使用JAVA进行图像识别——基于Tess4J实现
基于Tess4J实现的图像识别
最近在思考一个问题,如何实现用户注册的拍照验证功能,图像识别与抓取功能,但之前一直在听说使用Python,难道我大Java就没有实现吗?
果然前辈们已经帮我们集成好了Tess4J,在等待我们拿去用,感动ing
Tess4J是对Tesseract OCR API.的Java JNA 封装。使java能够通过调用Tess4J的API来使用Tesseract OCR。支持的格式:TIFF,JPEG,GIF,PNG,BMP,JPEG,and PDF
Tess4J API 提供的功能:
1、直接识别支持的文件
2、识别图片流
3、识别图片的某块区域
4、将识别结果保存为 TEXT/ HOCR/ PDF/ UNLV/ BOX
5、通过设置取词的等级,提取识别出来的文字
6、获得每一个识别区域的具体坐标范围
7、调整倾斜的图片
8、裁剪图片
9、调整图片分辨率
10、从粘贴板获得图像
11、克隆一个图像(目的:创建一份一模一样的图片,与原图在操作修改上,不相 互影响)
12、图片转换为二进制、黑白图像、灰度图像
13、反转图片颜色
首先,下载Tess4J的相关资源(一个压缩包),官网:http://tess4j.sourceforge.net/codesample.html
其中:
lib文件夹下放的是需要用到的Jar包
tessdata下放的是语言库,默认的有英语库,中文库需要另外下载,
新建Java项目,将lib文件夹和tessdata文件夹复制到项目的根目录下,找到dist文件夹下的tess4j.jar(名字可能有版本号),将该文件也复制到项目根目录下的lib文件夹下。
在项目中导入lib文件夹中所有的jar包(Build path —> configure build path),导入后的结果如下:
Tess4J的代码比较简短,如下:
Tess4JTest.java
package ocr;import net.sourceforge.tess4j.ITesseract;import net.sourceforge.tess4j.Tesseract;import net.sourceforge.tess4j.TesseractException;import net.sourceforge.tess4j.util.LoadLibs;import java.io.File;import java.io.IOException;/** * Tess4J测试类 */public class Tess4JTest {public static void main(String[] args){String path = "D://Java//Tess4J"; //我的项目存放路径File file = new File(path + "//photo.jpg");ITesseract instance = new Tesseract();/** * 获取项目根路径,例如: D:\IDEAWorkSpace\tess4J */File directory = new File(path);String courseFile = null;try {courseFile = directory.getCanonicalPath();} catch (IOException e) {e.printStackTrace();}//设置训练库的位置instance.setDatapath(courseFile + "//tessdata");instance.setLanguage("eng");//chi_sim :简体中文, eng 根据需求选择语言库String result = null;try {long startTime = System.currentTimeMillis();result = instance.doOCR(file);long endTime = System.currentTimeMillis();System.out.println("Time is:" + (endTime - startTime) + " 毫秒");} catch (TesseractException e) {e.printStackTrace();}System.out.println("result: ");System.out.println(result);}}
效果如下:
原图:

读取结果:
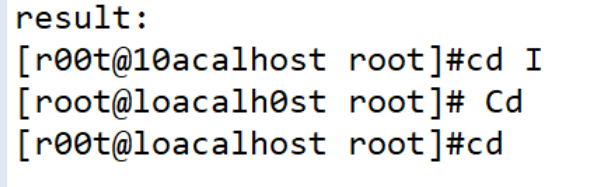
对比而言,0和o的分辨不够准确,需要多多训练字体库。






























")


还没有评论,来说两句吧...