MySQL 全表扫描
Server层
-- db1.t有200GBmysql -h$host -P$port -u$user -p$pwd -e "select * from db1.t" > $target_file
查询数据
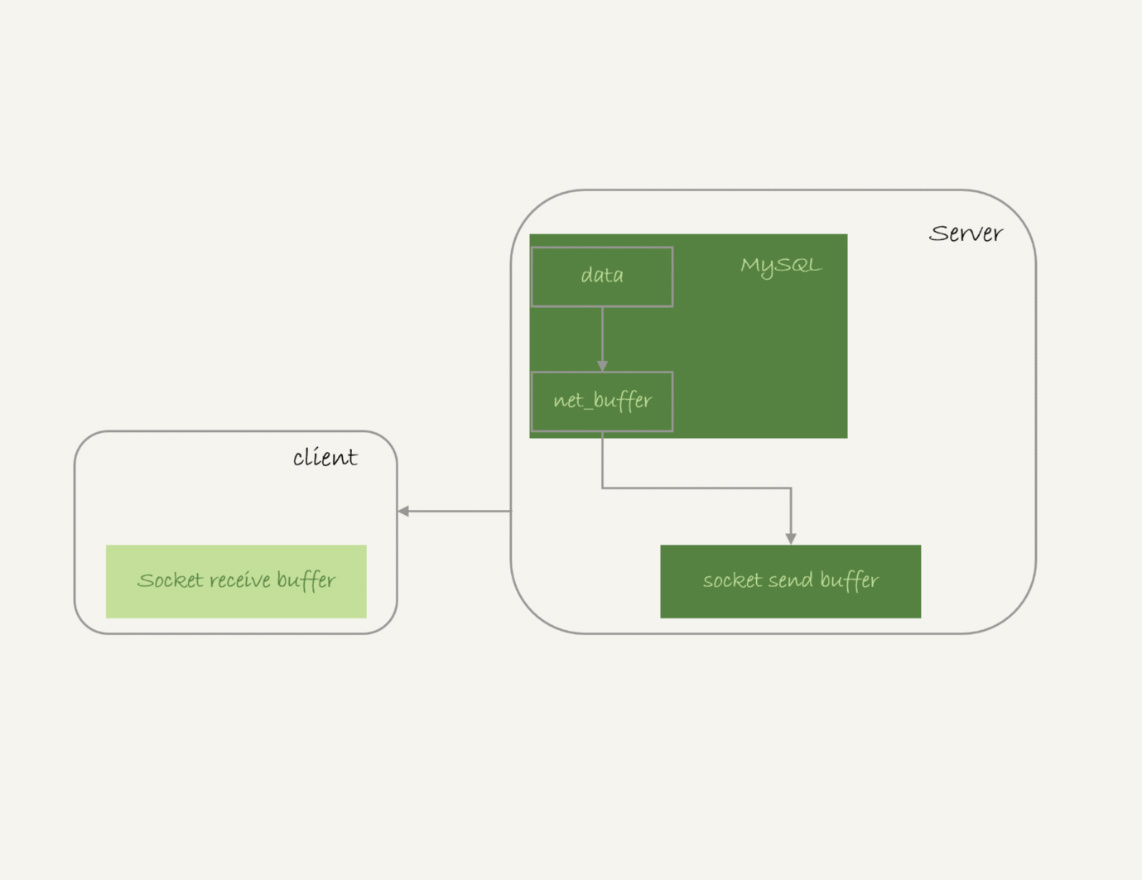
- InnoDB的数据是保存在主键索引上,全表扫描实际上是直接扫描表t的主键索引
- 获取一行,写到net_buffer中,默认为16K,控制参数为net_buffer_length
- 重复获取行,直到写满net_buffer,然后调用网络接口发出去
- 如果发送成功,就清空net_buffer,然后继续取下一行并写入net_buffer
- 如果发送函数返回EAGAIN或者WSAEWOULDBLOCK,表示本地网络栈socket send buffer写满。此时,进入等待,直到网络栈重新可写,再继续发送
- 一个查询在发送数据的过程中,占用MySQL内部的内存最大为net_buffer_length,因此不会达到200G
socket send buffer也不可能达到200G,如果socket send buffer被写满,就会暂停读取数据
— 16384 Bytes = 16 KB
mysql> SHOW VARIABLES LIKE ‘%net_buffer_length%’;
+—————————-+———-+
| Variable_name | Value |
+—————————-+———-+
| net_buffer_length | 16384 |
+—————————-+———-+
Sending to client
- MySQL是边读边发的,如果客户端接收慢,会导致MySQL服务端由于结果发不出去,事务的执行时间变长
下图为MySQL客户端不读取socket receive buffer中的内容的场景
- State为Sending to client,表示服务端的网络栈写满了
mysql —quick,会使用mysql_use_result方法,该方法会读取一行处理一行
- 假设每读出一行数据后要处理的逻辑很慢,就会导致客户端要过很久才会去取下一行数据
- 这时也会出现State为Sending to client的情况
- 对于正常的线上业务,如果单个查询返回的结果不多,推荐使用mysql_store_result接口
- 适当地调大net_buffer_length可能是个更优的解决方案

Sending data
State切换
- MySQL的查询语句在进入执行阶段后,首先把State设置为Sending data
- 然后,发送执行结果的列相关的信息(meta data)给客户端
- 再继续执行语句的流程,执行完成后,把State设置为空字符串
- 因此State为Sending data不等同于正在发送数据
