nanoTime();return (endTime-startTime)/1000000000.0;}public static void main(String[] args){int n=1000000;Random random = new Random();Integer[] testData = new Integer[n];for(int i=0;i<n;i++){testData[i] = random.nextInt(Integer.MAX_VALUE);}double time1 = testHeap(testData,false);System.out.println("Without heapify: " +time1+ "s");double time2 = testHeap(testData,true);System.out.println("With heapify: " +time2+ "s");}}
测试结果:
用了Heapify(将任意数组整理成堆的形状)的耗时短一些
7.3基于堆的优先队列
public class PriorityQueue<E extends Comparable<E>> implements Queue<E> {private MaxHeap<E> maxHeap;public PriorityQueue(){maxHeap = new MaxHeap<>();}@Overridepublic int getSize(){return maxHeap.size();}@Overridepublic boolean isEmpty(){return maxHeap.isEmpty();}@Overridepublic E getFront(){return maxHeap.findMax();}//入队@Overridepublic void enqueue(E e){maxHeap.add(e);}//出队@Overridepublic E dequeue(){return maxHeap.extractMax();}}
八、线段树(Segment Tree)、区间树
8.1关于线段树
线段树就是对每一棵二叉树的每一个节点存储的是一个线段或者是一个区间相应的信息。
1.线段树不一定是满二叉树,也不一定是完全二叉树
2.线段树是平衡二叉树(对于整棵树来说,最大的深度和最小的深度他们之间的差最多只有可能为1)
8.2实现线段树
创建merger接口
public interface Merger<E> {E merge(E a,E b);}
创建线段树类
package _SegmentTree;import java.lang.management.BufferPoolMXBean;public class SegmentTree<E> {private E[] tree;private E[] data;private Merger<E> merger;public SegmentTree(E[] arr,Merger<E> merger){this.merger=merger;data =(E[]) new Object[arr.length];for(int i=0;i<arr.length;i++){data[i]=arr[i];}tree =(E[]) new Object[4*arr.length];buildSegmentTree(0,0,data.length-1);}//在treeIndex的位置创建表示区间[l...r]的线段树private void buildSegmentTree(int treeIndex,int l,int r){if(l==r){tree[treeIndex] = data[l];return;}int leftTreeIndex = leftChild(treeIndex);int rightTreeIndex = rightChild(treeIndex);int mid = l + (r-l)/2;buildSegmentTree(leftTreeIndex,l,mid);buildSegmentTree(rightTreeIndex,mid+1,r);tree[treeIndex] = merger.merge(tree[leftTreeIndex] , tree[rightTreeIndex]);}public int getSize(){return data.length;}public E get(int index){if(index<0 || index>=data.length){throw new IllegalArgumentException("Index is illegal");}return data[index];}//返回完全二叉树的数组表示中,一个索引所表示的元素的左孩子节点的索引private int leftChild(int index){return 2*index + 1;}//返回完全二叉树的数组表示中,一个索引所表示的元素的右孩子节点的索引private int rightChild(int index){return 2*index + 2;}//返回区间[queryL,queryR]的值(求和过程)public E query(int queryL,int queryR){if(queryL<0 || queryL >=data.length || queryR <0 || queryR >=data.length || queryL > queryR){throw new IllegalArgumentException("index is illegal");}return query(0,0,data.length-1,queryL,queryR);}//在一treeID为根的线段树中[l...r]的范围里,搜索区间[queryL...queryR]的值private E query(int treeIndex,int l,int r,int queryL,int queryR){if(l==queryL && r==queryR){return tree[treeIndex];}int mid = l+(r-l)/2;int leftTreeIndex=leftChild(treeIndex);int rightTreeIndex=rightChild(treeIndex);if(queryL >= mid+1){return query(rightTreeIndex,mid+1,r,queryL,queryR);}else if(queryR <= mid){return query(leftTreeIndex,l,mid,queryL,queryR);}E leftResult = query(leftTreeIndex,l,mid,queryL,mid);E rightResult = query(rightTreeIndex,mid+1,r,mid+1,queryR);return merger.merge(leftResult,rightResult);}//将index位置的值,跟新为epublic