Python爬取新闻网站保存标题、内容、日期、图片等数据
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
python免费学习资料以及群交流解答点击即可加入
基本开发环境
- Python 3.6
Pycharm
import requests
import parsel
import pdfkit
import csv
import threading
相关模块pip安装即可
确定目标网页

获取数据
- 标题
- 内容 保存成PDF
- 日期
- 图片 保存本地
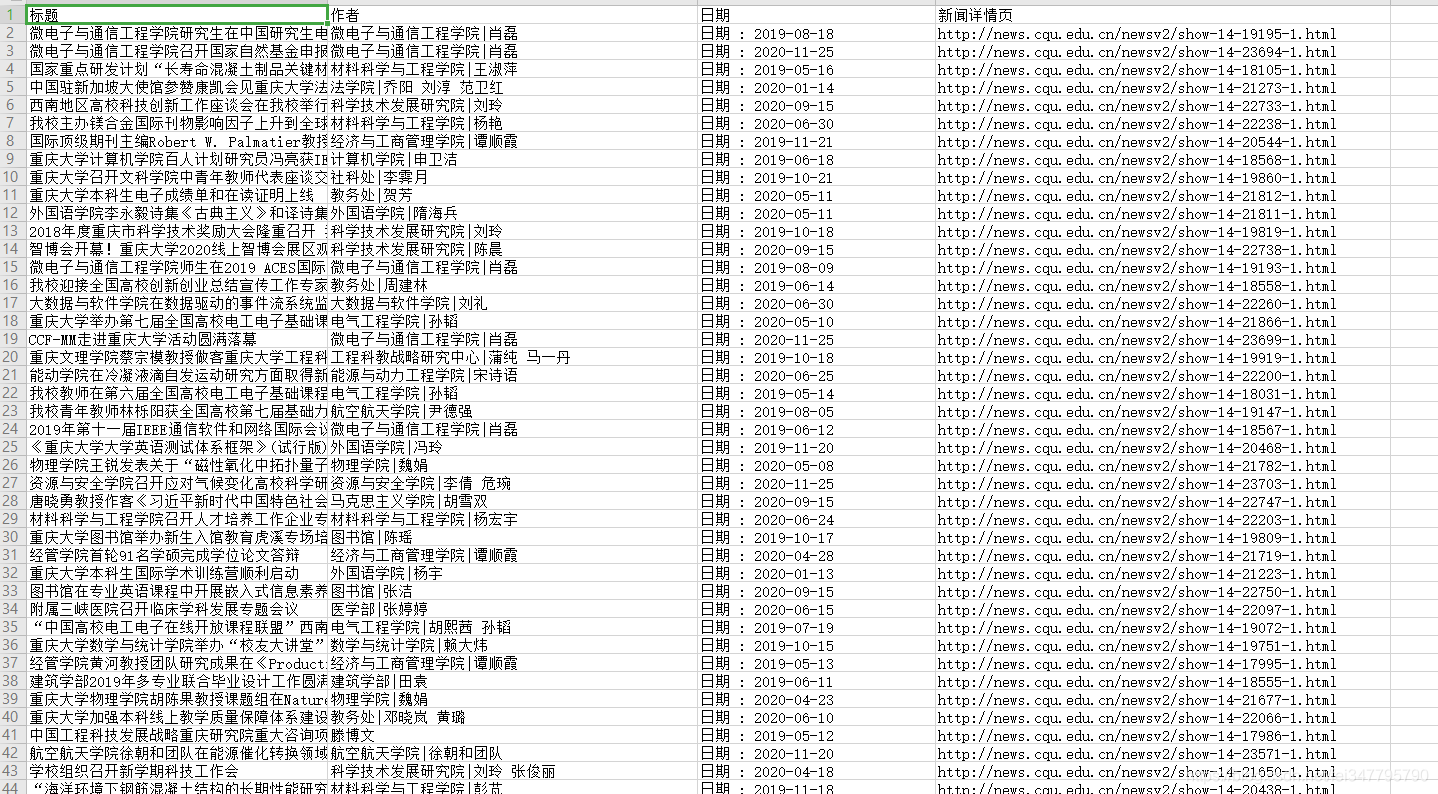
- 详情页url、日期、图片地址等等 保存csv
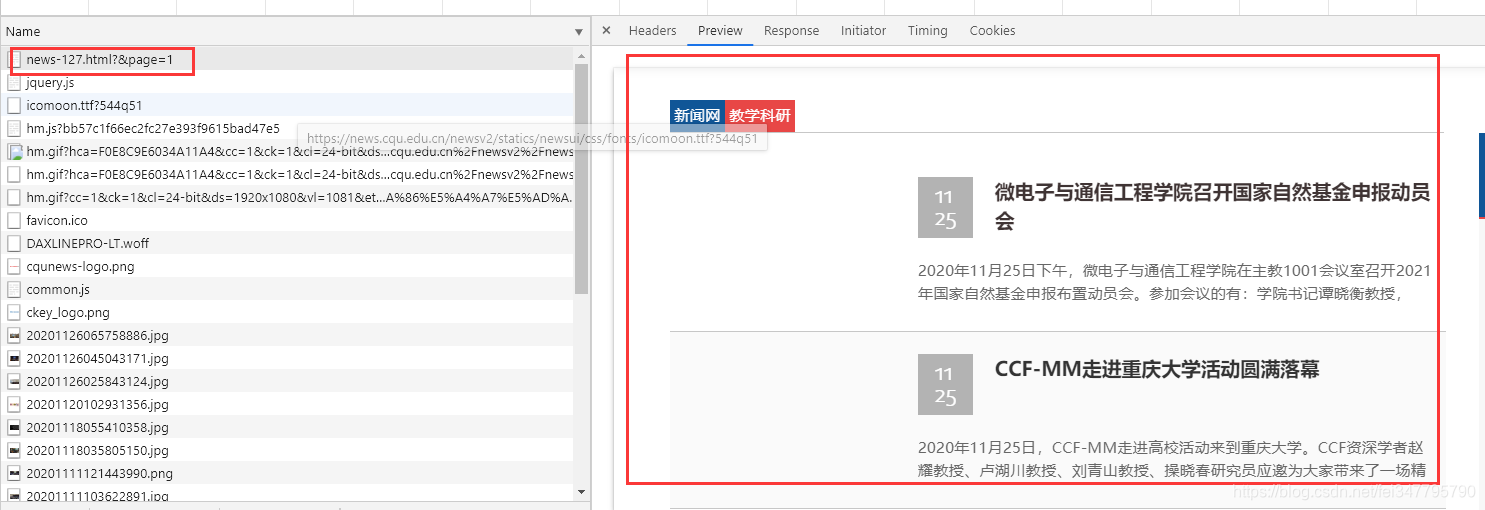
网站是静态网页,没有什么难度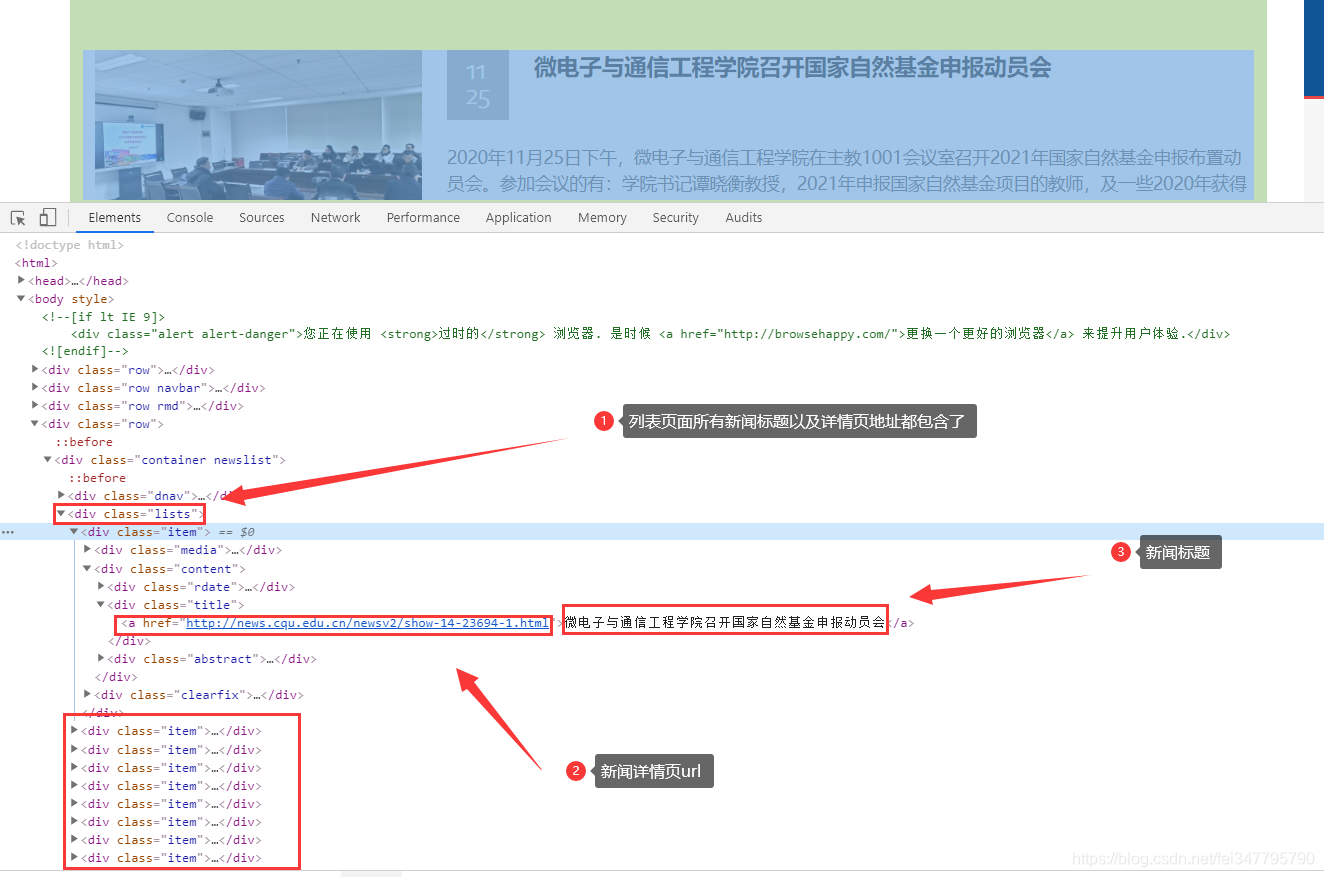
详情页
同样是静态页面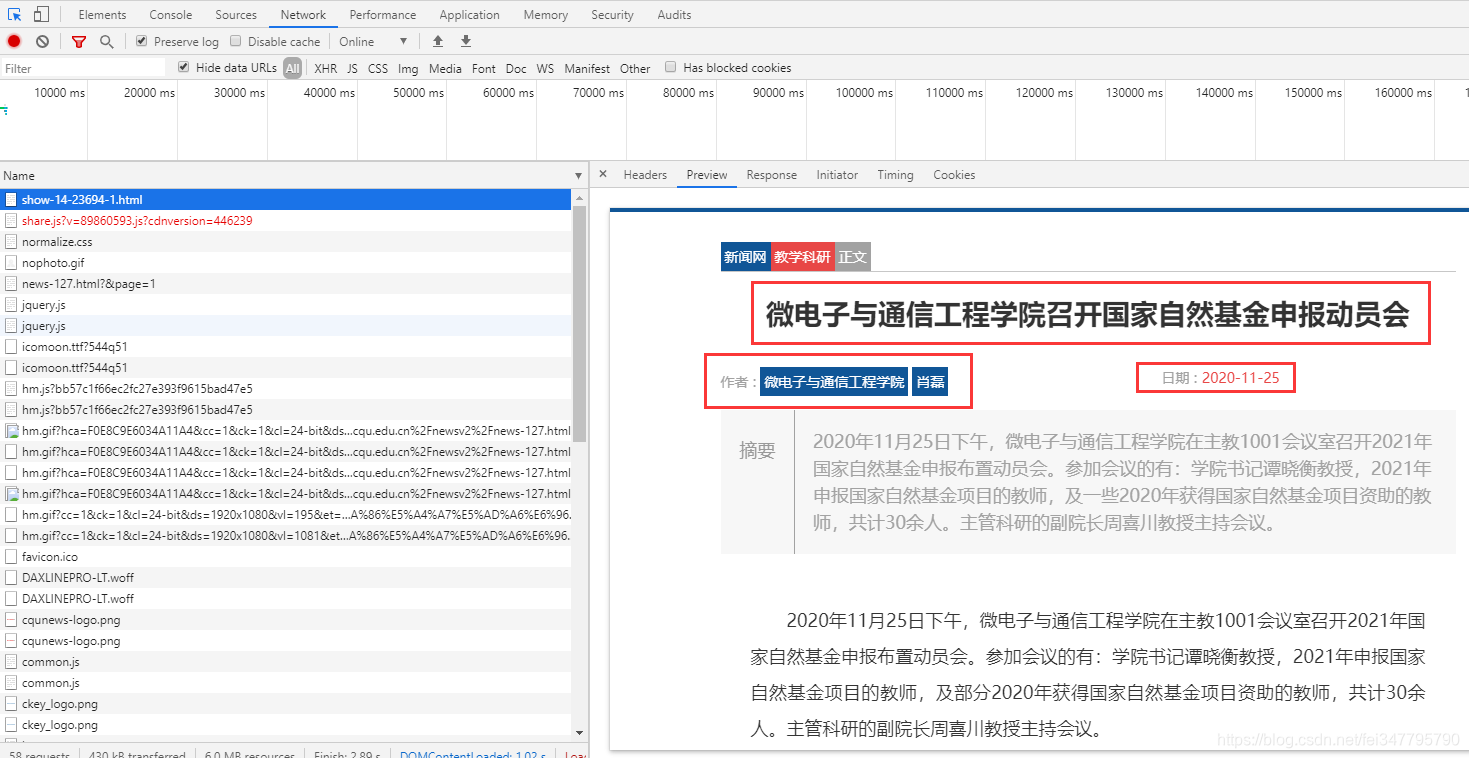
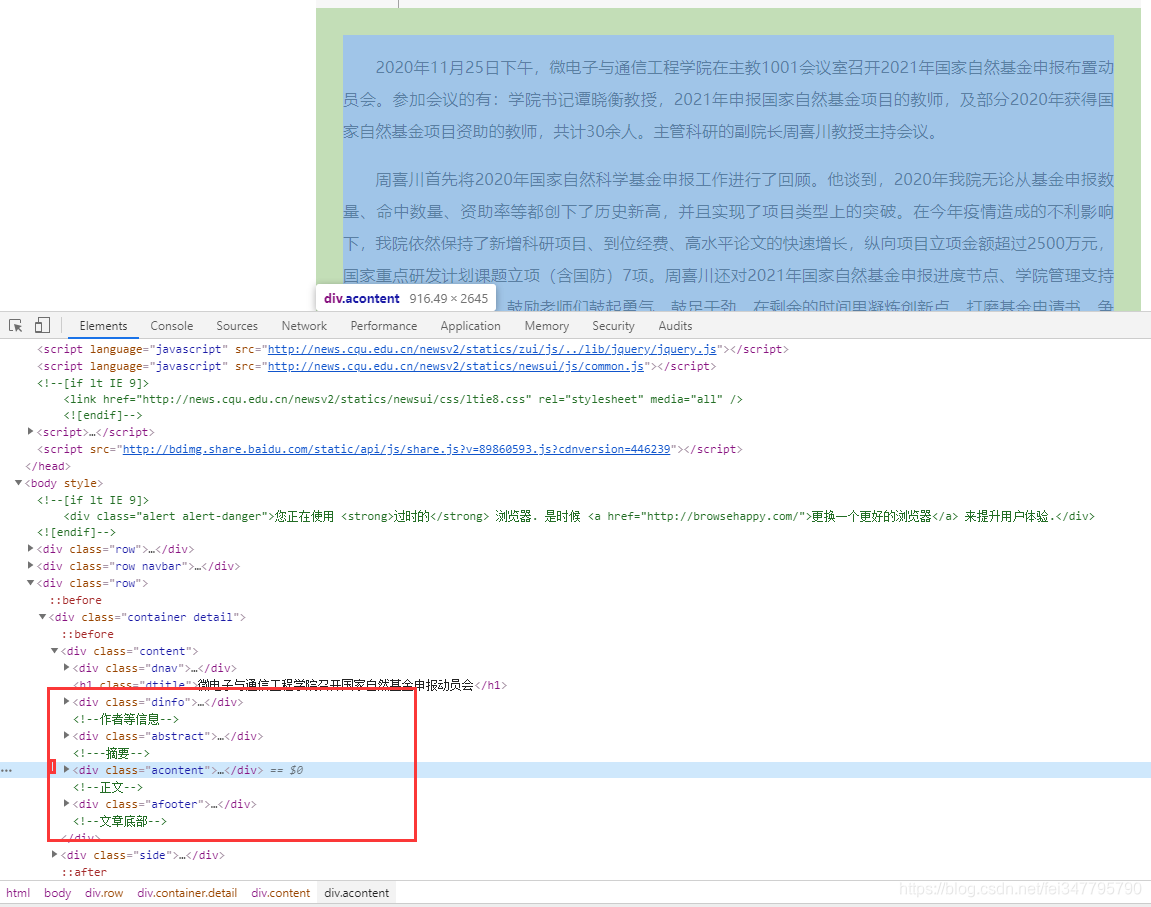
网页源代码已经说明数据在什么地方了,利用相关的解析工具,对网页数据进行解析即可。
代码实现
请求网页以及解析
def get_html(html_url):
response = requests.get(url=html_url, headers=headers)return response
def get_pars(html_data):selector = parsel.Selector(html_data)return selector
保存内容 PDF格式
html_str = “”” <!doctype html>
Document {article} “””
