Kafka 心跳机制 重复消费
kafka 心跳机制
Kafka是通过心跳机制来控制消费超时,心跳机制对于消费者客户端来说是无感的,它是一个异步线程,当我们启动一个消费者实例时,心跳线程就开始工作了。心跳超时会导致消息重复消费。
在org.apache.kafka.clients.consumer.internals.AbstractCoordinator中会启动一个HeartbeatThread线程来定时发送心跳和检测消费者的状态。每个消费者都有个org.apache.kafka.clients.consumer.internals.ConsumerCoordinator,而每个ConsumerCoordinator都会启动一个HeartbeatThread线程来维护心跳,心跳信息存放在org.apache.kafka.clients.consumer.internals.Heartbeat中,声明的Schema如下所示:
private final int sessionTimeoutMs;private final int heartbeatIntervalMs;private final int maxPollIntervalMs;private final long retryBackoffMs;private volatile long lastHeartbeatSend;private long lastHeartbeatReceive;private long lastSessionReset;private long lastPoll;private boolean heartbeatFailed;
心跳线程实现方法
public void run() {try {log.debug("Heartbeat thread started");while (true) {synchronized (AbstractCoordinator.this) {if (closed)return;if (!enabled) {AbstractCoordinator.this.wait();continue;}if (state != MemberState.STABLE) {// the group is not stable (perhaps because we left the group or because the coordinator// kicked us out), so disable heartbeats and wait for the main thread to rejoin.disable();continue;}client.pollNoWakeup();long now = time.milliseconds();if (coordinatorUnknown()) {if (findCoordinatorFuture != null || lookupCoordinator().failed())// the immediate future check ensures that we backoff properly in the case that no// brokers are available to connect to.AbstractCoordinator.this.wait(retryBackoffMs);} else if (heartbeat.sessionTimeoutExpired(now)) {// the session timeout has expired without seeing a successful heartbeat, so we should// probably make sure the coordinator is still healthy.markCoordinatorUnknown();} else if (heartbeat.pollTimeoutExpired(now)) {// the poll timeout has expired, which means that the foreground thread has stalled// in between calls to poll(), so we explicitly leave the group.maybeLeaveGroup();} else if (!heartbeat.shouldHeartbeat(now)) {// poll again after waiting for the retry backoff in case the heartbeat failed or the// coordinator disconnectedAbstractCoordinator.this.wait(retryBackoffMs);} else {heartbeat.sentHeartbeat(now);sendHeartbeatRequest().addListener(new