MySQL快速上手[学习笔记](二)
前言:
课程:《三大主流数据库快速上手》(点击跳转官方课程,b站有资源,可自搜)
笔记(点击跳转豆丁网)
此处是个人学习笔记,用作回顾用途
目录:
四、索引
五、增删改
六、SQL语句
四、索引
(一)概念:定义:对数据库表中的一列或者多列的值进行排序的一种结构,旨在提高数据的查询效率。
比喻:查询字典,若没有索引,会从整个字典中查找,若有索引,在该索引区域查找。
(二)分类
1、普通索引
不需要添加任何限制条件,可以创建在任何数据类型中,由字段本身的完整性约束决定。
2、唯一索引
使用 unique 参数进行设置,该值必须是唯一的。(主键是一种特殊的唯一索引)
3、全文索引
使用 fulltext 参数进行设置,只能创建在 char,varchar 或者 text 类型的字段上(适用于查询数据
量较大的字符串类型的字符时)
4、单列索引
在表中单个字段上创建,只能根据该字段进行索引查询,只要保证该索引只对应一个字段即可。
5、多列索引
在表中多个字段上创建,可根据多个字段进行索引查询(注意:只有查询条件中使用了这些字段中的第一个字段时,索引才会被使用)
例如:id name age,查询条件使用了 id 字段时该索引才会被使用
6、空间索引(用的比较少)
使用 spatial 参数进行设置,只能建立在空间数据类型上。(geometry、point、linestring 和 polygon
等)
(三)设计原则
1、选择唯一索引
唯一索引的值是唯一的,可快速通过该索引来确定某条记录
例如:人–>身份证号 学生–>学号
2、为经常需要排序、分组和联合操作的字段建立索引
频繁使用 order by、group by、distinct 和 union 等来操作字段时
3、经常作为查询条件的字段建立索引
4、限制索引的数目
索引的数目并不是越多越好,每个索引都要占用磁盘空间,修改表时,对索引的重构和更新比较麻烦。
5、尽量使用数据量少的索引
varchar(10) varchar(255)
6、尽量使用前缀来索引
检索值很长时,比如 text、blog,只检索前面的若干个字符
7、不使用或使用频率低的,应尽快删除(作为参考,不仅限于)
(四)Mysql的存储引擎和索引(点击标题可转到参考文章)
mysql内部索引是由不同的引擎实现的,主要说一下InnoDB和MyISAM这两种引擎中的索引,这两种引擎中的索引都是使用b+树的结构来存储的。
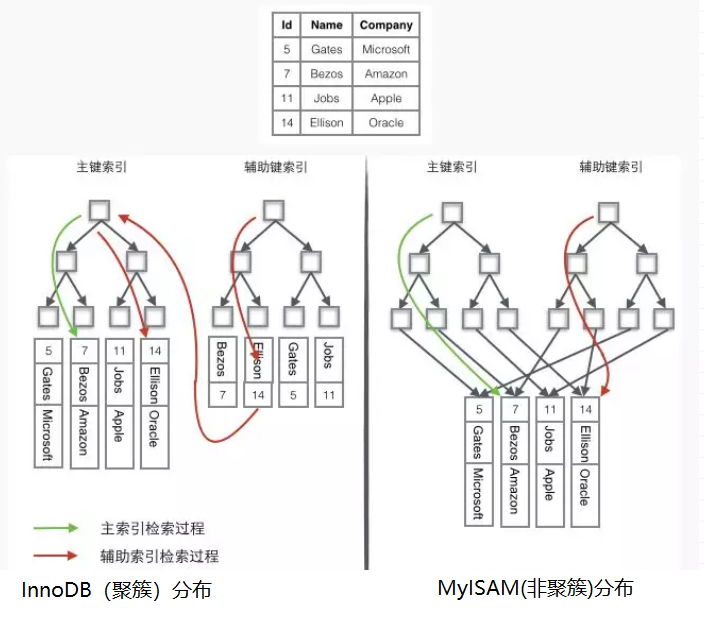
(1)InnoDB中的索引
Innodb中有2种索引:主键索引(聚集索引)、辅助索引(非聚集索引)。
主键索引:每个表只有一个主键索引,叶子节点同时保存了主键的值也数据记录。
辅助索引:叶子节点保存了索引字段的值以及主键的值。
(2)MyISAM引擎中的索引
不管是主键索引还是辅助索引结构都是一样的,叶子节点保存了索引字段的值以及数据记录的地址。
有一张表,Id作为主索引,Name作为辅助索引。
(五)操作索引
1.创建表时创建索引
语法:create table 表名(属性名 数据类型 [完整性约束条件],
…
[unique | fulltext | spatial] index | key[别名](属性名 1[(长度)] [asc | desc]))
①创建普通索引
create table index1(id int,name varchar(20),sex boolean,index(id));
②创建普通索引 unique index
create table index2(id int,name varchar(20),unique index index2_id(id asc));
③创建全文索引 fulltext index
(InnoDB 不支持全文索引,MyISAM 引擎支持)
create table index3(id int,info varchar(20),fulltext index index3_info(info))engine MyISAM;
④创建单列索引 index(id)
create table index4(id int,name varchar(20),index(id));
⑤创建多列索引 index(id,name)
create table index5(id int,name varchar(20),index(id,name));
⑥创建空间索引 spatial index
(MyISAM 引擎支持)
create table index6(id int,space geometry not null,spatial index index4_sp(space))engine MyISAM;
2.在已有列表中创建索引
语法:create [unique | fulltext | spatial] index 索引名
on 表名(属性名 | [长度] [asc | desc]);
