SpringCloud 之 Ribbon/Feign/Hystrix 的超时、重试问题总结
Hi,我是空夜,又是一周不见!
今天来讲讲 ribbon 和 feign 中超时时间应该如何配置。
Spring Cloud 中,一般会用 feign 或者 ribbon 来进行服务调用,ribbon 还自带了负载均衡、重试机制。而feign 是基于 ribbon 的。
通常,为了保证服务的高可用,防止雪崩等问题的出现,还会引入 hystrix。hystrix 的熔断也跟超时时间有关系。
如何统筹考虑 ribbon、feign、hystrix 三者之间的关系,添加合适的配置,使得各个组件各司其职、协调合作, 是一个麻烦的问题。
想想就令人头秃。

今天我就来理清一下 ribbon、feign、hystrix 之间的超时关系。
首先有一个推论:
feign 集成了 ribbon 和 hystrix,feign 本身不带超时限制,其超时是由 ribbon 和 hystrix 控制的。
因此,我们仅需要理清 ribbon 和 hystrix 之间的超时关系即可。

下面以 ribbon 为例,分别测试在默认情况下、与 hystrix 整合使用情况下的超时情况。
1. ribbon 的默认配置
ribbon 的默认配置在 DefaultClientConfigImpl 这个类中。
public static final int DEFAULT_READ_TIMEOUT = 5000;public static final int DEFAULT_CONNECTION_MANAGER_TIMEOUT = 2000;public static final int DEFAULT_CONNECT_TIMEOUT = 2000;
注意,这里出现了第一个天坑:虽然 DefaultClientConfigImpl 这个类里指定了 DEFAULT_READ_TIMEOUT 为 5000 ms,但是,debug 发现,这个默认值在构建 ribbon 的 clientConfig 时,被替换掉了。
具体如下:
在使用 ribbon 请求接口时,第一次会构建一个 IClienConfig 对象,这个方法在 RibbonClientConfiguration 类中,此时,重新设置了 ConnectTimeout、ReadTimeout、GZipPayload
public class RibbonClientConfiguration {/** * Ribbon client default connect timeout. */public static final int DEFAULT_CONNECT_TIMEOUT = 1000;/** * Ribbon client default read timeout. */public static final int DEFAULT_READ_TIMEOUT = 1000;/** * Ribbon client default Gzip Payload flag. */public static final boolean DEFAULT_GZIP_PAYLOAD = true;@RibbonClientNameprivate String name = "client";@Autowiredprivate PropertiesFactory propertiesFactory;@Bean@ConditionalOnMissingBeanpublic IClientConfig ribbonClientConfig() {DefaultClientConfigImpl config = new DefaultClientConfigImpl();config.loadProperties(this.name);config.set(CommonClientConfigKey.ConnectTimeout, DEFAULT_CONNECT_TIMEOUT);config.set(CommonClientConfigKey.ReadTimeout, DEFAULT_READ_TIMEOUT);config.set(CommonClientConfigKey.GZipPayload, DEFAULT_GZIP_PAYLOAD);return config;}//...}
综上,ribbon 的默认 ConnectTimeout 和 ReadTimeout 都是 1000 ms

下面我们看看自定义配置。
2. 自定义 ribbon 的配置
咱们通过 ribbon.xxx 来自定义配置,看看能不能生效:
ribbon:OkToRetryOnAllOperations: true #对所有操作请求都进行重试,默认falseReadTimeout: 1000 #负载均衡超时时间,默认值5000ConnectTimeout: 3000 #请求连接的超时时间,默认值2000MaxAutoRetries: 1 #对当前实例的重试次数,默认0MaxAutoRetriesNextServer: 0 #重试切换实例的次数,默认1
测试发现不起作用。怎么肥事?网上有些码友的文章里就是这样写的啊。

原因很简单:必须要添加 ribbon.http.client.enabled = true 的配置,自定义 ribbon 的超时配置才能生效。
ribbon:http:client:enabled: true
下面咱们来测试一下超时和重试机制:
(贴心的我已经给了测试截图了,希望你们爱我,害!)
我这里启用了一个 producer 服务来提供接口,该接口大概是这样的:
@GetMapping(value = "hello/{name}")public String hello(@PathVariable("name") String name, Integer mills) {logger.info("开始执行请求,name: " + name + "要求暂停:" + mills + "毫秒");if (mills != null && mills > 0) {try {Thread.sleep(mills);} catch (InterruptedException e) {e.printStackTrace();}}return "hello, [" + name + "], this is service producer by nacos.....";}
注意有一个 mills 参数用于指定 producer 接口的等待时间,这样可以测试出 consumer 服务(也就是利用 ribbon 来调用 producer 接口的服务)的超时、重试机制。
consumer 大概是这样的:
@GetMapping(value = "test")//@HystrixCommand(fallbackMethod = "testHystrix")public String test(String name, Integer mills) {logger.info("开始请求 producer,其暂停时间为:" + mills);String producerRes = restTemplate.getForObject("http://" + service_producer_name + "/producer/hello/" + name + "?mills=" + mills, String.class);logger.info("请求获取成功,开始打印请求结果:");String res = "测试consumer/test接口,基于ribbon调取服务server-producer的hello接口,返回:" + producerRes;System.out.println(res);return res;}
测试代码准备好了,咱们开始测试:

首先,当前实例重试一次:
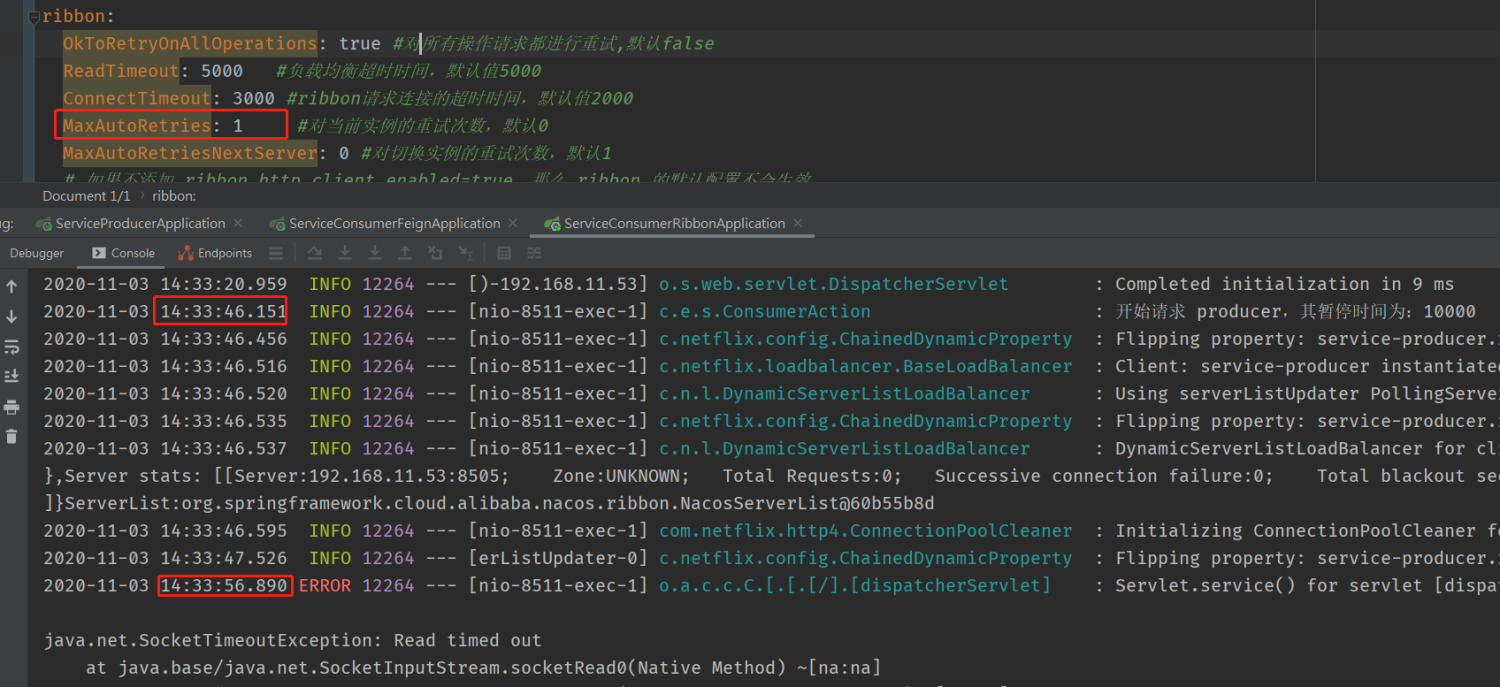
请求的 ReadTimeOut 设置为 5s,1 + MaxAutoRetries = 2,两次,刚好 10s
我们看下 producer 端:
