大数据之CDH数仓(9) | 数仓之业务数仓搭建
目录
- 业务数据生成
- 建表语句
- 生成业务数据
- 业务数据导入数仓
- Sqoop定时导入脚本
- ODS层
- 创建订单表
- 创建订单详情表
- 创建商品表
- 创建用户表
- 创建商品一级分类表
- 创建商品二级分类表
- 创建商品三级分类表
- 创建支付流水表
- ODS层数据导入脚本
- DWD层
- 创建订单表
- 创建订单详情表
- 创建用户表
- 创建支付流水表
- 创建商品表(增加分类)
- DWD层数据导入脚本1)
- DWS层之用户行为宽表
- 创建用户行为宽表
- 用户行为数据宽表导入脚本
- ADS层(需求:GMV成交总额)
- 建表语句
- 数据导入脚本
- 数据导出脚本
业务数据生成
数据库生成脚本
链接:https://pan.baidu.com/s/1f-yAUqfte-T0Yk2mEBeAUw提取码:cwwx
建表语句
1)通过Navicat创建数据库gmall
2)设置数据库编码
3)导入建表语句(1建表脚本)
选择->1建表脚本.sql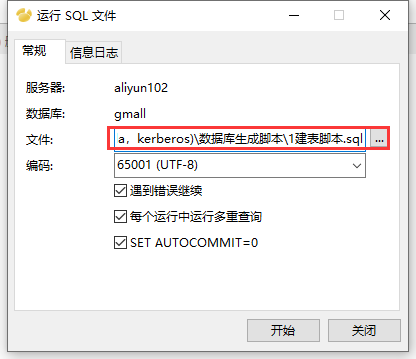
4)重复步骤3的导入方式,依次导入:2商品分类数据插入脚本、3函数脚本、4存储过程脚本。
生成业务数据
1)生成业务数据函数说明
init_data ( do_date_string VARCHAR(20) , order_incr_num INT, user_incr_num INT , sku_num INT , if_truncate BOOLEAN ):
参数一:do_date_string生成数据日期
参数二:order_incr_num订单id个数
参数三:user_incr_num用户id个数
参数四:sku_num商品sku个数
参数五:if_truncate是否删除数据
2)案例测试:
(1)需求:生成日期2019年2月10日数据、订单1000个、用户200个、商品sku300个、删除原始数据。
(2)查询生成数据结果
CALL init_data('2019-02-10',1000,200,300,TRUE);
业务数据导入数仓

Sqoop定时导入脚本
1)在/root/bin目录下创建脚本sqoop_import.sh
[root@hadoop102 bin]$ vim sqoop_import.sh
在脚本中填写如下内容
#!/bin/bashexport HADOOP_USER_NAME=hivedb_date=$2echo $db_datedb_name=gmallimport_data() {sqoop import \--connect jdbc:mysql://hadoop102:3306/$db_name \--username root \--password Yy8266603@ \--target-dir /origin_data/$db_name/db/$1/$db_date \--delete-target-dir \--num-mappers 1 \--fields-terminated-by "\t" \--query "$2"' and $CONDITIONS;'}import_sku_info(){import_data "sku_info" "select id, spu_id, price, sku_name, sku_desc, weight, tm_id, category3_id, create_time from sku_info where 1=1"}import_user_info(){import_data "user_info" "select id, name, birthday, gender, email, user_level, create_time from user_info where 1=1"}import_base_category1(){import_data "base_category1" "select id, name from base_category1 where 1=1"}import_base_category2(){import_data "base_category2" "select id, name, category1_id from base_category2 where 1=1"}import_base_category3(){import_data "base_category3" "select id, name, category2_id from base_category3 where 1=1"}import_order_detail(){import_data "order_detail" "select od.id, order_id, user_id, sku_id, sku_name, order_price, sku_num, o.create_time from order_info o , order_detail od where o.id=od.order_id and DATE_FORMAT(create_time,'%Y-%m-%d')='$db_date'"}import_payment_info(){import_data "payment_info" "select id, out_trade_no, order_id, user_id, alipay_trade_no, total_amount, subject, payment_type, payment_time from payment_info where DATE_FORMAT(payment_time,'%Y-%m-%d')='$db_date'"}import_order_info(){import_data "order_info" "select id, total_amount, order_status, user_id, payment_way, out_trade_no, create_time, operate_time from order_info where (DATE_FORMAT(create_time,'%Y-%m-%d')='$db_date' or DATE_FORMAT(operate_time,'%Y-%m-%d')='$db_date')"}case $1 in"base_category1")import_base_category1;;"base_category2")import_base_category2;;"base_category3")import_base_category3;;"order_info")import_order_info;;"order_detail")import_order_detail;;"sku_info")import_sku_info;;"user_info")import_user_info;;"payment_info")import_payment_info;;"all")import_base_category1import_base_category2import_base_category3import_order_infoimport_order_detailimport_sku_infoimport_user_infoimport_payment_info;;esac
2)增加脚本执行权限
[root@hadoop102 bin]$ chmod 777 sqoop_import.sh
3)执行脚本导入数据