①创建普通索引
create index index7_id on exp1(id);
②创建唯一索引 unique index
③创建全文索引 fulltext index
(InnoDB 不支持全文索引,MyISAM 引擎支持)
④创建单列索引 index(id)
⑤创建多列索引 index(id,name)
⑥创建空间索引 spatial index
3.使用alter table 语句创建索引
语法:alter table 表名 add [unique | fulltext | spatial] index 索引名 (属性名 [(长度)] [asc | desc]);
①创建普通索引
alter table exp1 add index index13_name(stu_name(20));
②创建唯一索引 unique index
③创建全文索引 fulltext index
(数据类型需是 char | varchar | text;使用 MyISAM 引擎)
④创建单列索引 index(id)
⑤创建多列索引 index(id,name)
⑥创建空间索引 spatial index
(数据类型需是空间数据类型;使用 MyISAM 引擎)
4.删除引擎
语法:drop index 索引名 on 表名
drop index id on index1;
(注意对于一些不再使用的索引要及时删除,否则会降低更新速度,影响数据性能)
五、增删改
create table product(id int primary key,name varchar(20),functions varchar(20),company varchar(20),address varchar(20));
1.插入数据
①为表的所有字段插入数据
insert 语句不指定字段名
insert into product values(1001,’阿莫西林’,’伤寒’,’云南山制药’,’广州’);
insert 语句列出所有字段
(区别:1.可不指定字段,直接录入值,较为方便,2.指定字段,较为麻烦,但是,灵活,可改变字段的顺序)insert into product(id,name,functions,company,address)
values(1002,’云南白药喷雾’,’跌打损伤’,’云南白药制药’,’云南’);insert into product(id,name,functions,address,company)
values(1003,’感康’,’感冒’,’吉林’,’吴太集团’);
②为表的指定字段插入数据
insert into product(id,name,company) values(1004,'太极急支糖浆','太极集团');
(仅限于可以为空的字段)
insert into product(id,company,name) values(1005,'远东药业','川贝止咳糖浆');
(顺序亦可调换)
③为表同时插入多条数据
语法:insert into 表名 values(…),(…),(…)
insert into product values(1006,'感冒药A','治疗感冒','感冒药业A','上海市某厂'),(1007,'感冒药B','治疗感冒','感冒药业A','上海市某厂'),(1008,'感冒药C','治疗感冒','感冒药业C','上海市某厂');insert into product(id,name,company) values(1009,'止咳1','止咳集团1'),(1010,'止咳2','止咳集团2'),(1011,'止咳3','止咳集团3');
④将查询结果插入到表内
语法:insert into 表 1 (字段列表 1) select 字段列表 2 from 表 2
#查询表格内容select * from product;create table medicine (id int primary key,name varchar(20),functions varchar(20),company varchar(20),address varchar(20));insert into product values(1,'感冒药E','治疗感冒','感冒药业E','上海市某厂'),(2,'感冒药F','治疗感冒','感冒药业F','上海市某厂'),(3,'感冒药G','治疗感冒','感冒药业G','上海市某厂');# 将查询结果插入到表中(注意:字段类型和字段个数要一致)insert into product(id,name,functions,company,address)select id,name,functions,company,address from medicine;
2.更改数据
语法:update 表名 set 字段 1 = 新值 1,字段 2=新值 2,… where 条件表达式
(切记:where 条件不能轻易的丢掉!!!)