样例
CREATE TABLE `t` (`id` int(11) NOT NULL,`c` int(11) NOT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;INSERT INTO t VALUES (1,1);
| session A | session B |
|---|---|
| BEGIN; | |
| SELECT FROM t WHERE id=1 FOR UPDATE; | |
| SELECT FROM t LOCK IN SHARE MODE;(Blocked) |
mysql> SHOW PROCESSLIST;+----+-----------------+-----------+------+---------+--------+------------------------+------------------------------------+| Id | User | Host | db | Command | Time | State | Info |+----+-----------------+-----------+------+---------+--------+------------------------+------------------------------------+| 4 | event_scheduler | localhost | NULL | Daemon | 713722 | Waiting on empty queue | NULL || 37 | root | localhost | test | Sleep | 35 | | NULL || 38 | root | localhost | test | Query | 15 | Sending data | SELECT * FROM t LOCK IN SHARE MODE || 39 | root | localhost | NULL | Query | 0 | starting | show processlist |+----+-----------------+-----------+------+---------+--------+------------------------+------------------------------------+
InnoDB层
- 内存的数据页是在Buffer Pool中管理的
- 作用:加速更新(WAL机制)+加速查询
内存命中率
- SHOW ENGINE INNODB STATUS中的Buffer pool hit rate 990 / 1000,表示命中率为99%
- Buffer Pool的大小由参数innodb_buffer_pool_size控制,一般设置为物理内存的60%~80%