RequestFutureListener<Void>() {@Overridepublic void onSuccess(Void value) {synchronized (AbstractCoordinator.this) {heartbeat.receiveHeartbeat(time.milliseconds());}}@Overridepublic void onFailure(RuntimeException e) {synchronized (AbstractCoordinator.this) {if (e instanceof RebalanceInProgressException) {// it is valid to continue heartbeating while the group is rebalancing. This// ensures that the coordinator keeps the member in the group for as long// as the duration of the rebalance timeout. If we stop sending heartbeats,// however, then the session timeout may expire before we can rejoin.heartbeat.receiveHeartbeat(time.milliseconds());} else {heartbeat.failHeartbeat();// wake up the thread if it's sleeping to reschedule the heartbeatAbstractCoordinator.this.notify();}}}});}}}} catch (AuthenticationException e) {log.error("An authentication error occurred in the heartbeat thread", e);this.failed.set(e);} catch (GroupAuthorizationException e) {log.error("A group authorization error occurred in the heartbeat thread", e);this.failed.set(e);} catch (InterruptedException | InterruptException e) {Thread.interrupted();log.error("Unexpected interrupt received in heartbeat thread", e);this.failed.set(new RuntimeException(e));} catch (Throwable e) {log.error("Heartbeat thread failed due to unexpected error", e);if (e instanceof RuntimeException)this.failed.set((RuntimeException) e);elsethis.failed.set(new RuntimeException(e));} finally {log.debug("Heartbeat thread has closed");}}
在心跳线程中这里面包含两个最重要的超时函数,分别是sessionTimeoutExpired() 和 pollTimeoutExpired()。
public boolean sessionTimeoutExpired(long now) {return now - Math.max(lastSessionReset, lastHeartbeatReceive) > sessionTimeoutMs;}public boolean pollTimeoutExpired(long now) {return now - lastPoll > maxPollIntervalMs;}
如果sessionTimeout超时,则会被标记为当前协调器处理断开, 即将将消费者移除,重新分配分区和消费者的对应关系。在Kafka Broker Server中,Consumer Group定义了5中(如果算上Unknown,应该是6种状态)状态,org.apache.kafka.common.ConsumerGroupState,如下图所示:
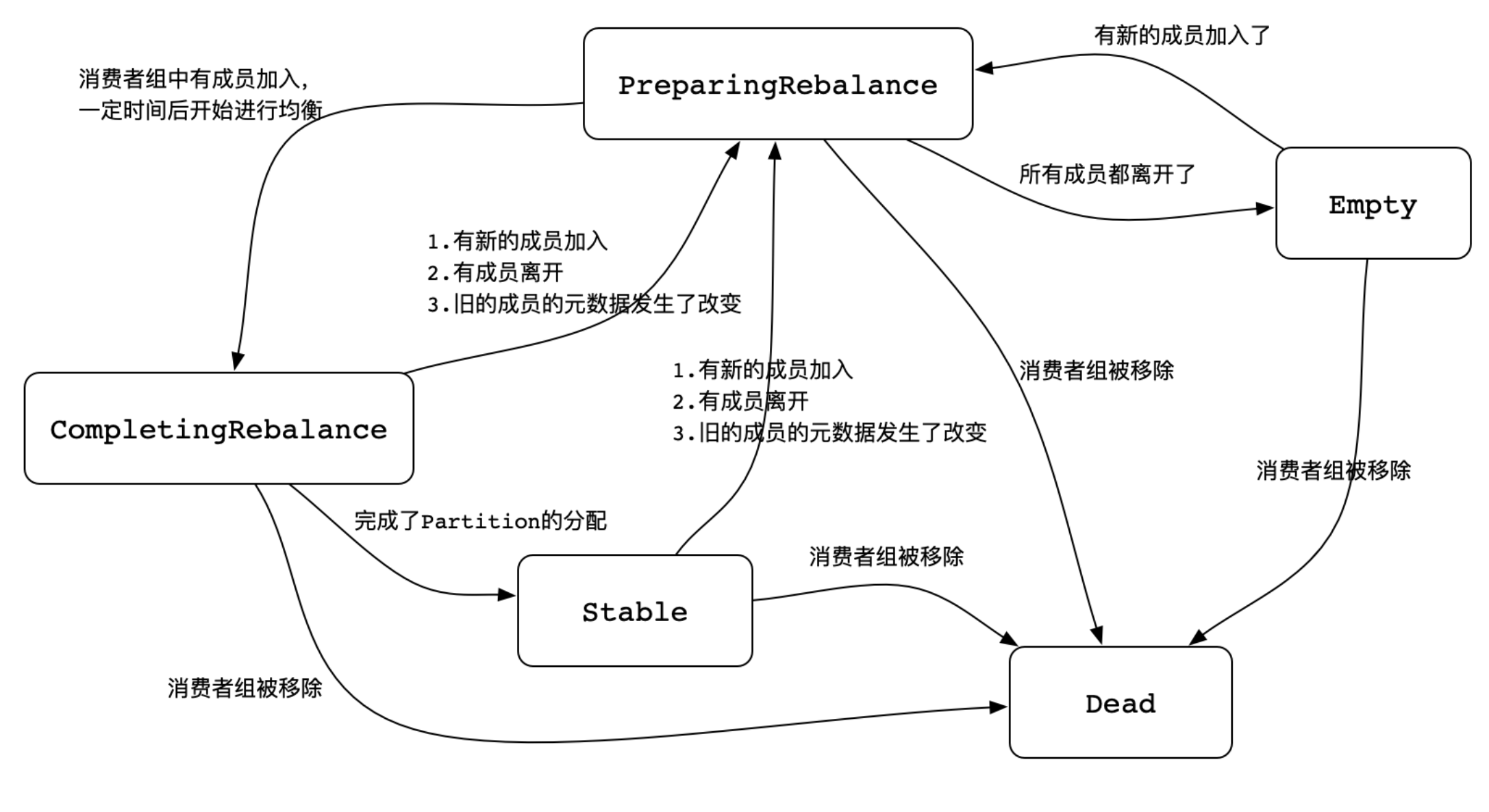
如果触发了poll超时,此时消费者客户端会退出ConsumerGroup,当再次poll的时候,会重新加入到ConsumerGroup,触发消费者再平衡策略 RebalanceGroup。而KafkaConsumer Client是不会帮我们重复poll的,需要我们自己在实现的消费逻辑中不停的调用poll方法。




























还没有评论,来说两句吧...