redis知识点
Redis
什么是redis
- redis是开源的nosql数据库,c语言编写,可基于内存也可持久化的key-value数据库。
特点:
- 性能高,读速度是11w次/秒,写的速度是8w次/秒
- 丰富的数据类型,String list set zset hash
- 原子,redis是单线程的
- 丰富的特性
发布订阅模式,key过期,通知等 - 支持持久化
Redis为什么这么快
- 基于内存
- 单线程
- 使用多路I/O复用模型,非阻塞IO:多个网络连接复用同一个线程,在空闲的时候会把当前线程阻塞,当有一个或多个IO事件时,就从阻塞中唤醒
redis五种数据结构
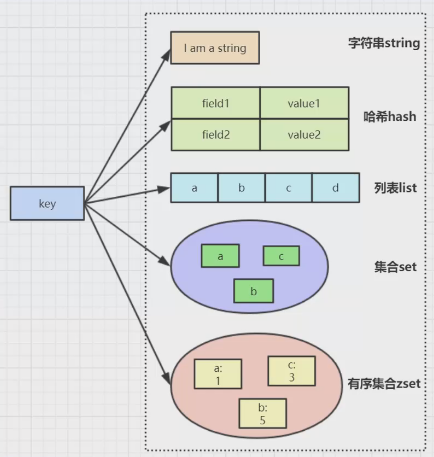
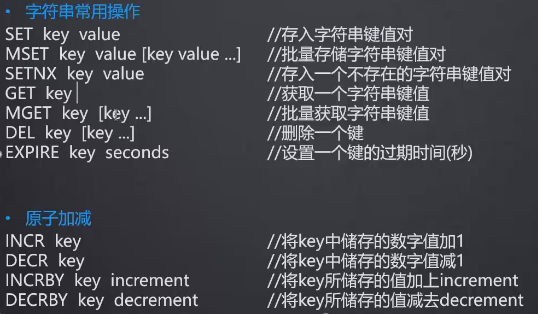
String常用操作及应用场景
应用场景

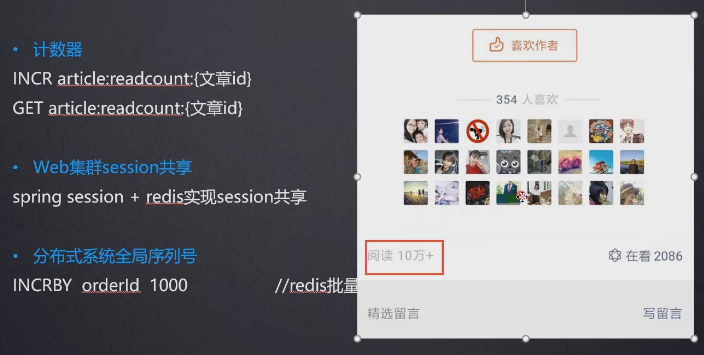
- redis批量生成全局唯一的序列号,可用于分布式下的自增id的创建
- redis单台机器的并发是几万
Hash常用操作及应用场景
常用操作
应用场景:
- 把所有的用户信息都放在user里