update product set name="感冒药B",company="感冒药业B" where id =1007;
3.删除数据
语法:delete from 表名 [where 条件表达式]
delete from product where id = 1001;delete from product where adress="上海市某厂";
不加条件删除则是全部删除:
(切记:where 条件不能轻易的丢掉!!!)
#全删delete from product;
六、SQL语句
1.基本 SQL 查询语句
语法:
select 属性列表
from 表名(视图)列表
[where 条件表达式 1]
[group by 属性名 1 [having 条件表达式 2]]
[order by 属性名 2 [asc | desc]]
asc:升序
desc:降序
2.字段查询
(1)查询所有字段
select * from product;
(建议:为了提高查询效率,尽可能的使用字段来查询,而不用*号)
(2)查询指定字段
可根据需要指定字段,同时字段的顺序也可以改变
select id,name,functions,company from product;
3.查询指定记录
select * from productwhere id >3order by id desc;
4.带 IN 关键字的查询
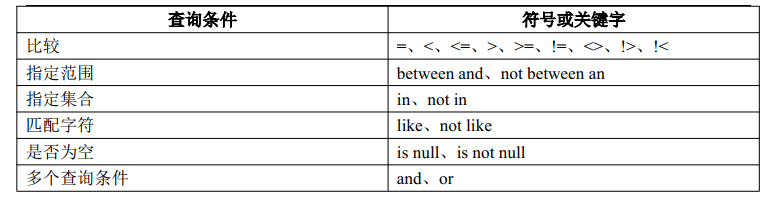
语法:[not] in(元素 1,元素 2,…,元素 n)
select * from product where id in (1002,1004);select * from product where company not in ('云南白药制药','太极集团');
(字符类型一定要加上引号)
5.带 BETWEEN AND 的范围查询
select * from product where id between 1 and 3;select * from product where id not between 1 and 3;
6.带 LIKE 的字符匹配查询
通配符:
%:代表任意长度的字符串,长度可以为 0。
例如:a%c–>表示以字母 a 开头,以字母 c 结尾的任意长度的字符串,可以代表 ac、abc、abdefgc
:只能表示单个字符。a_c–>表示以字母 a 开头,以字母 c 结尾的 3 个字符,中间的“”可以表示任意一个字符,比如:abc、adc、azc
select * from product where name like '感%';select * from product where name like '感_';
7.查询空值
select * from product where address is null;
空值:一种是从未填写过数据,二是填写过数据后删除掉的
UPDATE product SET address = '' where id =3;select * from product where address ='';select * from product where address is not null;
8.带 AND 的多条件查询
必须同时满足条件,只要有一个不满足,则如此记录将会被排除
select * from product where id between 1 and 3 and address like '上海%';
9.带 OR 的多条件查询
无需同时满足条件,只要其中一个条件满足,则记录会被查到,只有条件都不满足时如此记录才会被排除掉。
select * from product where id between 1 and 3 or address like '上海%';
10.查询结果去重 distinct
select distinct address from product;
11.查询结果排序
升序时 asc 可省略,默认是升序
(可以多个字段进行排序,同时各个字段可自由升降序。排序规则:先按第一个字段进行排序,若遇到相同的数据,则根据第二字段进行排序,以此类推)
12. 分组查询
(1)单独使用 group by
会显示每个组的一条记录
select * from product group by effect;
(2)与 group_concat()结合使用
select effect,group_concat(name) from product group by effect;
