hive常用命令总结(亲测有效)
死,这是第二遍总结了,第一遍刚总结完,就被臭宝给直接退出了,无语,再来一次。
首先简单的说一下hive是个什么东西,能用来在做什么。hive其实就是一个数据库,在大数据时代,常用来构建数据仓库。简称数仓,当然,我以前也做过数据仓库的项目,但是都是用oracle来写的。既然是数据库,那么也离不开sql,hive中的sql又叫hql,所以排除API编写和底层原理的话,学习起来的学习成本不是很高。那么就再总结一次hive常用命令吧,之余hive的性能调优,之前也写了一部分,有兴趣的伙伴可以去瞅瞅哈。
就从最简单的增删改查来写吧。
1 创建数据库有两种创建方法,如果不指定创建路径的话,会默认存放再HDFS上1.1 默认创建数据库create database db_hive;
默认创建hive数据库存放的位置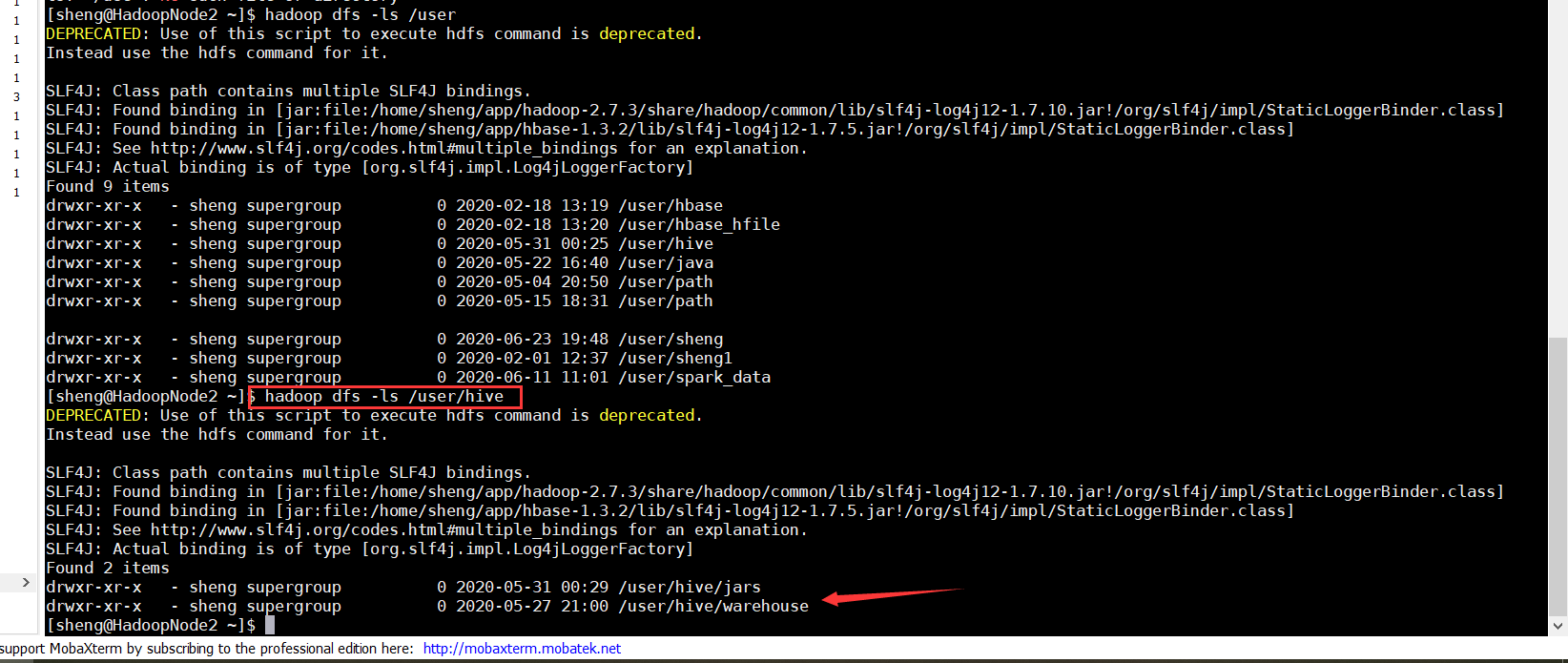
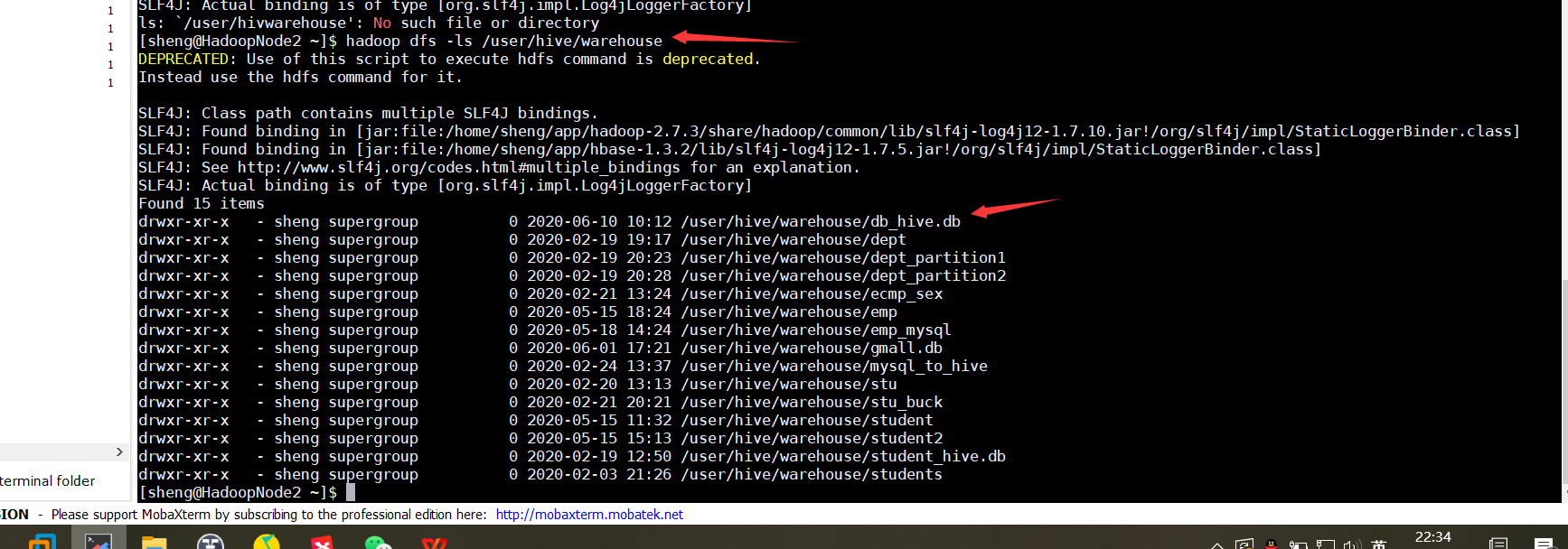
1.2 指定路径创建数据库:create database db_hive2 location '/db_hive2.db';
效果如下: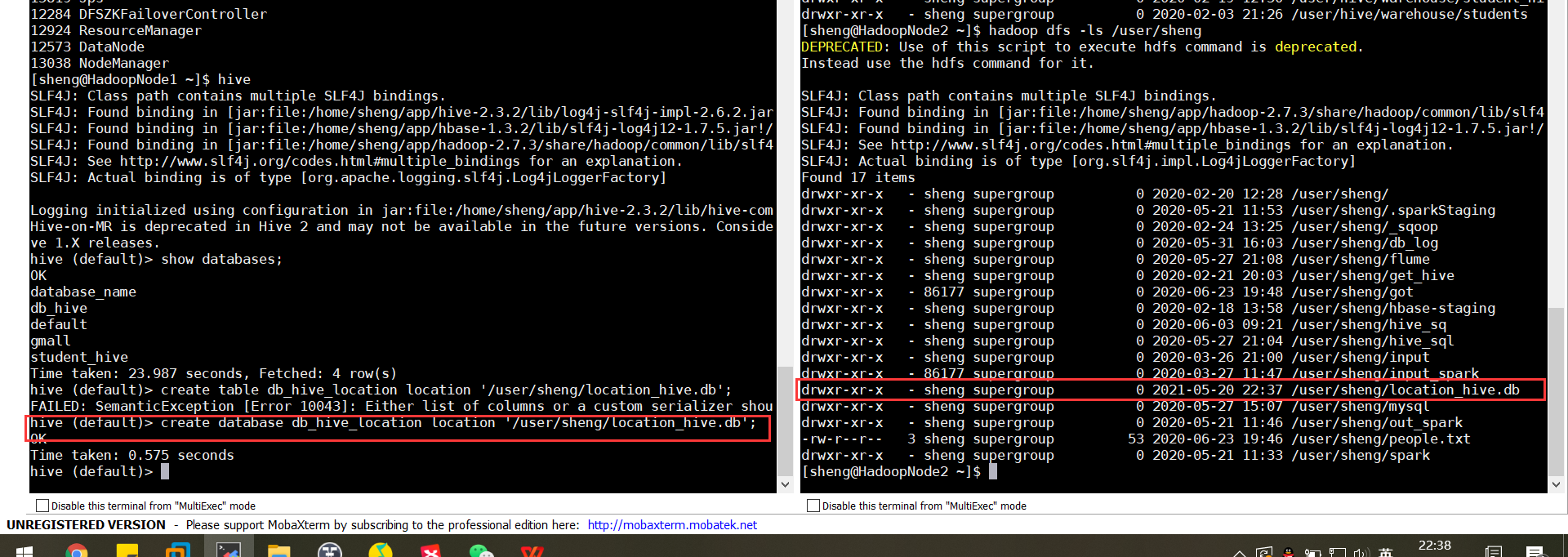
1.3 查看创建数据库的信息,包括存储位置等;show create database db_hive;