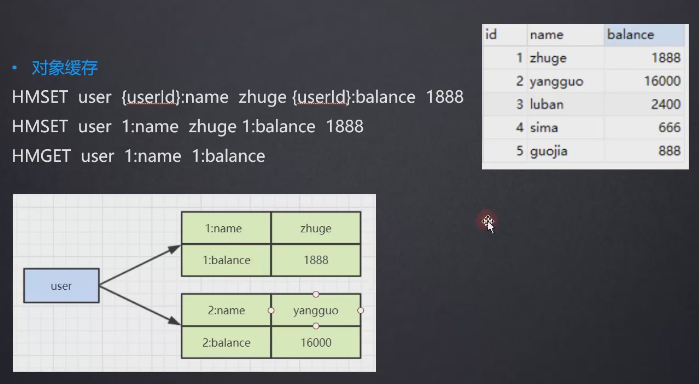
- 实现购物车功能(不用考虑并发和性能)
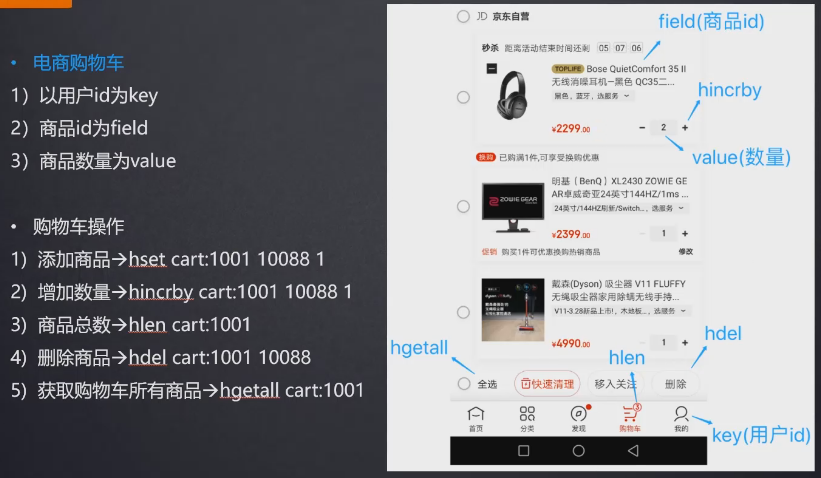
hash优缺点:
优点:
- 同类数据归类整合存储,方便数据管理
- 相比string消耗内存与cpu更小,比string存储更节省空间
缺点:
- 过期功能不能使用在field上,只能用在key上
- redis集群架构下不适合大规模使用,比如所有的用户都存在user这个key下,如果有三百万用户,就会导致user很大,而redis存储会先通过key计算hash然后除以16384,看结果落在哪一个节点就在那一个节点存储,一个key下有很多field和value就会导致一个redis集群存储的过多,而其他集群较少的情况(导致数据过于集中)。

List常用操作及应用场景
常用操作:
应用场景:
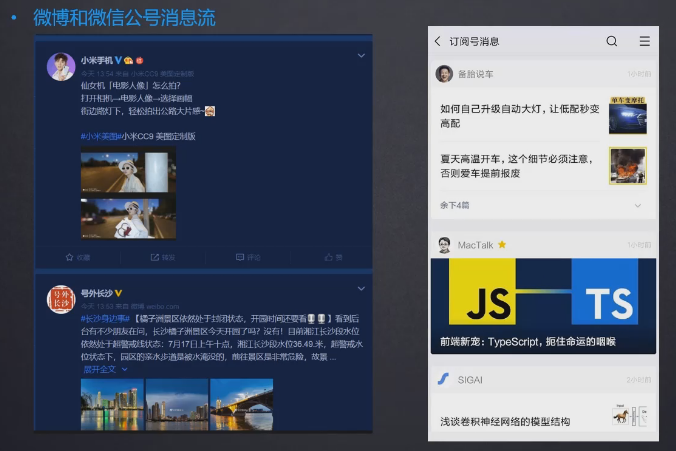
微博关注的人发的消息按时间倒序排列,就可以使用list类型
- 一个用户关注了a,b
- a发微博,消息id为1001,lpush msg;{用户id} 1001
- b又发了微博,消息id为1002, lpush msg:{用户id} 1002