Buffer Pool一般都会小于磁盘的数据量,InnoDB将采用LRU算法来淘汰数据页
— 134217728 Bytes = 128 MB
mysql> SHOW VARIABLES LIKE ‘%innodb_buffer_pool_size%’;
+————————————-+—————-+
| Variable_name | Value |
+————————————-+—————-+
| innodb_buffer_pool_size | 134217728 |
+————————————-+—————-+
基本LRU
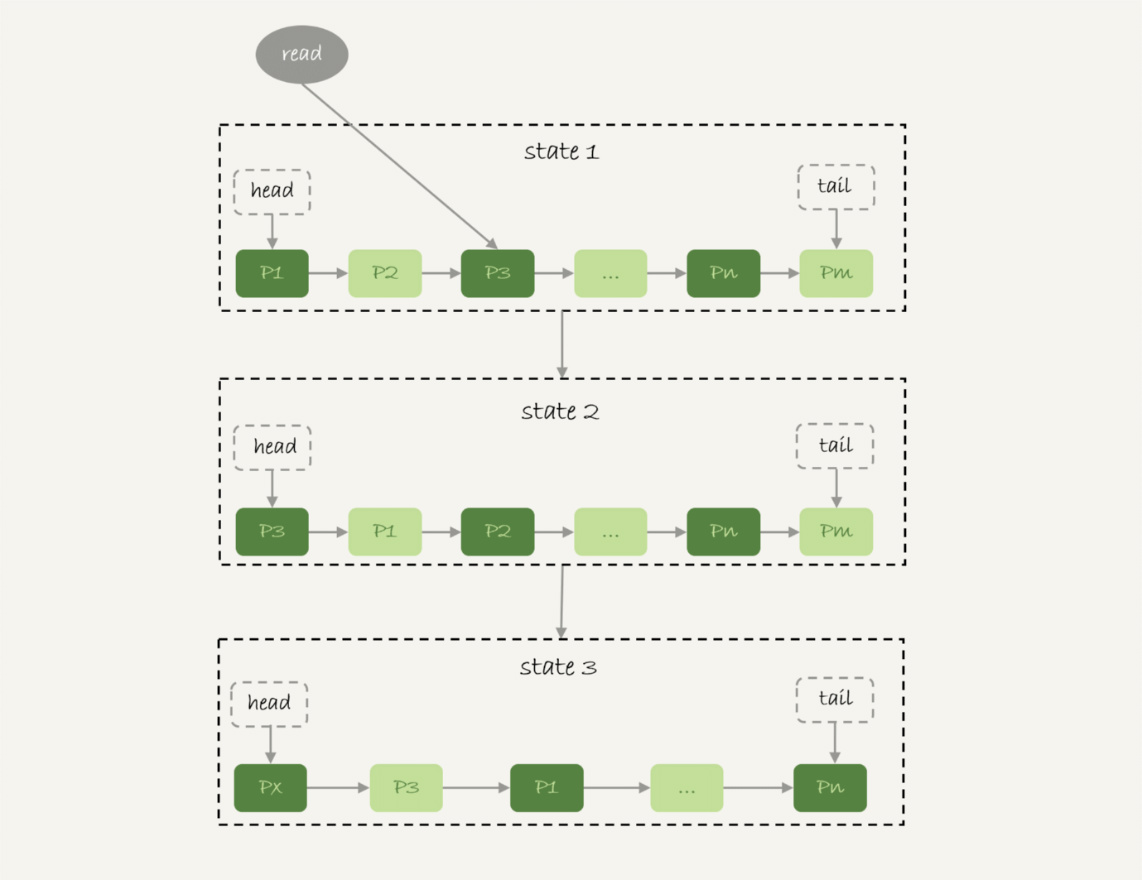
- InnoDB采用的LRU算法,是基于链表实现的
- State1,链表头部是P1,表示P1是最近刚刚被访问过的数据页
- State2,有一个读请求访问P3,P3被移动到链表的最前面
State3,要访问的数据页不在链表中,所以需要在Buffer Pool中新申请一个数据页Px,加到链表头部
- 但由于Buffer Pool已满,不能再申请新的数据页
- 于是会清空链表末尾Pm这个数据页的内存,存入Px的内容,并且放到链表头部
冷数据全表扫描
- 扫描一个200G的表,该表为历史数据表,平时没有什么业务访问它
- 按照基本LRU算法,就会把当前Buffer Pool里面的数据全部淘汰,存入扫描过程中访问到的数据页
- 此时,对外提供业务服务的库来说,Buffer Pool的命中率会急剧下降,磁盘压力增加,SQL语句响应变慢
- 因此InnoDB采用了改进的LRU算法
改进LRU
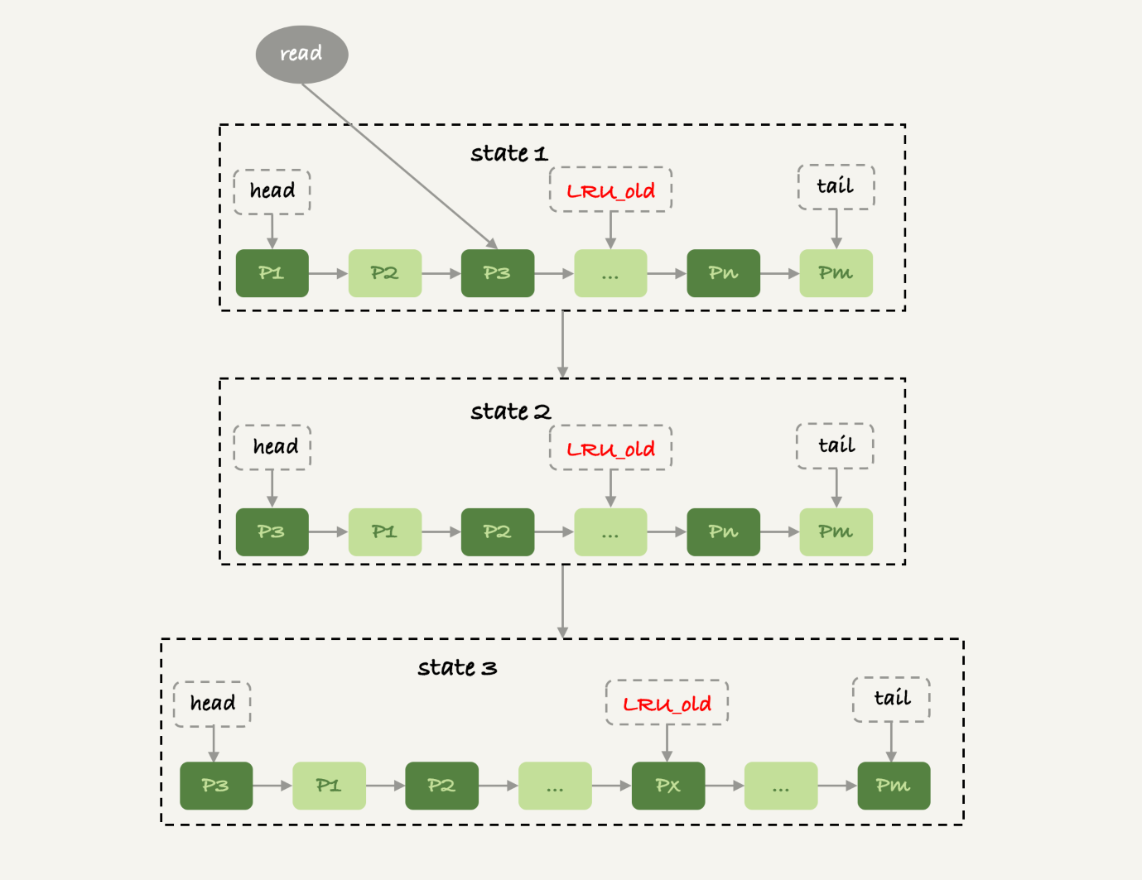
- 在InnoDB的实现上,按照5:3的比例把整个LRU链表分成young区和old区
- LRU_old指向old区的第一个位置,即靠近链表头部的5/8是young区,靠近链表尾部的3/8是old区
- State1,要访问数据页P3,由于P3在young区,与基本的LRU算法一样,将其移动到链表头部,变为State2
- 然后要访问一个不在当前链表的数据页,此时依然要淘汰数据页Pm,但新插入的数据页Px放在LRU_old
处于old区的数据页,每次被访问的时候都需要做以下判断
- 如果这个数据页在LRU链表中存在的时间超过了1S,就把它移动到链表头部,否则,位置不变
- 存在时间的值由参数innodb_old_blocks_time控制
该策略是为了处理类似全表扫描的操作而定制的
- 扫描过程中,需要新插入的数据页,都被放到old区
- 一个数据页会有多条记录,因此一个数据页会被访问多次。但由于是顺序扫描,数据页的第一次被访问和最后一次被访问的时间间隔不会超过1S,因此还是会留在old区
- 继续扫描,之前的数据页再也不会被访问到,因此也不会被移到young区,最终很快被淘汰