void set(int index,E e){if(index < 0 || index >= data.length){throw new IllegalArgumentException("Index is illegal");}data[index] = e;set(0,0,data.length-1,index,e);}//在以treeIndex为根的线段树中跟新index的值为eprivate void set(int treeIndex,int l,int r,int index,E e){if(l==r){tree[treeIndex] = e;return;}int mid = l+(r-l)/2;int leftTreeIndex = leftChild(treeIndex);int rightTreeIndex = rightChild(treeIndex);if(index >= mid + 1){set(rightTreeIndex,mid+1,r,index,e);}else{ //index<=midset(leftTreeIndex,l,mid,index,e);}tree[treeIndex]=merger.merge(tree[leftTreeIndex],tree[rightTreeIndex]);}@Overridepublic String toString(){StringBuilder res = new StringBuilder();res.append('[');for(int i=0;i<tree.length;i++){if(tree[i] != null){res.append(tree[i]);}else{res.append("null");}if(i != tree.length-1){res.append(',');}}res.append(']');return res.toString();}}
测试求和
package _SegmentTree;public class Main {public static void main(String[] args){Integer[] nums = { -2,0,3,-5,2,-1};SegmentTree<Integer> segTree = new SegmentTree<>(nums,(a,b) -> a+b);System.out.println(segTree.query(0,2)); //index从0-2的元素的和}}
输出结果
九、字典树(Trie),也叫做前缀树
可以将字典树简单的理解为字典,从而去查询对应节点所指的对应元素,从而找出所对应的单词。
9.1字典树的实现
字典树的实现主要用于处理一些字符串问题!
package _Trie;import java.util.TreeMap;public class Trie {private class Node{public boolean isWord;public TreeMap<Character,Node> next;public Node(boolean isWord){this.isWord=isWord;next = new TreeMap<>();}public Node(){this(false);}}private Node root;private int size;public Trie(){root = new Node();size = 0;}//获得Trie中存储的单词数量public int getSize(){return size;}//向Trie中添加一个新的单词wordpublic void add(String word){Node cur = root;for(int i=0;i<word.length();i++){char c = word.charAt(i);if(cur.next.get(c) == null){cur.next.put(c,new Node());}cur = cur.next.get(c);}if(!cur.isWord){cur.isWord=true;size++;}}//查询单词word是否在Trie中public boolean contains(String word){Node cur = root;for(int i=0;i<word.length();i++){char c = word.charAt(i);if(cur.next.get(c) == null){return false;}cur = cur.next.get(c);}return cur.isWord;}//前缀查询//查询是否在Trie中有单词以prefix为前缀public boolean isPrefix(String prefix){Node cur = root;for(int i=0;i<prefix.length();i++){char c=prefix.charAt(i);if(cur.next.get(c)==null){return false;}cur =cur.next.get(c);}return true;}}
十、并查集(Union Find)
由孩子指向父亲的树形结构,用来处理连接问题(判断节点间的连接状态)。
10.1数组模拟实现并查集
package _UnionFind;//第一版的Union-Findpublic class UnionFind1 implements UF{private int[] id;public UnionFind1(int size){id=new int[size];for(int i=0;i<id.length;i++){id[i]=i;}}@Overridepublic int getSize(){return id.length;}//查找元素p所对应的集合编号private int find(int p){if(p<0 && p>= id.length){throw new IllegalArgumentException("p is out of bound");}return id[p];}//查看元素p和元素q是否所属一个集合@Overridepublic boolean isConnected(int p,int q){return find(p) == find(q);}//合并元素p和元素q所属的集合@Overridepublic void unionElements(int p,int q){int pID = find(p);int qID = find(q);if(pID == qID){return;}for(int i=0;i<id.length;i++){if(id[i]==pID){id[i]=qID;}}}}
10.2用孩子指向树的结构实现并查集