- 用户查看最新六条微博消息:lrange msg:{用户id} 0 5

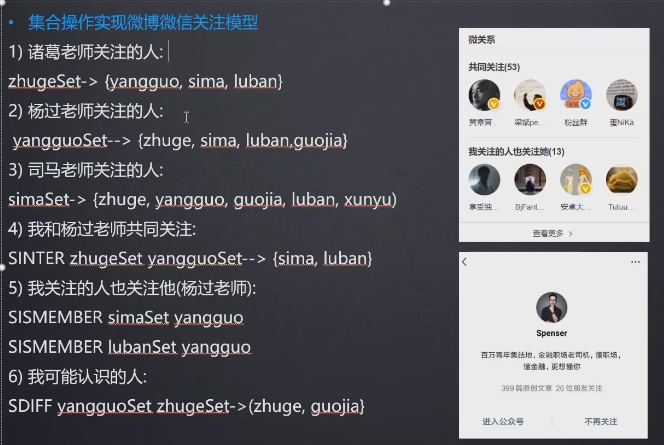
Set常用操作及应用场景
常用操作:
应用场景:
微信抽奖:

- sadd act:[抽奖活动id] 用户id sadd act:1001 1 sadd act:1001 2 sadd act:1001 3
- smembers act:1001
- 抽一次:srandmember act:1001 2 抽两个用户
- 抽多次:spop act:1001 5 第一次抽5个人,抽完之后要把这五个人排除掉,然后抽第二次
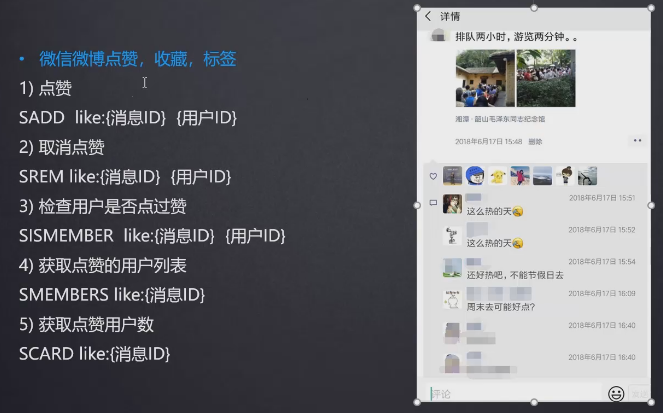
微信、微博点赞,收藏
集合操作:
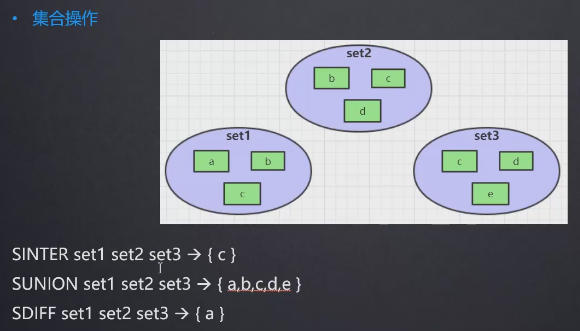
-
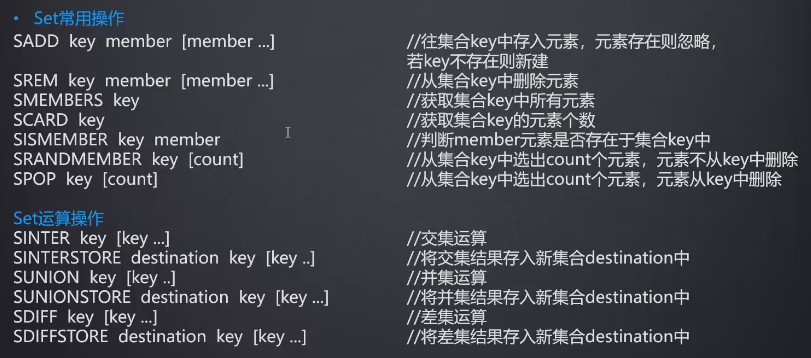
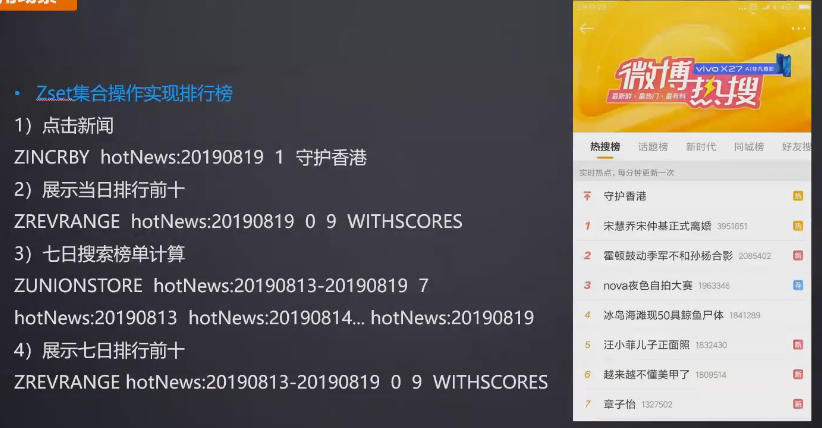
zset常用操作及应用场景
- 也是set,只是带了分值,支持用于排序
常用操作:
应用场景:

redis使用场景
