Hadoop安装教程以及注意事项!
首先,为什么要使用hadoop
hadoop是一款可靠的、可伸缩的、分布式计算的开源软件. 是一个框架、允许跨越计算机集群的大数据集处理,使用简单的编程模型(MapReduce)。可从单个服务器扩展到几千台主机,每个节点提供了计算和存储的功能。而不是依赖高可用性的机器依赖于应用层面上的实现;而且处理海量数据的架构首选,非常快得完成大数据计算任务,因此,给大家说下hadoop安装心得;以Cloudera发行版:CDH安装为例。
找到hadoop2.6版本 cdh5.14.2左右的就可以,找一个专门放压缩文件的文件夹开始解压
tar -zxf hadoop-2.6.0-cdh5.14.2.tar.gz
解压完后可以重命名便于记忆,在这里就叫hadoop260
mv hadoop-2.6.0-cdh5.14.2 hadoop260
接下来就是要开始配置环境变量:
hadoop260/etc/hadoop下都是hadoop的配置文件,在hadoop-env.sh找java环境变量,把路径改成你的jdk路径
vi hadoop-env.sh
配置core-site.xml,在里面配置4组
vi core-site.xml
设置副本个数,最少3个,这里因为是举例就设置成1个,也是在里面配置
vi hdfs-site.xml
拷贝一份mapred-site.xml.template配置文件到mapred-site.xml
更改mapred-site.xml中配置文件,同样在里面配置
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
配置resourcemanager站点名称和nodemanager 辅助节点管理
vi yarn-site.xml

配置hadoop的环境变量
vi /etc/profile
export HADOOP_HOME=/opt/hadoop260
export HADOOP_MAPRED_HOME=$ HADOOP_HOME
export HADOOP_COMMON_HOME=$ HADOOP_HOME
export HADOOP_HDFS_HOME=$ HADOOP_HOME
export YARN_HOME=$ HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$ HADOOP_HOME/lib/native
export PATH=$ PATH:$ HADOOP_HOME/sbin:$ HADOOP_HOME/bin
export HADOOP_INSTALL=$ HADOOP_HOME
注意
$前后没有空格,HADOOP_HOME的路径是你的hadoop解压后的路径,配置完后一定要去激活
激活配置文件
source /etc/profile
格式化格式化NameNode
hadoop namenode -format
启动
start-all.sh
这时会提示输入密码的情况,当正确输入密码的时候,可能需要多输入几次,去开启一个个进程
查看配置的文件是否生效,查看进程情况
jps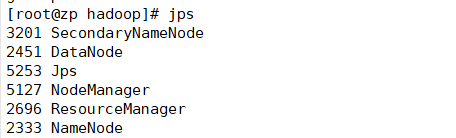
当出现上图的5个进程时,表示启动成功,当然除了jps时,
去网站输入虚拟机的地址,端口号是50070,查看是否能显示网址
http://192.168.xx.xxx:50070
这时,恭喜,启动成功!
当然了,这里只是hadoop最基本的配置,后面的免密登录也会给大家讲解如何操作!




























还没有评论,来说两句吧...