[root@hadoop102 bin]# sqoop_import.sh all 2019-02-10
4)修改/orgin_data/gmall/db路径的访问权限
[root@hadoop102 bin]# sudo -u hdfs hadoop fs -chmod -R 777 /origin_data/gmall/db
ODS层
完全仿照业务数据库中的表字段,一模一样的创建ODS层对应表。
创建订单表
drop table if exists ods_order_info;create external table ods_order_info (`id` string COMMENT '订单编号',`total_amount` decimal(10,2) COMMENT '订单金额',`order_status` string COMMENT '订单状态',`user_id` string COMMENT '用户id' ,`payment_way` string COMMENT '支付方式',`out_trade_no` string COMMENT '支付流水号',`create_time` string COMMENT '创建时间',`operate_time` string COMMENT '操作时间') COMMENT '订单表'PARTITIONED BY ( `dt` string)row format delimited fields terminated by '\t'location '/warehouse/gmall/ods/ods_order_info/';
创建订单详情表
drop table if exists ods_order_detail;create external table ods_order_detail(`id` string COMMENT '订单编号',`order_id` string COMMENT '订单号',`user_id` string COMMENT '用户id' ,`sku_id` string COMMENT '商品id',`sku_name` string COMMENT '商品名称',`order_price` string COMMENT '商品价格',`sku_num` string COMMENT '商品数量',`create_time` string COMMENT '创建时间') COMMENT '订单明细表'PARTITIONED BY ( `dt` string)row format delimited fields terminated by '\t'location '/warehouse/gmall/ods/ods_order_detail/';
创建商品表
drop table if exists ods_sku_info;create external table ods_sku_info(`id` string COMMENT 'skuId',`spu_id` string COMMENT 'spuid',`price` decimal(10,2) COMMENT '价格' ,`sku_name` string COMMENT '商品名称',`sku_desc` string COMMENT '商品描述',`weight` string COMMENT '重量',`tm_id` string COMMENT '品牌id',`category3_id` string COMMENT '品类id',`create_time` string COMMENT '创建时间') COMMENT '商品表'PARTITIONED BY ( `dt` string)row format delimited fields terminated by '\t'location '/warehouse/gmall/ods/ods_sku_info/';
创建用户表
drop table if exists ods_user_info;create external table ods_user_info(`id` string COMMENT '用户id',`name` string COMMENT '姓名',`birthday` string COMMENT '生日' ,`gender` string COMMENT '性别',`email` string COMMENT '邮箱',`user_level` string COMMENT '用户等级',`create_time` string COMMENT '创建时间') COMMENT '用户信息'PARTITIONED BY ( `dt` string)row format delimited fields terminated by '\t'location '/warehouse/gmall/ods/ods_user_info/';
创建商品一级分类表
drop table if exists ods_base_category1;create external table ods_base_category1(`id` string COMMENT 'id',`name` string COMMENT '名称') COMMENT '商品一级分类'PARTITIONED BY ( `dt` string)row format delimited fields terminated by '\t'location '/warehouse/gmall/ods/ods_base_category1/';
创建商品二级分类表
drop table if exists ods_base_category2;create external table ods_base_category2(`id` string COMMENT ' id',`name` string COMMENT '名称',category1_id string COMMENT '一级品类id') COMMENT '商品二级分类'PARTITIONED BY ( `dt` string)row format delimited fields terminated by '\t'location '/warehouse/gmall/ods/ods_base_category2/';
创建商品三级分类表
drop table if exists ods_base_category3;create external table ods_base_category3(`id` string COMMENT ' id',`name` string COMMENT '名称',category2_id string COMMENT '二级品类id') COMMENT '商品三级分类'PARTITIONED BY ( `dt` string)row format delimited fields terminated by '\t'location '/warehouse/gmall/ods/ods_base_category3/';
创建支付流水表