(3)与聚合函数结合使用
select effec,group_concat(name) from product group by effect having count(effect)>4;
(4)与 having 结合使用
select effec,group_concat(name) from product group by effect having count(effect)>4;
(5)多个字段分组
select * from product group by effect,address;
(6)与 with rollup 结合使用
会加上一条记录,而该记录是查询分组后记录的总和
select effect,group_concat(name) from product group by effect with rollup;select effect,count(name) from product group by effect with rollup;
13. LIMIT 限制查询结果数量
(1)不指定初始化位置
(limit 后面的数字代表限制的条数,若条数小于总记录数,则显示限制的数量,若大于总记录数,则显示全部数据)
select * from product limit 3;select * from product limit 10;
(2)指定初始化位置
select * from product limit 3,10;
(因为不指定时默认从第 1 条数据开始,也就是 0,第 2 条,就是 1,以此类推。limit 可用作分页)
14.聚合函数查询
(1)COUNT(记录数)
select count(id) from product;
(2)SUM(求和)
select sum(id) from product;select sum(name) from product;
(sum 只针对于数值类型进行累加,若累加的是字符(串)类型则结果总是显示 0)
(3)AVG(求平均)
select avg(id) from product;
(4)MAX(最大值)
select max(id) from product;
(5)MIN(最小值)
select min(id) from product;
15.子查询
子查询:将一个查询语句嵌套在另一个查询语句中。内层查询语句的查询结果可为外层查询提供
条件。
create table book(id int primary key,bookname varchar(20),stuid int);create table stu(stuid int primary key,stuname varchar(20));insert book values(1,"python编程",1),(2,"SQL教程",2),(3,"C语言",3),(4,"java编程",4),(6,"web编程",10);insert stu values(1,'张三'),(2,'李四'),(3,'王五'),(4,'任六'),(5,'赵七');
(1)带 IN 关键字
select * from book where stuid in (select stuid from stu);select * from book where stuid not in (select stuid from stu);
(2)带比较运算符
select * from book where stuid = (select stuid from stu where stuname ='李四') ;
(在使用比较运算符时,子查询的结果只能为 1 不能为 N)
(3)带 EXISTS 关键字
exists用于检查子查询是否至少会返回一行数据,该子查询实际上并不返回任何数据,而是返回值True或False。
select * from book where exists (select stuid from stu where stuname ='李四');select * from book where exists (select stuid from stu where stuname ='刘六');
(4)带 ANY 关键字(满足子查询中的其一即可)
select * from book where stuid >any(select stuid from stu);
(5)带 ALL 关键字(满足子查询中的所有)
select * from book where stuid >all(select stuid from stu);