- String:保存单个字符串或json字符串数据;图片文件;计数器如粉丝数
- Hash:存储一个对象
- list:消息队列,保证先后顺序;对数据量大的集合进行删减操作
- set:对两个集合进行交集并集差集,共同好友;利用唯一性做唯一操作,如统计网站的所有独立ip
- zset:排行榜
redis集群方案比较
- 单机模式
- 主备模式
- 哨兵模式
- 集群模式
单机模式
- 强依赖于redis的,redis一挂,服务就不能用了,如单点登录把session放在redis中。
主备模式
- 一台主节点,一台从节点,数据的读写都是主节点(master)做,slave节点只同步主节点的数据,当主节点挂了,需要手动把访问redis的服务ip改成从节点。
- 缺点:还需要人为干预,如果半夜3点master服务器挂了。。
哨兵模式
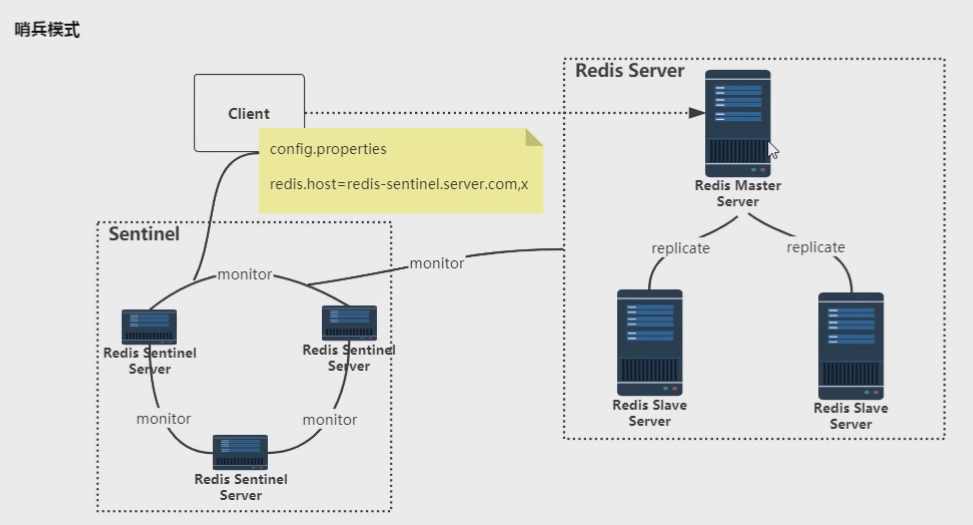
- 只有一个集群。使用sentinel对redis集群里面每一台都做监控,负责节点的加入和退出。当主节点挂掉时,sentinel会进行选举选出新的主节点。读写数据时,客户端连接sentinel,sentinel告诉客户端哪台机器是主节点,然后客户端拿到主节点ip后对数据进行操作。
- 优点:自动化运维