package _UnionFind;//第二版并查集public class UnionFind2 implements UF {private int[] parent;public UnionFind2(int size){parent = new int[size];for(int i=0;i<size;i++){parent[i] = i; //节点初始化,让每个节点都指向自身}}@Overridepublic int getSize(){return parent.length;}//查找过程,查找元素p所对应的集合编号//O(h)复杂度,h为树的高度private int find(int p){if(p<0 && p>= parent.length){throw new IllegalArgumentException("p is out of bound");}while (p != parent[p]){p = parent[p];}return p;}//产看元素p和元素q是否所属一个集合//O(h)复杂度,h为树的高度@Overridepublic boolean isConnected(int p,int q){return find(p) == find(q);}//合并元素p和合并元素q所属的集合//O(h)复杂度,h为树的高度@Overridepublic void unionElements(int p,int q){int pRoot = find(p);int qRoot = find(q);if(pRoot == qRoot){return;}parent[pRoot] = qRoot;}}
10.3基于size的优化
package _UnionFind;//第三版并查集public class UnionFind3 implements UF {private int[] parent;private int[] sz; //sz[i]表示以i为根的集合中元素个数public UnionFind3(int size){parent = new int[size];sz = new int[size];for(int i=0;i<size;i++){parent[i] = i; //节点初始化,让每个节点都指向自身sz[i] = 1;}}@Overridepublic int getSize(){return parent.length;}//查找过程,查找元素p所对应的集合编号//O(h)复杂度,h为树的高度private int find(int p){if(p<0 && p>= parent.length){throw new IllegalArgumentException("p is out of bound");}while (p != parent[p]){p = parent[p];}return p;}//产看元素p和元素q是否所属一个集合//O(h)复杂度,h为树的高度@Overridepublic boolean isConnected(int p,int q){return find(p) == find(q);}//合并元素p和合并元素q所属的集合//O(h)复杂度,h为树的高度@Overridepublic void unionElements(int p,int q) {int pRoot = find(p);int qRoot = find(q);if (pRoot == qRoot) {return;}//根据两个元素所在树的元素个数不同判断合并方向//将元素个数少的集合合并到元素个数多的集合上if (sz[pRoot] < sz[qRoot]) {parent[pRoot] = qRoot;sz[qRoot] += sz[pRoot];}else{ //sz[qRoot] <= sz[pRoot]parent[qRoot] = pRoot;sz[pRoot] += sz[qRoot];}}}
10.4基于rank(指树的高度)的优化
让节点树高度低的指向节点树高度高的
package _UnionFind;//第四版并查集public class UnionFind4 implements UF {private int[] parent;private int[] rank; //rank[i]表示以i为根的集合所表示的树的层数public UnionFind4(int size){parent = new int[size];rank = new int[size];for(int i=0;i<size;i++){parent[i] = i; //节点初始化,让每个节点都指向自身rank[i] = 1; //节点层数为1}}@Overridepublic int getSize(){return parent.length;}//查找过程,查找元素p所对应的集合编号//O(h)复杂度,h为树的高度private int find(int p){if(p<0 && p>= parent.length){throw new IllegalArgumentException("p is out of bound");}while (p != parent[p]){p = parent[p];}return p;}//产看元素p和元素q是否所属一个集合//O(h)复杂度,h为树的高度@Overridepublic boolean isConnected(int p,int q){return find(p) == find(q);}//合并元素p和合并元素q所属的集合//O(h)复杂度,h为树的高度@Overridepublic void unionElements(int p,int q) {int pRoot = find(p);int qRoot = find(q);if (pRoot == qRoot) {return;}//根据两个元素所在树的rank不同判断合并方向//将rank低的集合合并到rank高的集合上if (rank[pRoot] < rank[qRoot]) {parent[pRoot] = qRoot;}else if(rank[qRoot] < rank[pRoot]){parent[qRoot] = pRoot;}else{ //RANK[qRoot] == rank[pRoot]parent[qRoot] = pRoot;rank[pRoot] += 1;}}}
10.5路径压缩