16.合并查询
(1)union(合并查询结果去除重复)
select stuid from bookunionselect stuid from stu;
(2)union all(单纯的合并结果不处理重复数据)
select stuid from bookunion allselect stuid from stu;
17.为表和字段取别名
(1)为表取别名
select * from book as b where b.stuid=1;select * from book b where b.stuid=2;#(as 可省略)
(2)为字段取别名
select b.bookname as bn from book as b;
(同时给字段和表取别名,亦可取中文别名)
select b.bookname as "书名" from book as b;
(注意:但是不能将字段的别名作为查询条件的字段名称来使用)
#(X)select b.bookname as bn from book as b where bn='C语言';
18.连接查询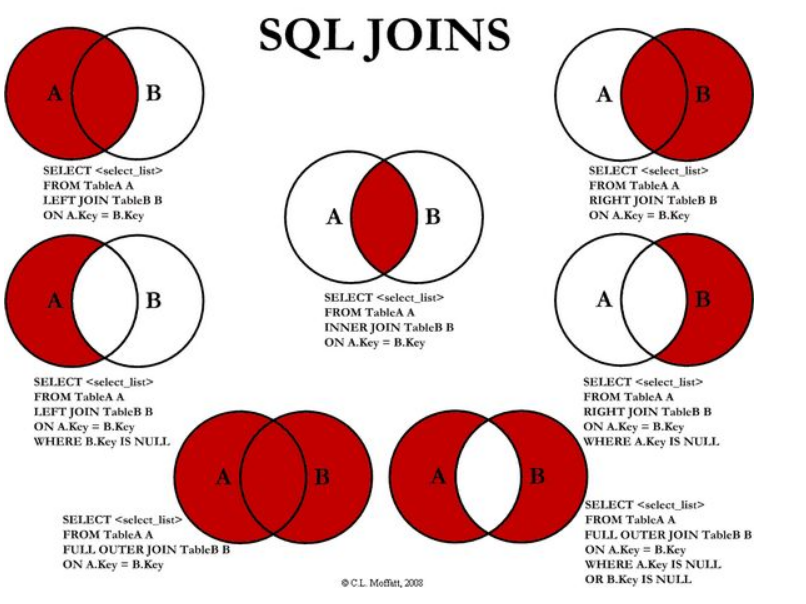
(1)内连接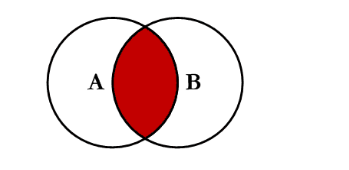
语法:
SELECT
FROM Table_A A
INNER JOIN Table_B B
ON A.Key = B.Key
- 等值连接:在连接条件中使用等于号(=)运算符比较被连接列的列值,其查询结果中列出被连接表中的所有列,包括其中的重复列。
- 不等值连接:在连接条件使用除等于运算符以外的其它比较运算符比较被连接的列的列值。这些运算符包括>、>=、<=、<、!>、!<和<>。
自然连接:在连接条件中使用等于(=)运算符比较被连接列的列值,但它使用选择列表指出查询结果集合中所包括的列,并删除连接表中的重复列。
select * from book as a,stu as b where a.stuid = b.stuid;
select * from book as a inner join stu as b on a.stuid = b.stuid;
内连接可以使用上面两种方式,其中第二种方式的inner可以省略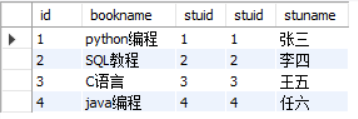
其连接结果如上图,是按照a.stuid = b.stuid进行连接。
内连接:内连接查询操作列出与连接条件匹配的数据行,它使用比较运算符比较被连接列的列值。
(2)左连接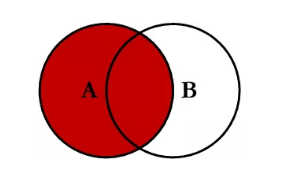
语法:
SELECT
FROM Table_A A
LEFT JOIN Table_B B
ON A.Key = B.Key
select * from book as a left join stu as b on a.stuid = b.stuid;
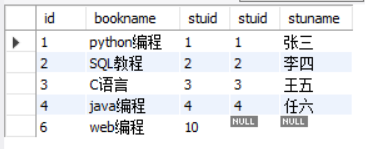
(3)右连接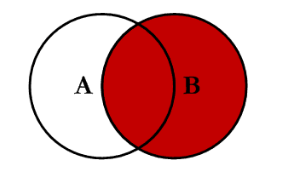
语法:
SELECT
FROM Table_A A
RIGHT JOIN Table_B B
ON A.Key = B.Key
select * from book as a right join stu as b on a.stuid = b.stuid;
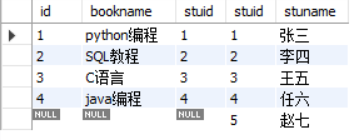
(4)外连接/全连接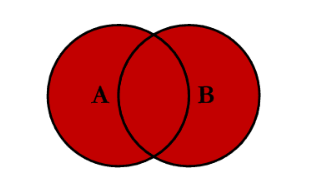
语法:
SELECT
FROM Table_A A
FULL OUTER JOIN Table_B B
ON A.Key = B.Key
但MySQL不支持full outer join,改成 左连接 union 右连接
# select * from book as a FULL OUTER JOIN stu as b on a.stuid = b.stuid;# MySQL不支持full outer joinselect * from book as a left join stu as b on a.stuid = b.stuidunionselect * from book as a right join stu as b on a.stuid = b.stuid;
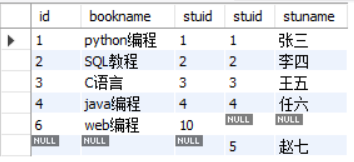