def save_article(article, title):html_path = '重庆新闻\\' + title + '.html'pdf_path = '重庆新闻pdf\\' + title + '.pdf'html = html_str.format(article=article)with open(html_path, mode='w', encoding='utf-8') as f:f.write(html)print('{}已下载完成'.format(title))# exe 文件存放的路径config = pdfkit.configuration(wkhtmltopdf='C:\\Program Files\\wkhtmltopdf\\bin\\wkhtmltopdf.exe')# 把 html 通过 pdfkit 变成 pdf 文件pdfkit.from_file(html_path, pdf_path, configuration=config)
保存csv文件
f = open(‘新闻.csv’, mode=’a’, encoding=’utf-8-sig’, newline=’’)
csv_writer = csv.DictWriter(f, fieldnames=[‘标题’, ‘作者’, ‘日期’, ‘新闻详情页’])
csv_writer.writeheader()保存图片
def save_img(img_urls):
for i in img_urls:img_url = 'http://news.cqu.edu.cn' + iimg_content = get_html(img_url).contentimg_name = img_url.split('/')[-1]with open('新闻图片\\' + img_name, mode='wb') as f:f.write(img_content)
主函数
def main(url):
html_data = get_html(url).textselector = get_pars(html_data)lis = selector.css('body > div:nth-child(4) > div > div.lists .title a::attr(href)').getall()for li in lis:content_data = get_html(li).textli_selector = get_pars(content_data)title = li_selector.css('.dtitle::text').get() # 新闻标题article = li_selector.css('.acontent').get() # 新闻内容name_list = li_selector.css('.dinfoa a::text').getall() # 作者name = '|'.join(name_list)date_list = li_selector.css('.ibox span::text').getall()date_str = ''.join(date_list) # 新闻日期img_urls = li_selector.css('.acontent p img::attr(src)').getall() # 获取新闻内图片dit = {'标题': title,'作者': name,'日期': date_str,'新闻详情页': li,}csv_writer.writerow(dit)save_article(article, title)save_img(img_urls)
if __name__ == '__main__':for page in range(1, 11):url = 'https://news.cqu.edu.cn/newsv2/news-127.html?&page={}'.format(page)main_thread = threading.Thread(target=main, args=(url,))main_thread.start()