- 缺点:总是只有一个master,也就是一个redis服务,接收所有的请求,存储所有的数据。不支持大数据量的存储,不支持大并发,当主节点挂掉到从节点作为新的主节点的转换的过程中,服务不可用
集群模式
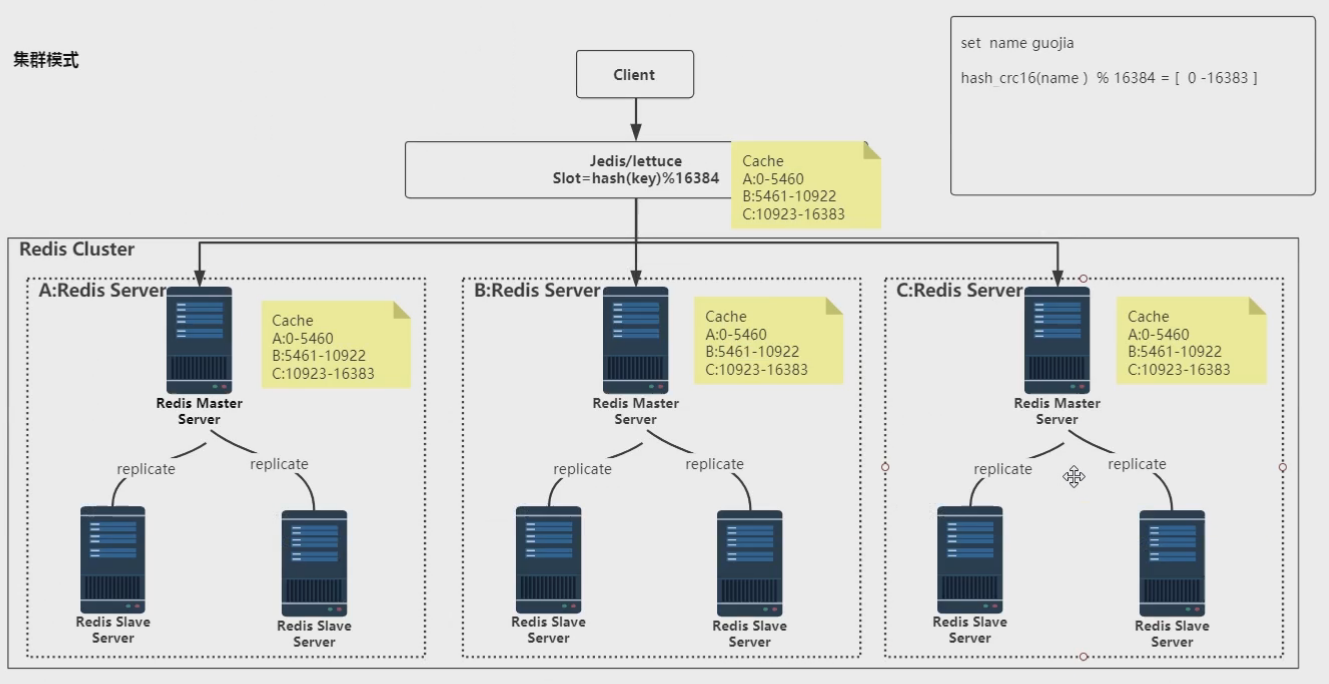
- 由很多个小的集群模式组成,每个集群只有master节点对外提供服务。整个集群有16384个槽点(slot),每个集群会平均分到不同的槽,访问数据时就可以实现负载均衡。集群在构建时就会把虚拟槽分配好,并且每一个主节点都有分配的虚拟槽的缓存表,当客户端连接集群时,先去任意机器拿到缓存表,在客户端本地存一份,当设置值时,客户端先对key进行hash操作得到hash值,然后用hash值对16384取模得到一个0-16383的值,根据这个值可以知道把数据放在哪个集群,实现数据分片和负载均衡。
- 当一个集群中的master挂掉了,还需要人工把从节点设置为主节点。
- 当设置值时,如果在第一台设置,但是通过hash%16383得到的结果在第三台机器,就会重定向到第三台机器去设置值(这个过程是自动的,不管是redis命令还是java操作redis都不要人来跳转干预)
jedis客户端如何实现分片(源码分析)
真的是hash%16384吗?