package _UnionFind;//第五版并查集public class UnionFind5 implements UF {private int[] parent;private int[] rank; //rank[i]表示以i为根的集合所表示的树的层数public UnionFind5(int size){parent = new int[size];rank = new int[size];for(int i=0;i<size;i++){parent[i] = i; //节点初始化,让每个节点都指向自身rank[i] = 1; //节点层数为1}}@Overridepublic int getSize(){return parent.length;}//查找过程,查找元素p所对应的集合编号//O(h)复杂度,h为树的高度private int find(int p){if(p<0 && p>= parent.length){throw new IllegalArgumentException("p is out of bound");}while (p != parent[p]){parent[p] = parent[parent[p]];p = parent[p];}return p;}//产看元素p和元素q是否所属一个集合//O(h)复杂度,h为树的高度@Overridepublic boolean isConnected(int p,int q){return find(p) == find(q);}//合并元素p和合并元素q所属的集合//O(h)复杂度,h为树的高度@Overridepublic void unionElements(int p,int q) {int pRoot = find(p);int qRoot = find(q);if (pRoot == qRoot) {return;}//根据两个元素所在树的rank不同判断合并方向//将rank低的集合合并到rank高的集合上if (rank[pRoot] < rank[qRoot]) {parent[pRoot] = qRoot;}else if(rank[qRoot] < rank[pRoot]){parent[qRoot] = pRoot;}else{ //RANK[qRoot] == rank[pRoot]parent[qRoot] = pRoot;rank[pRoot] += 1;}}}

package _UnionFind;//第六版并查集public class UnionFind6 implements UF {private int[] parent;private int[] rank; //rank[i]表示以i为根的集合所表示的树的层数public UnionFind6(int size){parent = new int[size];rank = new int[size];for(int i=0;i<size;i++){parent[i] = i; //节点初始化,让每个节点都指向自身rank[i] = 1; //节点层数为1}}@Overridepublic int getSize(){return parent.length;}//查找过程,查找元素p所对应的集合编号//O(h)复杂度,h为树的高度private int find(int p){if(p<0 && p>= parent.length){throw new IllegalArgumentException("p is out of bound");}if(p != parent[p]){parent[p] = find(parent[p]);}return parent[p];}//产看元素p和元素q是否所属一个集合//O(h)复杂度,h为树的高度@Overridepublic boolean isConnected(int p,int q){return find(p) == find(q);}//合并元素p和合并元素q所属的集合//O(h)复杂度,h为树的高度@Overridepublic void unionElements(int p,int q) {int pRoot = find(p);int qRoot = find(q);if (pRoot == qRoot) {return;}//根据两个元素所在树的rank不同判断合并方向//将rank低的集合合并到rank高的集合上if (rank[pRoot] < rank[qRoot]) {parent[pRoot] = qRoot;}else if(rank[qRoot] < rank[pRoot]){parent[qRoot] = pRoot;}else{ //RANK[qRoot] == rank[pRoot]parent[qRoot] = pRoot;rank[pRoot] += 1;}}}
测试性能
package _UnionFind;import java.util.Random;public class Main {private static double testUF(UF uf,int m){int size = uf.getSize();Random random = new Random();long startTime = System.nanoTime();for(int i=0;i<m;i++){int a = random.nextInt(size);int b = random.nextInt(size);uf.unionElements(a,b);}for(int i=0;i<m;i++){int a = random.nextInt(size);int b = random.nextInt(size);uf.isConnected(a,b);}long endTime = System.nanoTime();return (endTime-startTime)/1000000000.0;}public static void main(String[] args){int size = 100000;int m = 100000;UnionFind1 uf1 = new UnionFind1(size);System.out.println("UnionFind1 :" +testUF(uf1,m) + "s");UnionFind2 uf2 = new UnionFind2(size);System.out.println("UnionFind2 :" +testUF(uf2,m) + "s");UnionFind3 uf3 = new UnionFind3(size);System.out.println("UnionFind3 :" +testUF(uf3,m) + "s");UnionFind4 uf4 = new UnionFind4(size);System.out.println("UnionFind4 :" +testUF(uf4,m) + "s");UnionFind5 uf5 = new UnionFind5(size);System.out.println("UnionFind5 :" +testUF(uf5,m) + "s");UnionFind6 uf6 = new UnionFind6(size);System.out.println("UnionFind6 :" +testUF(uf6,m) + "s");}}
测试结果
可以将size和m继续增大,效果可能会明显一些
十一、AVL树、平衡二叉树
1.平衡二叉树:对于任意一个节点,左子树和右子树的高度差不能超过1
2.平衡因子:任意节点而言,左右子树高度差,计算高度差用左子树的高度减去右子树的高度
11.1AVL树的实现
以下代码实现了AVL树,计算节点的高度和平衡因子,以及AVL的删除元素,以及左右旋转的实现