(5)左连接-内连接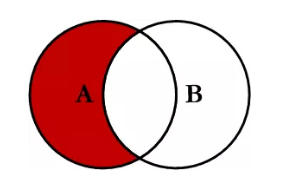
语法:
SELECT
FROM Table_A A
LEFT JOIN Table_B B
ON A.Key = B.Key
WHERE B.Key IS NULL
select * from book as a left join stu as b on a.stuid = b.stuid where b.stuid is null;

(6)右连接-内连接

语法:
SELECT
FROM Table_A A
RIGHT JOIN Table_B B
ON A.Key = B.Key
WHERE A.Key IS NULL
select * from book as a right join stu as b on a.stuid = b.stuid where a.stuid is null;

(7)外连接-内连接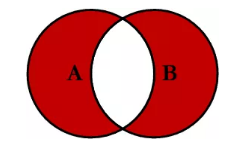
语法:
SELECT
FROM Table_A A
FULL OUTER JOIN Table_B B
ON A.Key = B.Key
WHERE A.Key IS NULL OR B.Key IS NULL
MySQL不支持full outer join,使用union
select * from book as a left join stu as b on a.stuid = b.stuid where b.stuid is nullunionselect * from book as a right join stu as b on a.stuid = b.stuid where a.stuid is null;
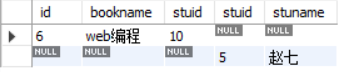
19.使用正则表达式查询
语法:属性名 regexp (regular expression) 匹配模式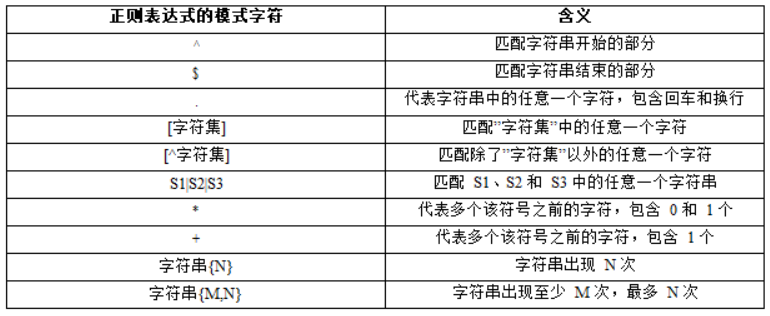
(1)查询以特定字符或字符串开头的记录
select * from book where bookname regexp '^p';
(2)查询以特定字符或字符串结尾的记录
select * from book where bookname regexp '言$';select * from book where bookname regexp '编程$';
(3)以符号”.”来代替字符串中的任意一个字符
select * from book where bookname regexp 'C..';
(4)匹配指定字符串中的任意一个
select * from book where bookname regexp '[p,j,c]';select * from book where stuid regexp '[2-5]';select * from book where bookname regexp '[a-c]';
(5)匹配指定字符以外的字符
select * from book where stuid regexp '[^2-3]';
(6)匹配指定字符串
select * from book where bookname regexp 'ja|we|pt';
(7)使用”*”和”+”来匹配多个字符
select * from book where bookname regexp 'p*n';select * from book where bookname regexp 'p+n';select * from book where bookname regexp 'j*a';select * from book where bookname regexp 'j+a';
(8)使用{N}和{M,N}来指定字符串连续出现的次数
insert book values(7,'aaa',11),(8,'abc',12),(9,'aaabbb',13),(10,'ababa',14),(11,'aaabd',15);select * from book where bookname regexp 'a{3}';select * from book where bookname regexp 'ab{1,3}';



























- 找指定长度的目标子串+哈希")
")





还没有评论,来说两句吧...