下面将 MaxAutoRetries 和 MaxAutoRetriesNextServer 都设为 1: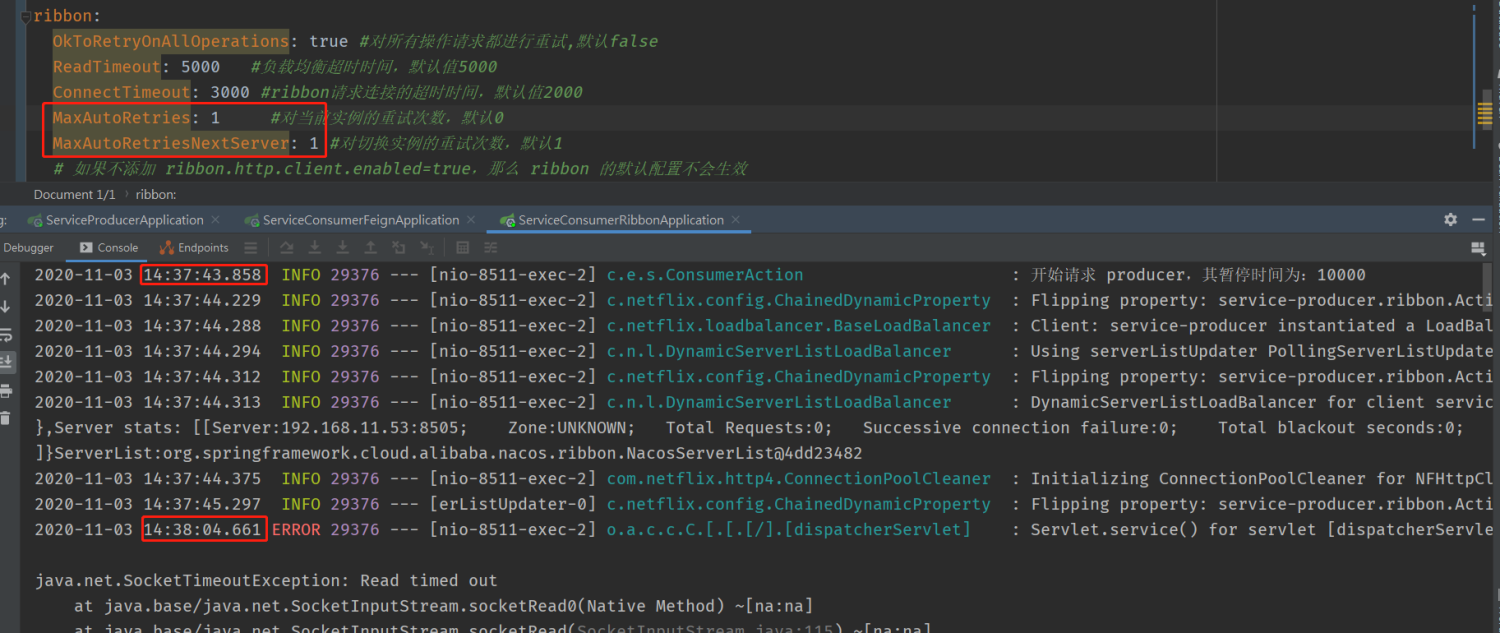
看下 producer 端,每个 5s 接收到一个请求,共 4个:

为什么会请求四次呢?
为什么将 MaxAutoRetriesNextServer 设为 1,会使得请求增加了 2 次重试呢?
MaxAutoRetriesNextServer 直接翻译过来是:下一个服务的最大重试次数。
这个土味翻译听起来就像是对下一个服务重试的次数。那应该是1吗?这里的下一个服务又指的是什么呢?

不要慌,小场面。咱们改一下配置,MaxAutoRetries 设置为 2,MaxAutoRetriesNextServer 设为 3;
这里我们启动两个同名的 producer,那么这个服务就有两个实例了;
测试一下: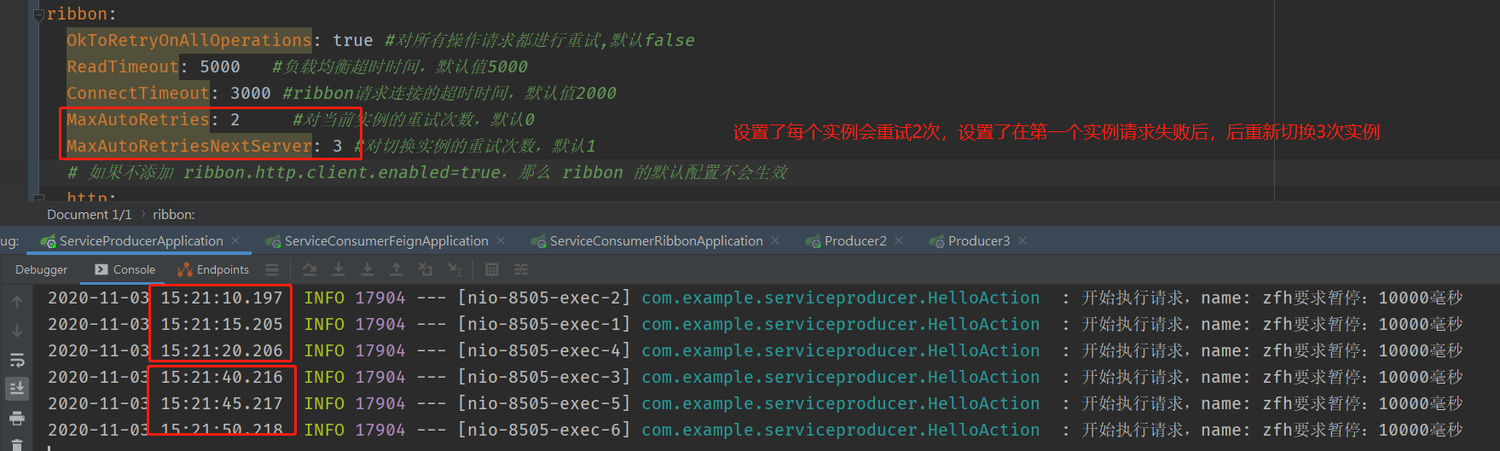
(贴心的我已经给在图里给你们标出来分析的结果了,是不是很暖男?)
另一个 producer:

根据日志里的时间推算,MaxAutoRetriesNextServer 真正的意思应该是:如果请求失败,最大要切换多少次服务实例(不管具体有多少个实例,即使一个实例,也会切换回这个实例本身 MaxAutoRetriesNextServer 次 )
下面我们得出结论:ribbon 中,请求最多会被执行—— 1 + maxAutoRetries + (maxAutoRetries + 1) * MaxAutoRetriesNextServer
也就是 (1 + maxAutoRetries ) * (1 + MaxAutoRetriesNextServer) 次

ribbon 这个渣男的套路已经被我们解析透彻了。下面我们将面对 ribbon + hystrix 的渣男+暖男组合。
3. ribbon 集成 hystrix 后的超时、重试配置
为什么要叫 hystrix 暖男呢?当然是有原因的。
hystrix 是一个服务降级、限流、熔断组件。可以有效保证微服务平台的稳定性,避免雪崩等现象的发生。所以说,hystrix 还是很暖的。