drop table if exists `ods_payment_info`;create external table `ods_payment_info`(`id` bigint COMMENT '编号',`out_trade_no` string COMMENT '对外业务编号',`order_id` string COMMENT '订单编号',`user_id` string COMMENT '用户编号',`alipay_trade_no` string COMMENT '支付宝交易流水编号',`total_amount` decimal(16,2) COMMENT '支付金额',`subject` string COMMENT '交易内容',`payment_type` string COMMENT '支付类型',`payment_time` string COMMENT '支付时间') COMMENT '支付流水表'PARTITIONED BY ( `dt` string)row format delimited fields terminated by '\t'location '/warehouse/gmall/ods/ods_payment_info/';
ODS层数据导入脚本
1)在/root/bin目录下创建脚本ods_db.sh
[root@hadoop102 bin]$ vim ods_db.sh
在脚本中填写如下内容
#!/bin/bashAPP=gmall# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天if [ -n "$1" ] ;thendo_date=$1elsedo_date=`date -d "-1 day" +%F`fisql=" load data inpath '/origin_data/$APP/db/order_info/$do_date' OVERWRITE into table "$APP".ods_order_info partition(dt='$do_date'); load data inpath '/origin_data/$APP/db/order_detail/$do_date' OVERWRITE into table "$APP".ods_order_detail partition(dt='$do_date'); load data inpath '/origin_data/$APP/db/sku_info/$do_date' OVERWRITE into table "$APP".ods_sku_info partition(dt='$do_date'); load data inpath '/origin_data/$APP/db/user_info/$do_date' OVERWRITE into table "$APP".ods_user_info partition(dt='$do_date'); load data inpath '/origin_data/$APP/db/payment_info/$do_date' OVERWRITE into table "$APP".ods_payment_info partition(dt='$do_date'); load data inpath '/origin_data/$APP/db/base_category1/$do_date' OVERWRITE into table "$APP".ods_base_category1 partition(dt='$do_date'); load data inpath '/origin_data/$APP/db/base_category2/$do_date' OVERWRITE into table "$APP".ods_base_category2 partition(dt='$do_date'); load data inpath '/origin_data/$APP/db/base_category3/$do_date' OVERWRITE into table "$APP".ods_base_category3 partition(dt='$do_date'); "beeline -u "jdbc:hive2://hadoop102:10000/" -n hive -e "$sql"
2)增加脚本执行权限
[root@hadoop102 bin]$ chmod +x ods_db.sh
3)采用脚本导入数据
[root@hadoop102 bin]$ ods_db.sh 2019-02-10
DWD层
对ODS层数据进行判空过滤。对商品分类表进行维度退化(降维)。
创建订单表
drop table if exists dwd_order_info;create external table dwd_order_info (`id` string COMMENT '',`total_amount` decimal(10,2) COMMENT '',`order_status` string COMMENT ' 1 2 3 4 5',`user_id` string COMMENT 'id' ,`payment_way` string COMMENT '',`out_trade_no` string COMMENT '',`create_time` string COMMENT '',`operate_time` string COMMENT '')PARTITIONED BY ( `dt` string)stored as parquetlocation '/warehouse/gmall/dwd/dwd_order_info/';
创建订单详情表
drop table if exists dwd_order_detail;create external table dwd_order_detail(`id` string COMMENT '',`order_id` decimal(10,2) COMMENT '',`user_id` string COMMENT 'id' ,`sku_id` string COMMENT 'id',`sku_name` string COMMENT '',`order_price` string COMMENT '',`sku_num` string COMMENT '',`create_time` string COMMENT '')PARTITIONED BY (`dt` string)stored as parquetlocation '/warehouse/gmall/dwd/dwd_order_detail/';
创建用户表
drop table if exists dwd_user_info;create external table dwd_user_info(`id` string COMMENT 'id',`name` string COMMENT '',`birthday` string COMMENT '' ,`gender` string COMMENT '',`email` string COMMENT '',`user_level` string COMMENT '',`create_time` string COMMENT '')PARTITIONED BY (`dt` string)stored as parquetlocation '/warehouse/gmall/dwd/dwd_user_info/';
创建支付流水表