package _AVLTree;import _Map.Map;import java.util.ArrayList;public class AVLTree<K extends Comparable<K>,V> implements Map<K,V>{private class Node{public K key;public V value;public Node left,right;public int height;public Node(K key,V value){this.key=key;this.value=value;left=null;right=null;height=1;}}private Node root;private int size;public AVLTree(){root=null;size=0;}@Overridepublic int getSize(){return size;}@Overridepublic boolean isEmpty(){return size==0;}//判断该二叉树是否是二分搜索树public boolean isBST(){ArrayList<K> keys = new ArrayList<>();inOrder(root,keys);for(int i=1;i<keys.size();i++){if(keys.get(i-1).compareTo(keys.get(i)) > 0){return false;}}return true;}private void inOrder(Node node,ArrayList<K> keys){if(node == null){return;}inOrder(node.left,keys);keys.add(node.key);inOrder(node.right,keys);}//判断该二叉树是否是平衡二叉树public boolean isBalanced(){return isBalanced();}//判断以Node为根的二叉树是否是平衡二叉树,递归算法private boolean isBalanced(Node node){if(node == null){return true;}int balanceFactor = getBalanceFactor(node);if(Math.abs(balanceFactor) > 1){return false;}return isBalanced(node.left) && isBalanced(node.right);}//获得节点的高度private int getHeight(Node node){if(node==null){return 0;}return node.height;}//获得节点node的平衡因子private int getBalanceFactor(Node node){if(node == null){return 0;}return getHeight(node.left) - getHeight(node.right);}//插入的元素在不平衡的节点的左侧的左侧//对节点y进行向右旋转操作,返回旋转后新的根节点x// y x// / \ / \// x T4 向右旋转(y) z y// / \ ---------------> /\ /\// z T3 T1 T2 T3 T4// / \// T1 T2private Node rightRotate(Node y){Node x = y.left;Node T3 = x.right;//向右旋转过程x.right = y;y.left = T3;//跟新heighty.height = Math.max(getHeight(y.left),getHeight(y.right)) + 1;x.height = Math.max(getHeight(x.left),getHeight(x.right)) + 1;return x;}//插入的元素在不平衡的节点的右侧的右侧//对节点y进行向左旋转操作,返回旋转后新的根节点x// y x// / \ / \// T1 x 向左旋转(y) y z// / \ --------------> / \ / \// T2 z T1 T2 T3 T4// / \// T3 T4private Node leftRotate(Node y){Node x = y.right;Node T2 = x.left;//向左旋转过程x.left = y;y.right = T2;//跟新heighty.height = Math.max(getHeight(y.left),getHeight(y.right)) + 1;x.height = Math.max(getHeight(x.left),getHeight(x.right)) + 1;return x;}//向二分搜索树中添加新的元素(key ,value)@Overridepublic void add(K key,V value){root = add(root,key,value);}//向node为根的二分搜索树中插入元素(key,value),递归算法//返回插入新节点后二分搜索树的根private Node add(Node node,K key,V value){if(node == null){size++;return new Node(key,value);}if(key.compareTo(node.key)<0){node.left = add(node.left,key,value);}else if(key.compareTo(node.key)>0){node.right = add(node.right,key,value);}else { //key.compareTo(node.key}==0node.value=value;}//更新heightnode.height = 1 + Math.max(getHeight(node.left),getHeight(node.right));//计算平衡因子int balanceFactor = getBalanceFactor(node);if(Math.abs(balanceFactor) > 1){System.out.println("unbalanced :" + balanceFactor);}//平衡维护//LLif(balanceFactor > 1 && getBalanceFactor(node.left) >= 0){return rightRotate(node);}//RRif(balanceFactor < -1 && getBalanceFactor(node.right) <= 0){return leftRotate(node);}//LRif(balanceFactor > 1 && getBalanceFactor(node.left) < 0){node.left = leftRotate(node.left);return rightRotate(node);}//RLif(balanceFactor < -1 && getBalanceFactor(node.right) > 0){node.right = rightRotate(node.right);return leftRotate(node);}return node;}//返回以node为节点的二分搜索树中,key所在的节点private Node