- 不是,是hash&(16384-1),2^14=16384
搭建redis高可用集群
-
什么是redis缓存穿透?如何解决?
- 缓存穿透:查询一个一定不存在的数据,由于缓存不命中时需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,造成缓存穿透。
- 解决:持久层查询不到就缓存空结果,查询时先判断缓存中是否exists(key) ,如果有直接返回空,没有则查询后返回
什么是雪崩?如何解决?
- 雪崩:缓存大量失效的时候,引发大量查询数据库
- 解决:用锁/分布式锁或者队列串行访问; 缓存失效时间均匀分布
Redis
- remote dictoinary service 远程字典服务。
关系型数据库的特点:
- 以表格形式,基于行存储,二维
- 存储的是结构化的数据
- 表与表之间存在关联
- 大部分关系型数据库都支持sql(结构化查询语言)操作
- 通过支持事务(ACID酸)来提供数据一致性
非关系型数据库的特点:
- 存储非结构化的数据,如文本,图片,音频
- 表与表之间没有关联,扩展性强
- 通过base(碱)保证数据一致性
- 支持海量数据的存储和高并发的高效读写
- 支持分布式,扩缩容简单
非关系型数据库的种类
- kv存储,用key value的形式来存储数据,如redis和memcacheDB
- 文档存储,MongoDB
- 列存储,HBase
- 图存储
- 对象存储
- xml存储
redis有几种数据类型
- string:二进制安全的string,存储字符串,整数,浮点数
- hash
- set
- zset
- list
- hyperloglog
- streams
String类型为什么是二进制安全的?在redis底层它是怎么存储的?
redis存储原理(数据模型)
- 由于是kv类型的数据库,是通过hashtable实现的(外层哈希),每个键值对都会有一个dictEntry,里面包含了key,value和next,next指向下一个dictEntry。
- typedef struct dictEntry {
void key; / key 关键字定义 */
union {
} v;void *val; uint64_t u64; /* value 定义 */int64_t s64; double d;
struct dictEntry next; / 指向下一个键值对节点 */
} dictEntry; - 当set hello world时,key是String类型,String类型在redis中是通过sds存储的。value也是字符串,value先使用redisObject来存储的再由redisObject指向具体的数据结构,比如world也是字符串就指向一个sds。五大类型的值都是放在redisObject中存储的。
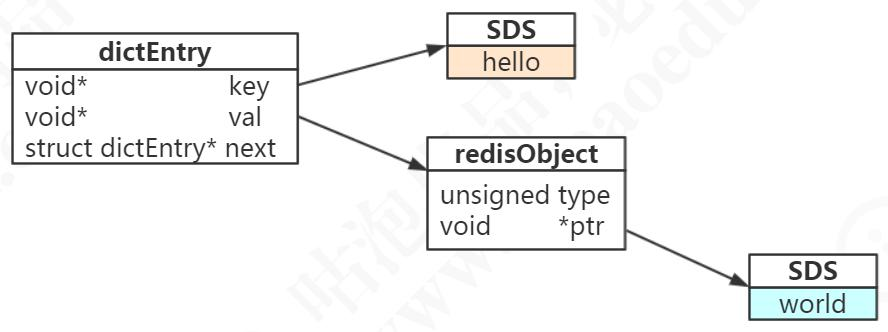
redisObject
- typedef struct redisObject {
unsigned type:4; / 对象的类型,包括:OBJ_STRING、OBJ_LIST、OBJ_HASH、OBJ_SET、OBJ_ZSET /
unsigned encoding:4; / 具体的数据结构,实际使用的编码 /
unsigned lru:LRU_BITS; / 24 位,对象最后一次被命令程序访问的时间,与内存回收有关 /
int refcount; / 引用计数。当 refcount 为 0 的时候,表示该对象已经不被任何对象引用,则可以进行垃圾回收了 /
void ptr; / 指向对象实际的数据结构,比如如果是sds就会指向sds的数据结构 */
} robj; 在redis中字符串有三种编码
- int,存储8个字节的长整型(long, 2^63-1)
- embstr,存储小于44个字节的字符串
- raw,存储大于44个字节的字符串
查看某个key是什么编码类型
- object encoding key
什么是SDS
- sds有多种结构:sdshdr5,sdshdr8,sdshdr16.。。用于存储不同长度的字符串,分别代表2的多少次方。25=32byte,28=256byte。。。
- / sds.h /
struct attribute ((packed)) sdshdr8 {
uint8_t len; / 当前字符数组的长度 /
uint8_t alloc; /当前字符数组总共分配的内存大小 /
unsigned char flags; / 当前字符数组的属性、用来标识到底是 sdshdr8 还是 sdshdr16 等 /
char buf[]; / 字符串真正的值,真正存储字符串的地方 /
};
redis为什么要用自定义字符串的实现(SDS)?