drop table if exists `dwd_payment_info`;create external table `dwd_payment_info`(`id` bigint COMMENT '',`out_trade_no` string COMMENT '',`order_id` string COMMENT '',`user_id` string COMMENT '',`alipay_trade_no` string COMMENT '',`total_amount` decimal(16,2) COMMENT '',`subject` string COMMENT '',`payment_type` string COMMENT '',`payment_time` string COMMENT '')PARTITIONED BY ( `dt` string)stored as parquetlocation '/warehouse/gmall/dwd/dwd_payment_info/';
创建商品表(增加分类)
drop table if exists dwd_sku_info;create external table dwd_sku_info(`id` string COMMENT 'skuId',`spu_id` string COMMENT 'spuid',`price` decimal(10,2) COMMENT '' ,`sku_name` string COMMENT '',`sku_desc` string COMMENT '',`weight` string COMMENT '',`tm_id` string COMMENT 'id',`category3_id` string COMMENT '1id',`category2_id` string COMMENT '2id',`category1_id` string COMMENT '3id',`category3_name` string COMMENT '3',`category2_name` string COMMENT '2',`category1_name` string COMMENT '1',`create_time` string COMMENT '')PARTITIONED BY ( `dt` string)stored as parquetlocation '/warehouse/gmall/dwd/dwd_sku_info/';
DWD层数据导入脚本1)
在/root/bin目录下创建脚本dwd_db.sh
[root@hadoop102 bin]$ vim dwd_db.sh
在脚本中填写如下内容
#!/bin/bash# 定义变量方便修改APP=gmall# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天if [ -n "$1" ] ;thendo_date=$1elsedo_date=`date -d "-1 day" +%F`fisql=" set hive.exec.dynamic.partition.mode=nonstrict; insert overwrite table "$APP".dwd_order_info partition(dt) select * from "$APP".ods_order_info where dt='$do_date' and id is not null; insert overwrite table "$APP".dwd_order_detail partition(dt) select * from "$APP".ods_order_detail where dt='$do_date' and id is not null; insert overwrite table "$APP".dwd_user_info partition(dt) select * from "$APP".ods_user_info where dt='$do_date' and id is not null; insert overwrite table "$APP".dwd_payment_info partition(dt) select * from "$APP".ods_payment_info where dt='$do_date' and id is not null; insert overwrite table "$APP".dwd_sku_info partition(dt) select sku.id, sku.spu_id, sku.price, sku.sku_name, sku.sku_desc, sku.weight, sku.tm_id, sku.category3_id, c2.id category2_id , c1.id category1_id, c3.name category3_name, c2.name category2_name, c1.name category1_name, sku.create_time, sku.dt from "$APP".ods_sku_info sku join "$APP".ods_base_category3 c3 on sku.category3_id=c3.id join "$APP".ods_base_category2 c2 on c3.category2_id=c2.id join "$APP".ods_base_category1 c1 on c2.category1_id=c1.id where sku.dt='$do_date' and c2.dt='$do_date' and c3.dt='$do_date' and c1.dt='$do_date' and sku.id is not null; "beeline -u "jdbc:hive2://hadoop102:10000/" -n hive -e "$sql"
2)增加脚本执行权限
[root@hadoop102 bin]$ chmod 777 dwd_db.sh
3)采用脚本导入数据
[root@hadoop102 bin]$ dwd_db.sh 2019-02-10
DWS层之用户行为宽表
1)为什么要建宽表
需求目标,把每个用户单日的行为聚合起来组成一张多列宽表,以便之后关联用户维度信息后进行,不同角度的统计分析。
创建用户行为宽表
drop table if exists dws_user_action;create external table dws_user_action(user_id string comment '用户 id',order_count bigint comment '下单次数 ',order_amount decimal(16,2) comment '下单金额 ',payment_count bigint comment '支付次数',payment_amount decimal(16,2) comment '支付金额 ') COMMENT '每日用户行为宽表'PARTITIONED BY (`dt` string)stored as parquetlocation '/warehouse/gmall/dws/dws_user_action/'tblproperties ("parquet.compression"="snappy");
用户行为数据宽表导入脚本
1)在/root/bin目录下创建脚本dws_db_wide.sh
[root@hadoop102 bin]$ vim dws_db_wide.sh
在脚本中填写如下内容