getNode(Node node,K key){if(node==null){return null;}if(key.compareTo(node.key)==0){return node;}else if(key.compareTo(node.key)<0){return getNode(node.left,key);}elsereturn getNode(node.right,key);}@Overridepublic boolean contains(K key){return getNode(root,key) != null;}@Overridepublic V get(K key){Node node=getNode(root,key);return node == null? null : node.value;}@Overridepublic void set(K key,V newValue){Node node = getNode(root,key);if(node == null){throw new IllegalArgumentException(key + "doesn't exist");}node.value = newValue;}//返回以node为根的二分搜索树的最小值所在的节点private Node minimum(Node node){if(node.left==null){return node;}return minimum(node.left);}//从二分搜索树中删除键为key的节点@Overridepublic V remove(K key){Node node = getNode(root,key);if(node != null){root = remove(root,key);return node.value;}return null;}//删除掉以node为根的二分搜索树中键为key的节点,递归算法//返回删除节点后新的二分搜索树的根private Node remove(Node node,K key){if(node==null){return null;}Node retNode;if(key.compareTo(node.key)<0){node.left = remove(node.left,key);retNode = node;}else if(key.compareTo(node.key)>0){node.right = remove(node.right,key);retNode = node;}else { //key.compareTo(node.key)==0//删除节点左子树为空的情况if (node.left == null) {Node rightNode = node.right;node.right = null;size--;retNode = rightNode;}//删除节点右子树为空的情况else if (node.right == null) {Node leftNode = node.left;node.left = null;size--;retNode = leftNode;} else { //待删除节点左右子树均不为空的情况//找到比待删除节点大的最小节点,即待删除节点右子树的最小节点//用这个节点顶替待删除节点的位置Node successor = minimum(node.right);successor.right = remove(node.right, successor.key);successor.left = node.left;node.left = node.right = null;retNode = successor;}}if(retNode==null){return null;}//更新heightretNode.height = 1 + Math.max(getHeight(retNode.left),getHeight(retNode.right));//计算平衡因子int balanceFactor = getBalanceFactor(retNode);//平衡维护//LLif(balanceFactor > 1 && getBalanceFactor(retNode.left) >= 0){return rightRotate(retNode);}//RRif(balanceFactor < -1 && getBalanceFactor(retNode.right) <= 0){return leftRotate(retNode);}//LRif(balanceFactor > 1 && getBalanceFactor(retNode.left) < 0){retNode.left = leftRotate(retNode.left);return rightRotate(retNode);}//RLif(balanceFactor < -1 && getBalanceFactor(retNode.right) > 0){retNode.right = rightRotate(retNode.right);return leftRotate(retNode);}return retNode;}}
11.2基于AVL树的映射实现
package _Map;public class AVLMap<K extends Comparable<K>,V> implements Map<K,V> {private AVLTree<K,V> avl;public AVLMap(){avl = new AVLTree<>();}@Overridepublic int getSize(){return avl.getSize();}@Overridepublic boolean isEmpty(){return avl.isEmpty();}@Overridepublic void add(K key,V value){avl.add(key,value);}@Overridepublic boolean contains(K key){return avl.contains(key);}@Overridepublic V get(K key){return avl.get(key);}@Overridepublic void set(K key,V newValue){avl.set(key,newValue);}@Overridepublic V remove(K key){return avl.remove(key);}}
11.3基于AVL树的集合实现
package _Set;public class AVLSet<E extends Comparable<E>> implements Set<E> {private AVLTree<E ,Object> avl;public AVLSet(){avl = new AVLTree<>();}@Overridepublic int getSize(){return avl.getSize();}@Overridepublic boolean isEmpty(){return avl.isEmpty();}@Overridepublic void add(E e){avl.add(e,null);}@Overridepublic boolean contains(E e){return avl.contains(e);}@Overridepublic void remove(E e){avl.remove(e);}}