ribbon 集成 hystrix 很简单:
启动类添加 @EnableHystrix 注解。
接口上添加 @HystrixCommand ,配置 fallback 方法:
@GetMapping(value = "test")@HystrixCommand(fallbackMethod = "testHystrix")public String test(String name, Integer mills) {logger.info("开始请求 producer,其暂停时间为:" + mills);String producerRes = restTemplate.getForObject("http://" + service_producer_name + "/producer/hello/" + name + "?mills=" + mills, String.class);logger.info("请求获取成功,开始打印请求结果:");String res = "测试consumer/test接口,基于ribbon调取服务server-producer的hello接口,返回:" + producerRes;System.out.println(res);return res;}/** * test接口的断路器 * @param name * @return */private String testHystrix(String name, Integer mills) {return "sorry, " + name + ", this service is unavailable temporarily. We are returning the defaultValue by hystrix.";}
测试看看:
producer 暂停 500ms, 正常
producer 暂停 1000ms,请求被 @HystrixCommand 指定的 fallback 方法处理:
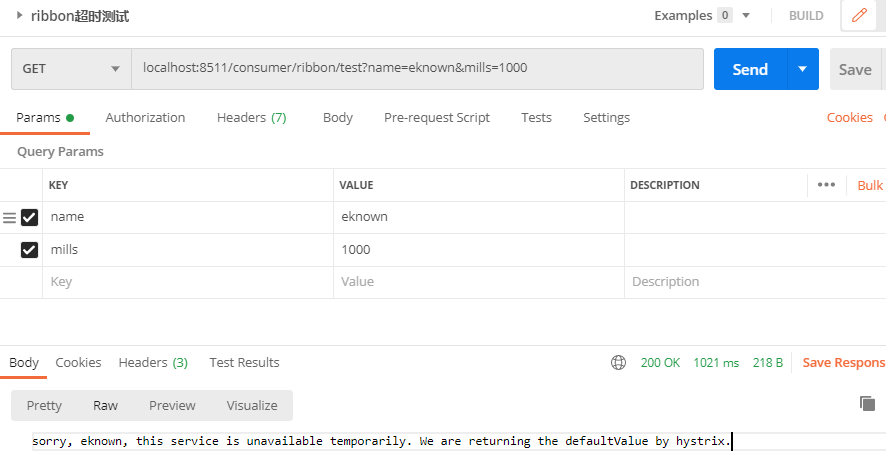
注意:如果没有配置 fallback,那么 hystrix 的超时就不会生效,而是由 ribbon 来控制。
hystrix 的默认超时时间是 1s,这个配置在 HystrixCommandProperties 类中:
private static final Integer default_executionTimeoutInMilliseconds = 1000; // default => executionTimeoutInMilliseconds: 1000 = 1 secondprotected HystrixCommandProperties(HystrixCommandKey key, HystrixCommandProperties.Setter builder, String propertyPrefix) {// ...this.executionTimeoutEnabled = getProperty(propertyPrefix, key, "execution.timeout.enabled", builder.getExecutionTimeoutEnabled(), default_executionTimeoutEnabled);// ...}
继续测试 ribbon 和 hystrix 超时时间的关系。
配置好 hystrix 的 fallback 后,修改配置文件,设置 hystrix 的超时时间,使其大于 ribbon 的超时时间:
ribbon:OkToRetryOnAllOperations: true #对所有操作请求都进行重试,默认falseReadTimeout: 2000 #负载均衡超时时间,默认值5000ConnectTimeout: 3000 #ribbon请求连接的超时时间,默认值2000MaxAutoRetries: 0 #对当前实例的重试次数,默认0MaxAutoRetriesNextServer: 0 #对切换实例的重试次数,默认1# 如果不添加 ribbon.http.client.enabled=true,那么 ribbon 的默认配置不会生效http:client:enabled: truehystrix:command:default: #default全局有效,service id指定应用有效execution:timeout:#如果enabled设置为false,则请求超时交给ribbon控制,为true,则超时作为熔断根据enabled: trueisolation:thread:timeoutInMilliseconds: 10000 #断路器超时时间,默认1000ms
此时,用 postman 发送消息:
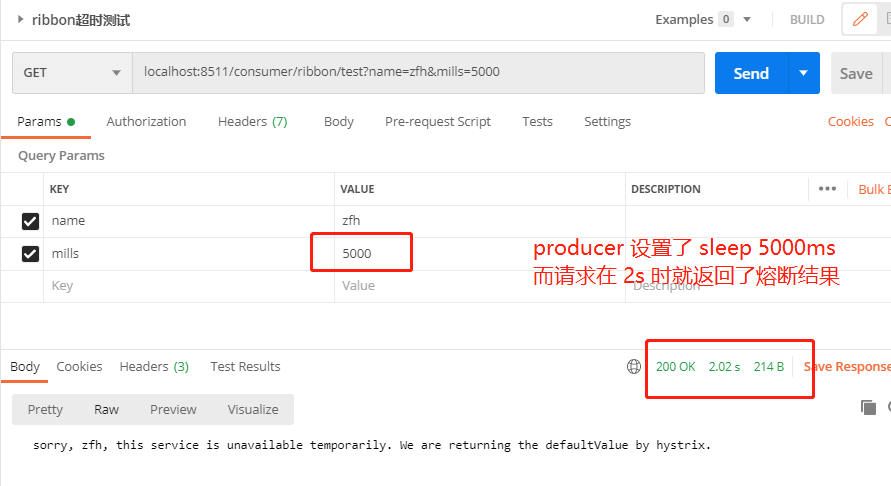
我们可以看到,请求 2s 左右就返回了,这个值刚好是 ribbon.ReadTimeout 的时间。表示此时 ribbon 超时触发了。然后进入了 hystrix 的熔断过程。
4. 结论
总结一下:
- 如果请求时间超过 ribbon 的超时配置,会触发重试;
- 在配置 fallback 的情况下,如果请求的时间(包括 ribbon 的重试时间),超出了 ribbon 的超时限制,或者 hystrix 的超时限制,那么就会熔断;
一般来说,会设置 ribbon 的超时时间 < hystrix, 这是因为 ribbon 有重试机制。(这里说的 ribbon 超时时间是包括重试在内的,即,最好要让 ribbon 的重试全部执行,直到 ribbon 超时被触发)。
由于 connectionTime 一般比较短,可以忽略。那么,设置的超时时间应该满足:
(1 + MaxAutoRetries) \ (1 + MaxAutoRetriesNextServer) ReadTimeOut < hystrix 的 timeoutInMilliseconds\
今日的分享到此结束,记得点个关注点个赞!我的公众号是:猿生物语(ID:JavaApes)


























——Zabbix监控httpd服务和nginx服务")



")




还没有评论,来说两句吧...