#!/bin/bash# 定义变量方便修改APP=gmall# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天if [ -n "$1" ] ;thendo_date=$1elsedo_date=`date -d "-1 day" +%F`fisql=" with tmp_order as ( select user_id, count(*) order_count, sum(oi.total_amount) order_amount from "$APP".dwd_order_info oi where date_format(oi.create_time,'yyyy-MM-dd')='$do_date' group by user_id ) , tmp_payment as ( select user_id, sum(pi.total_amount) payment_amount, count(*) payment_count from "$APP".dwd_payment_info pi where date_format(pi.payment_time,'yyyy-MM-dd')='$do_date' group by user_id ) insert overwrite table "$APP".dws_user_action partition(dt='$do_date') select user_actions.user_id, sum(user_actions.order_count), sum(user_actions.order_amount), sum(user_actions.payment_count), sum(user_actions.payment_amount) from ( select user_id, order_count, order_amount, 0 payment_count, 0 payment_amount from tmp_order union all select user_id, 0 order_count, 0 order_amount, payment_count, payment_amount from tmp_payment ) user_actions group by user_id; "beeline -u "jdbc:hive2://hadoop102:10000/" -n hive -e "$sql"
2)增加脚本执行权限
[root@hadoop102 bin]# chmod 777 dws_db_wide.sh
3)增加脚本执行权限
[root@hadoop102 bin]# dws_db_wide.sh 2019-02-10
ADS层(需求:GMV成交总额)
建表语句
drop table if exists ads_gmv_sum_day;create external table ads_gmv_sum_day(`dt` string COMMENT '统计日期',`gmv_count` bigint COMMENT '当日gmv订单个数',`gmv_amount` decimal(16,2) COMMENT '当日gmv订单总金额',`gmv_payment` decimal(16,2) COMMENT '当日支付金额') COMMENT 'GMV'row format delimited fields terminated by '\t'location '/warehouse/gmall/ads/ads_gmv_sum_day/';
数据导入脚本
1)在/root/bin目录下创建脚本ads_db_gmv.sh
[root@hadoop102 bin]$ vim ads_db_gmv.sh
在脚本中填写如下内容
#!/bin/bash# 定义变量方便修改APP=gmall# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天if [ -n "$1" ] ;thendo_date=$1elsedo_date=`date -d "-1 day" +%F`fisql=" insert into table "$APP".ads_gmv_sum_day select '$do_date' dt, sum(order_count) gmv_count, sum(order_amount) gmv_amount, sum(payment_amount) payment_amount from "$APP".dws_user_action where dt ='$do_date' group by dt; "beeline -u "jdbc:hive2://hadoop102:10000/" -n hive -e "$sql"
2)增加脚本执行权限
[root@hadoop102 bin]$ chmod 777 ads_db_gmv.sh
3)执行脚本
[root@hadoop102 bin]$ ads_db_gmv.sh 2019-02-10
数据导出脚本
1)在MySQL中创建ads_gmv_sum_day表
DROP TABLE IF EXISTS ads_gmv_sum_day;CREATE TABLE ads_gmv_sum_day(`dt` varchar(200) DEFAULT NULL COMMENT '统计日期',`gmv_count` bigint(20) DEFAULT NULL COMMENT '当日gmv订单个数',`gmv_amount` decimal(16, 2) DEFAULT NULL COMMENT '当日gmv订单总金额',`gmv_payment` decimal(16, 2) DEFAULT NULL COMMENT '当日支付金额') ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '每日活跃用户数量' ROW_FORMAT = Dynamic;
2)在/root/bin目录下创建脚本sqoop_export.sh
[root@hadoop102 bin]$ vim sqoop_export.sh
在脚本中填写如下内容
#!/bin/bashexport HADOOP_USER_NAME=hivedb_name=gmallexport_data() {sqoop export \--connect "jdbc:mysql://hadoop102:3306/${db_name}?useUnicode=true&characterEncoding=utf-8" \--username root \--password Atguigu.123456 \--table $1 \--num-mappers 1 \--export-dir /warehouse/$db_name/ads/$1 \--input-fields-terminated-by "\t" \--update-mode allowinsert \--update-key $2 \--input-null-string '\\N' \--input-null-non-string '\\N'}case $1 in"ads_gmv_sum_day")export_data "ads_gmv_sum_day" "dt";;"all")export_data "ads_gmv_sum_day" "dt";;esac
3)增加脚本执行权限
[root@hadoop102 bin]$ chmod 777 sqoop_export.sh
4)执行脚本导入数据
[root@hadoop102 bin]$ sqoop_export.sh all
5)在SQLyog查看导出数据
select * from ads_gmv_sum_day


































还没有评论,来说两句吧...