编写第一个MapReduce程序(WordCount)
一、数据格式准备
创建一个新的文件
【在master节点中】vim wordcount.txt
向其中放入内容并保存
hello,world,hadoophive,sqoop,flume,hellokitty,tom,jerry,worldhadoop
上传到HDFS
hdfs dfs -mkdir /wordcount/ #创建文件夹hdfs dfs -put wordcount.txt /wordcount/ #上传文件
二、创建Maven项目
pom.xml文件
<packaging>jar</packaging><dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.9.2</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.9.2</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>2.9.2</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>2.9.2</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>RELEASE</version></dependency></dependencies>
二、编写Mapper类
package com.ly;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class WordCountMapper extends Mapper<LongWritable, Text,Text,LongWritable> {//map方法就是将K1和V1转为K2和V2/* 参数: key :K1 行偏移量 value :V1 每一行的文本数据 context : 表示上下文对象 */@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//1:将一行的文本数据进行拆分String line = value.toString();String[] split = line.split(",");//2:遍历数组,组装K2和V2for (String word : split){//3:将K2和V2写入上下文context.write(new Text(word),new LongWritable(1));}}}
Mapper继承Mapper抽象类,重写map方法
三、编写Reducer类
package com.ly;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class WordCountReducer extends Reducer<Text, LongWritable,Text,LongWritable> {@Overrideprotected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {long count = 0;//1:遍历集合,将集合中的数字相加,得到V3for(LongWritable value : values){count += value.get();}//2:将K3和V3写入上下文中context.write(key, new LongWritable(count));}}
四、编写主类