十二、红黑树
12.1关于红黑树
1.红黑树也是二分搜索树
2.每个节点或者是红色的,或者是黑色的
3.根节点是黑色的
4.每个叶子节点(最后的空节点)是黑色的
5.如果一个节点是红色的,那么他的孩子节点都是黑色的
6.从任意一个节点到叶子节点,经过的黑色节点是一样的
7.所有的红色节点都是左倾斜的
12.2 2-3树
1.2-3树满足二分搜索树的基本性质,但是它不是二叉树
2.节点可以存放一个元素或者两个元素
3.每个节点有2个孩子或者3个孩子
4.2-3树是一棵绝对平衡的树
5.2-3树在添加节点时,如果那一个元素为根节点的话会发生节点的融合现象

该图所对应的红黑树为:
12.3 2-3树添加元素的过程
添加的宗旨就是不直接添加到根节点为空的情况,若为空,需要进行融合,融合后为保持树的平衡,需要进行分裂




12.4红黑树的实现
**package RedBlackTree;import _Map.BSTMap;public class RBTree<K extends Comparable<K> ,V> {private static final boolean RED = true;private static final boolean BLACK = false;private class Node{public K key;public V value;public Node left,right;public boolean color;public Node(K key,V value){this.key = key;this.value = value;left = null;right = null;}}private Node root;private int size;public RBTree(){root = null;size = 0;}public int getSize(){return size;}public boolean isEmpty(){return size == 0;}//判断节点node的颜色private boolean isRed(Node node){if(node == null){return BLACK;}return node.color;}// node x// / \ 左旋转 / \// T1 x ---------> node T3// / \ / \// T2 T3 T1 T2private Node leftRotate(Node node){Node x = node.right;//左旋转node.right = x.left;x.left = node;x.color = node.color;node.color = RED;return x;}// node x// / \ 右旋转 / \// x T2 --------> y node// / \ / \// y T1 T1 T2private Node rightRotate(Node node){Node x = node.left;//右旋转node.left = x.right;x.right = node;x.color = node.color;node.color = RED;return x;}//颜色翻转private void flipColors(Node node){node.color = RED;node.left.color = BLACK;node.right.color = BLACK;}//向红黑树中添加新的元素(key,value)public void add(K key, V value){root = add(root,key,value);root.color = BLACK; //最终根节点为黑色节点}//向以node为根的红黑树中插入元素(key, value),递归算法//返回插入新节点后红黑树的根private Node add(Node node,K key,V value){if(node == null){size++;return new Node(key,value); //默认插入红色节点}if(key.compareTo(node.key) < 0){node.left = add(node.left,key,value);}else if(key.compareTo(node.key) > 0){node.right = add(node.right,key,value);}else{ //key.compareTo(node.key) == 0node.value = value;}if(isRed(node.right) && !isRed(node.left)){node = leftRotate(node);}if(isRed(node.left) && isRed(node.left.left)){node = rightRotate(node);}if(isRed(node.left) && isRed(node.right)){flipColors(node);}return node;}//返回以node为节点的二分搜索树中,key所在的节点private Node getNode(Node node, K key){if(node==null){return null;}if(key.equals(node.key)){return node;}else if(key.compareTo(node.key)<0){return getNode(node.left,key);}else{ //if(key.compareTo(node.key) > 0)return getNode(node.right,key);}}public boolean contains(K key){return getNode(root,key) != null;}public V get(K key){Node node=getNode(root,key);return node == null? null : node.value;}public void set(K key,V newValue){Node node = getNode(root,key);if(node == null){throw new IllegalArgumentException(key + "doesn't exist");}node.value = newValue;}//返回以node为根的二分搜索树的最小值所在的节点private Node minimum(Node node){if(node.left==null){return node;}return minimum(node.left);}//删除掉以node为根的二分搜索树中的最小节点//返回删除节点后新的二分搜索树的根private