1.4 修改数据库信息(暂不支持修改数据库名称):用户可以使用ALTER DATABASE命令为某个数据库的DBPROPERTIES设置键-值对属性值,来描述这个数据库的属性信息。数据库的其他元数据信息都是不可更改的,包括数据库名和数据库所在的目录位置。修改键值对信息hive (default)> alter database db_hive set dbproperties('createtime'='20170830');查看键值对信息describe database extended db_hive;

1.5 查看已创建的数据库显示数据库show databases;过滤显示数据库show databases like 'db_*';
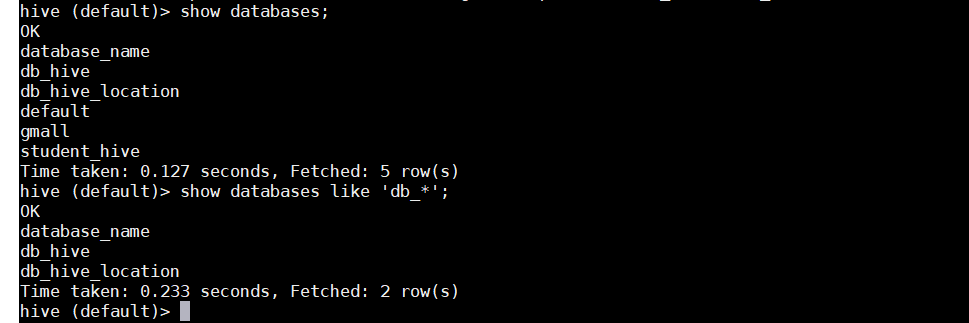
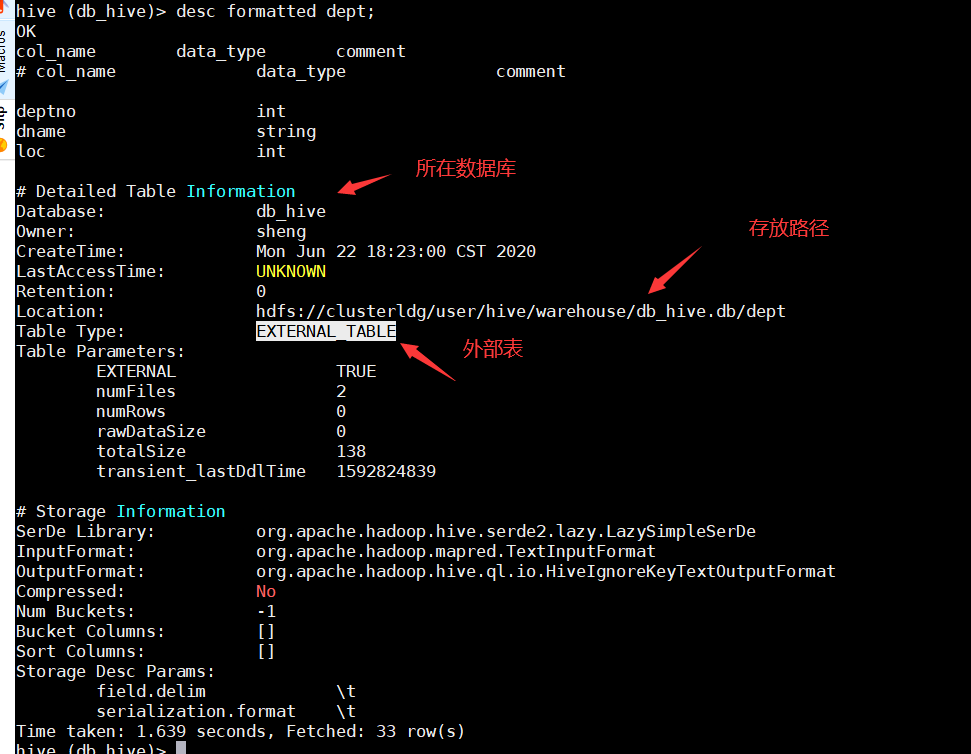
1.6 使用切换某个数据库use db_hive;1.7 删除数据库drop databases db_hive;如果数据库不为空,可以进行强制删除,命令如下drop databases db_hive cascade;2 数据表的操作2.1 创建表:CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name[(col_name data_type [COMMENT col_comment], ...)][COMMENT table_comment][PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)][CLUSTERED BY (col_name, col_name, ...)