- c语言本身没有字符串,只能用字符数组char[]实现。
使用字符数组实现字符串带来的问题:
- 使用前必须先分配足够的空间,否则可能溢出
- 如果要获取长度,需要遍历数组,时间复杂度是O(n)
- 字符数组长度变化时会重做内存分配
- 结尾是以’\0’结束的,在保存图片,音频等二进制文件时,如果文件带有’\0’符号就不安全
- 为了解决上述问题,redis引入了SDS。
SDS特点:
- 不用担心内存溢出问题,需要时会对sds扩容
- sds中定义了len变量,获取字符串长度时间复杂度为O(1)
- 通过空间预分配和惰性空间释放,防止多次重分配内存
- 通过len属性判断是否结束
embstr和raw的区别?为什么针对字符类型的存储又要弄两种编码?
- embstr中RedisObject和SDS是连续的,只分配一次内存空间,查找也更加方便。而raw的RedisObject和SDS不是连续的,需要分配两次内存空间
- embstr是只读的,因为当字符串长度增加需要重新分配内存时,RedisObject和SDS都需要重新分配空间,此时embstr会变成raw
int和embstr什么时候转化为raw
- int数据不再是整数,或大小超过了long的范围(2^63-1)时,自动转化为raw
- 由于embstr是只读的,当堆embstr类型的字符串就行修改,它就会先转化成raw后再进行修改,无论是否达到44个字节
当长度小于阈值时,编码会还原吗?
- 不会,转换不可逆,只能从小内存编码向大内存编码转换
为什么要用不同的编码实现同一种数据类型呢?(为什么要对底层的数据结构进行一层封装?)
- 根据对象的类型动态的选择存储结构,实现节省空间和优化查询速度
String的应用场景
- 缓存:如热点数据缓存,对象缓存,提升热点数据访问速度
- 分布式数据共享:分布式session,引入spring-session-data-redis的依赖
- 分布式锁:setnx
- 全局ID:int类型,incrby,利用原子性
- 计数器:int类型,incr方法,如文章阅读量,点赞数
- 限流:int类型,incr方法,如以访问者的i等信息作为key,访问一次增加一次,超过次数返回false,不再让其访问
- 位统计:字符是以8位二进制存储的,如a转为二进制是01100001,可以修改指定位上的值(位操作),把一个数变成另一个数。位存储非常节省空间,可以用来做大数据量的统计,如在线用户统计、留存用户统计
hash
- 外层是用哈希表实现的,filed和value又是一个哈希表
hash相比于String的优点
- 把所有相关的值聚集到一个key中,节省空间,减少key冲突
- 需要取值时,可以使用命令获取所有的field和value,不用一个一个取了
hash相比于string的缺点
- field不能单独设置过期时间
- 没有bit操作
- 需要考虑数据量分布的问题,如field value很多或value很大时,无法分布到多个节点




























还没有评论,来说两句吧...