该策略最大的收益是在扫描大表的过程中,虽然用到了Buffer Pool,但对young区完全没有影响。保证了Buffer Pool响应正常业务的查询命中率
— 1000ms = 1s
mysql> SHOW VARIABLES LIKE ‘%innodb_old_blocks_time%’;
+————————————+———-+
| Variable_name | Value |
+————————————+———-+
| innodb_old_blocks_time | 1000 |
+————————————+———-+
INNODB STATUS
mysql> SHOW ENGINE INNODB STATUS\G;----------------------BUFFER POOL AND MEMORY------------------------ 137428992 Bytes = 131.0625 MBTotal large memory allocated 137428992Dictionary memory allocated 432277-- innodb_buffer_pool_size = 134217728 / 16 / 1024 / 1024 = 8192-- 6957 + 1223 = 8180 ≈ Buffer pool sizeBuffer pool size 8191Free buffers 6957Database pages 1223-- 1223 * 3 / 8 = 458.625 ≈ Old database pagesOld database pages 465Modified db pages 0Pending reads 0Pending writes: LRU 0, flush list 0, single page 0-- made young : old -> young-- not young : young -> oldPages made young 0, not young 00.00 youngs/s, 0.00 non-youngs/sPages read 1060, created 163, written 6660.00 reads/s, 0.00 creates/s, 0.00 writes/sNo buffer pool page gets since the last printoutPages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/sLRU len: 1223, unzip_LRU len: 0I/O sum[0]:cur[0], unzip sum[0]:cur[0]
参考资料
《MySQL实战45讲》




























还没有评论,来说两句吧...