package com.ly;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.conf.Configured;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;import org.apache.hadoop.util.Tool;import org.apache.hadoop.util.ToolRunner;public class JobMain extends Configured implements Tool {@Overridepublic int run(String[] strings) throws Exception {//创建一个job任务对象Job job = Job.getInstance(super.getConf(),JobMain.class.getSimpleName());//配置job任务对象job.setJarByClass(JobMain.class); //主类//第一步:指定文件的读取方式和读取路径job.setInputFormatClass(TextInputFormat.class);TextInputFormat.addInputPath(job,new Path("hdfs://192.168.239.164:9000/wordcount"));//第二步:设置Mapper类job.setMapperClass(WordCountMapper.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(LongWritable.class);job.setReducerClass(WordCountReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(LongWritable.class);job.setOutputFormatClass(TextOutputFormat.class);TextOutputFormat.setOutputPath(job,new Path("hdfs://192.168.239.164:9000/wordcount_out"));boolean b1 = job.waitForCompletion(true);return b1 ? 0 : 1;}public static void main(String[] args) throws Exception {Configuration configuration = new Configuration();int run = ToolRunner.run(configuration, new JobMain(), args);System.exit(run);}}
使用命令进行打包或IDEA的maven插件进行打包
mvn clean package
将生成的jar包上传至主机节点中的\opt目录下,放在\root路径下可能会引发权限读取问题。
五、验证结果
在上传的jar包所在路径执行以下命令:
hadoop jar wordcount-hadoop-1.0-SNAPSHOT.jar com.ly.JobMain
hadoop jar jar包名称 主类的完整类名
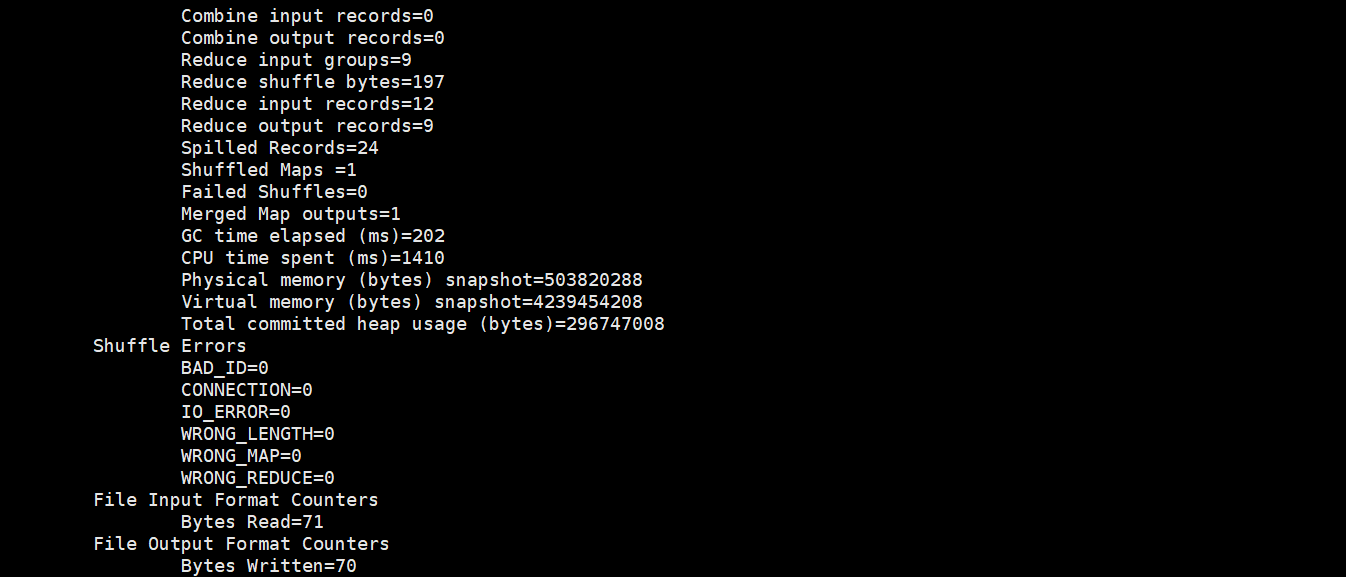
可以通过web页面查看并下载结果
通过浏览器访问master节点地址:http://192.168.239.164:50070/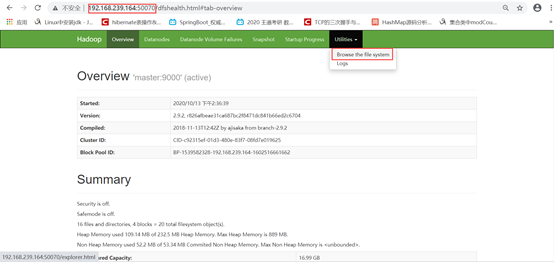
在选项栏选择Utilities→Browse the file system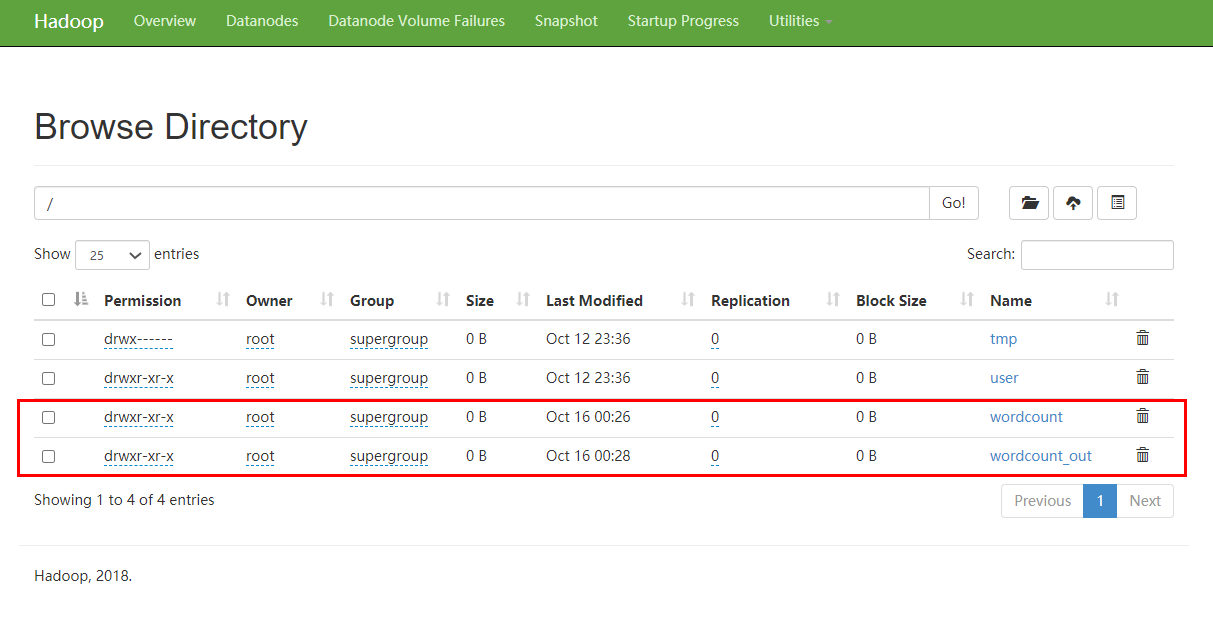
点击wordcount_count,查看结果输出文件夹中的结果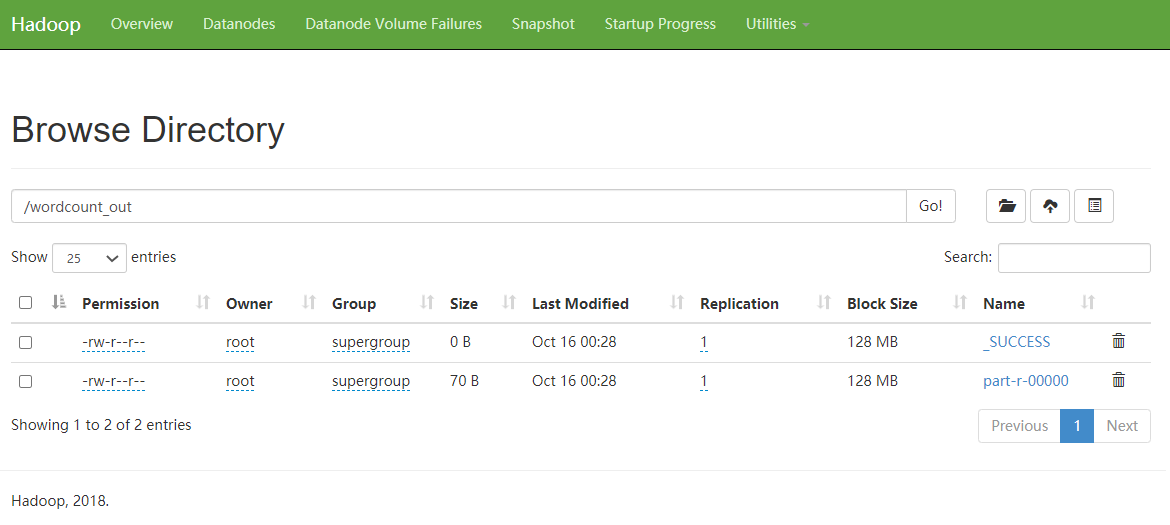
点击part-r-00000链接在弹出的窗口中可以选择下载结果文件
输出结果: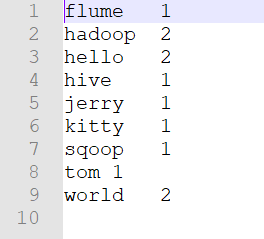




























还没有评论,来说两句吧...