- 文件PDF
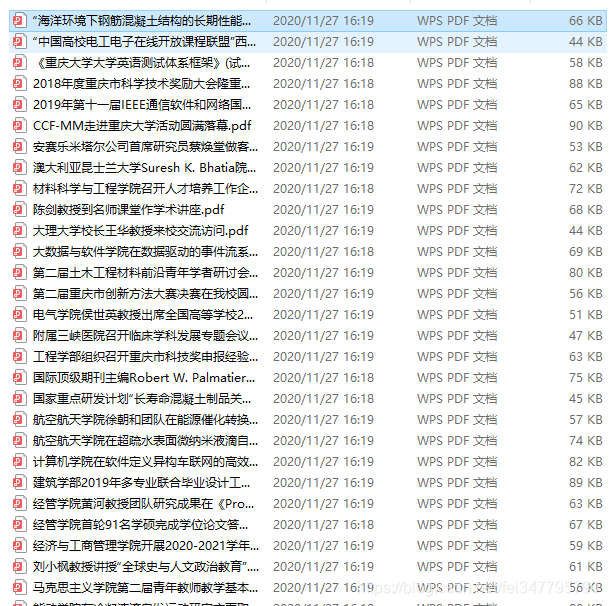

- 详情页url
- 相关图片
图片可以按照标题后缀数字123命名,这个地方可以优化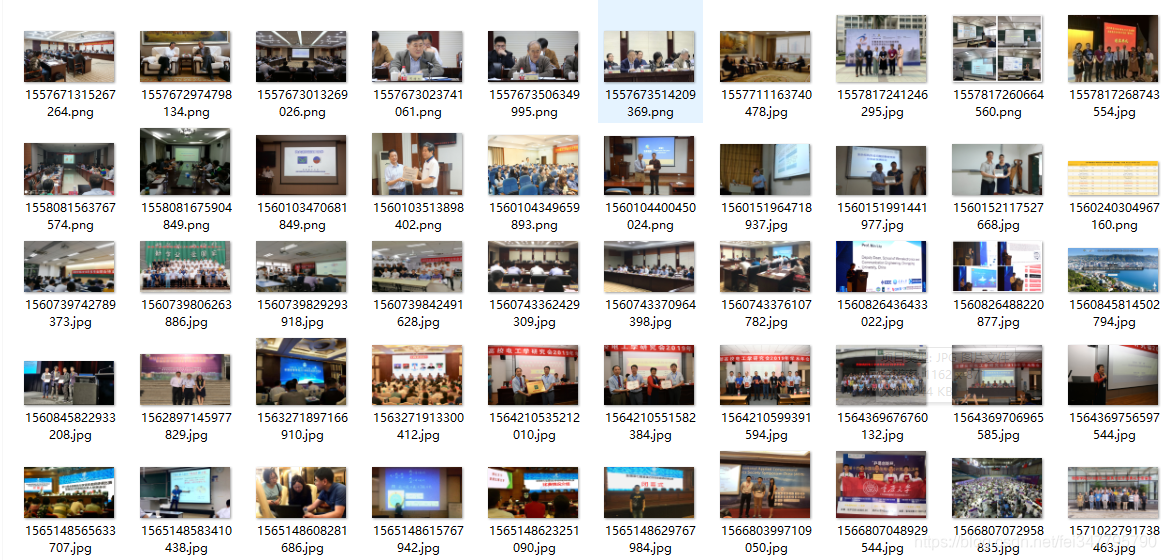
- csv文件数据
完整代码
import requestsimport parselimport pdfkitimport csvimport threadingf = open('新闻.csv', mode='a', encoding='utf-8-sig', newline='')csv_writer = csv.DictWriter(f, fieldnames=['标题', '作者', '日期', '新闻详情页'])csv_writer.writeheader()headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'}html_str = """ <!doctype html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Document</title> </head> <body> {article} </body> </html> """def get_html(html_url):response = requests.get(url=html_url, headers=headers)return responsedef get_pars(html_data):selector = parsel.Selector(html_data)return