[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS][ROW FORMAT row_format][STORED AS file_format][LOCATION hdfs_path]字段解释说明(1)CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项来忽略这个异常。(2)EXTERNAL关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION),Hive创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。(3)COMMENT:为表和列添加注释。(4)PARTITIONED BY创建分区表(5)CLUSTERED BY创建分桶表(6)SORTED BY不常用(7)ROW FORMATDELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char][MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]用户在建表的时候可以自定义SerDe或者使用自带的SerDe。如果没有指定ROW FORMAT 或者ROW FORMAT DELIMITED,将会使用自带的SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的SerDe,Hive通过SerDe确定表的具体的列的数据。(8)STORED AS 指定存储文件类型常用的存储文件类型:SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列式存储格式文件)如果文件数据是纯文本,可以使用STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE。(9)LOCATION :指定表在HDFS上的存储位置。(10)LIKE允许用户复制现有的表结构,但是不复制数据。2.2 创建表的时候也有两种表模式,一种是管理表(内部表),还有一种是外部表简单的说下这两种表的区别吧默认创建的表都是所谓的管理表,有时也被称为内部表。因为这种表,Hive会(或多或少地)控制着数据的生命周期。Hive默认情况下会将这些表的数据存储在由配置项hive.metastore.warehouse.dir(例如,/user/hive/warehouse)所定义的目录的子目录下。 当我们删除一个管理表时,Hive也会删除这个表中数据。管理表不适合和其他工具共享数据。如果是本地做测试的话,那么可以选择这样的方式来创建。简单的说,一旦删除内部表的话,连带表的内容也会被删除。反之,外部表会指定存放路径,即使被删除了,也只是删除了这个表的元数据信息,而表的内容不会被删除。查询表的详细信息:568desc formatted db_hive;

























盒子模型,边框,内外边距,盒子模型布局,ps基本操作,列表样式,圆角边框,盒子阴影")








还没有评论,来说两句吧...