Node removeMin(Node node){if(node.left == null){Node rightNode = node.right;node.right=null;size--;return rightNode;}node.left = removeMin(node.left);return node;}//从二分搜索树中删除键为key的节点public V remove(K key){Node node = getNode(root,key);if(node != null){root = remove(root,key);return node.value;}return null;}//删除掉以node为根的二分搜索树中键为key的节点,递归算法//返回删除节点后新的二分搜索树的根private Node remove(Node node, K key){if(node==null){return null;}if(key.compareTo(node.key)<0){node.left = remove(node.left,key);return node;}else if(key.compareTo(node.key)>0){node.right = remove(node.right,key);return node;}else{ //key.compareTo(node.key)==0//删除节点左子树为空的情况if(node.left == null){Node rightNode = node.right;node.right = null;size--;return rightNode;}//删除节点右子树为空的情况if(node.right == null){Node leftNode = node.left;node.left = null;size--;return leftNode;}//待删除节点左右子树均不为空的情况//找到比待删除节点大的最小节点,即待删除节点右子树的最小节点//用这个节点顶替待删除节点的位置Node successor = minimum(node.right);successor.right = removeMin(node.right);successor.left = node.left;node.left = node.right = null;return successor;}}}**
12.5红黑树的性能总结
1.对于完全随机的数据,普通的二分搜索树很好用
2.缺点:极端退化成链表(或者高度不平衡)
3.对于查询较多的情况,使用AVL树
4.统计性能更优(增删改查等操作)
十三、哈希表
什么是哈希表?
每个字符都有一个索引相对应。
实现哈希表(增删改查等方法)
package _HashTable;import java.util.TreeMap;public class HashTable<K,V> {private final int[] capacity = { 53,97,193,389,749,1543,3079,6151,12289,24593,19157,98317,196613,393241,786433,1572869,3145739,6291469,12582917,25165843,50331653,100263319,20132611,402653189,805306457,1610612741};private static final int upperTol = 10;private static final int lowerTol = 2;private static int capacityIndex=0;private TreeMap<K,V>[] hashtable;private int M;private int size;public HashTable(int M){this.M =capacity[capacityIndex];size = 0;hashtable = new TreeMap[M];for(int i=0;i<M;i++){hashtable[i] = new TreeMap<>();}}private int hash(K key){return (key.hashCode() & 0x7fffffff) % M;}public int getSize(){return size;}public void add(K key,V value){TreeMap<K,V> map = hashtable[hash(key)];if(map.containsKey(key)){map.put(key,value);}else{map.put(key,value);size++;if(size >= upperTol * M && capacityIndex+1 < capacity.length){capacityIndex++;resize(capacity[capacityIndex]);}}}public V remove(K key){TreeMap<K,V> map = hashtable[hash(key)];V ret = null;if(map.containsKey(key)){ret = map.remove(key);size--;if(size < lowerTol * M && capacityIndex-1 >=0){capacityIndex--;resize(capacity[capacityIndex]);}}return ret;}public void set(K key,V value){TreeMap<K,V> map = hashtable[hash(key)];if(!map.containsKey(key)){throw new IllegalArgumentException(key + "doesn't exist");}map.put(key,value);}public boolean contains(K key){return hashtable[hash(key)].containsKey(key);}public V get(K key){return hashtable[hash(key)].get(key);}private void resize(int newM){TreeMap<K,V>[] newHashTable = new TreeMap[newM];for(int i=0;i<newM;i++){newHashTable[i] = new TreeMap<>();}int oldM=M;this.M = newM;for(int i=0;i<oldM;i++){TreeMap<K,V> map = hashtable[i];for(K key:map.keySet()){newHashTable[hash(key)].put(key,map.get(key));}}this.hashtable=newHashTable;}}





























")




还没有评论,来说两句吧...