selectordef save_article(article, title):html_path = '重庆新闻\\' + title + '.html'pdf_path = '重庆新闻pdf\\' + title + '.pdf'html = html_str.format(article=article)with open(html_path, mode='w', encoding='utf-8') as f:f.write(html)print('{}已下载完成'.format(title))# exe 文件存放的路径config = pdfkit.configuration(wkhtmltopdf='C:\\Program Files\\wkhtmltopdf\\bin\\wkhtmltopdf.exe')# 把 html 通过 pdfkit 变成 pdf 文件pdfkit.from_file(html_path, pdf_path, configuration=config)def save_img(img_urls):for i in img_urls:img_url = 'http://news.cqu.edu.cn' + iimg_content = get_html(img_url).contentimg_name = img_url.split('/')[-1]with open('新闻图片\\' + img_name, mode='wb') as f:f.write(img_content)def main(url):html_data = get_html(url).textselector = get_pars(html_data)lis = selector.css('body > div:nth-child(4) > div > div.lists .title a::attr(href)').getall()for li in lis:content_data = get_html(li).textli_selector = get_pars(content_data)title = li_selector.css('.dtitle::text').get() # 新闻标题article = li_selector.css('.acontent').get() # 新闻内容name_list = li_selector.css('.dinfoa a::text').getall() # 作者name = '|'.join(name_list)date_list = li_selector.css('.ibox span::text').getall()date_str = ''.join(date_list) # 新闻日期img_urls = li_selector.css('.acontent p img::attr(src)').getall() # 获取新闻内图片dit = {'标题': title,'作者': name,'日期': date_str,'新闻详情页': li,}csv_writer.writerow(dit)save_article(article, title)save_img(img_urls)if __name__ == '__main__':for page in range(1, 11):url = 'https://news.cqu.edu.cn/newsv2/news-127.html?&page={}'.format(page)main_thread = threading.Thread(target=main, args=(url,))main_thread.start()



























")


")



还没有评论,来说两句吧...